![[MMSEARCH] 整合图像和文本的多模态搜索系统](https://aisholar.s3.ap-northeast-1.amazonaws.com/media/October2024/mmsearch_1_.png)
[MMSEARCH] 整合图像和文本的多模态搜索系统
三个要点
✔️ MMSEARCH-ENGINE提出了一种整合图像和文本检索的多模态搜索系统
✔️ 实验表明,GPT-4o具有出色的检索准确性,超过了传统的搜索引擎
✔️ Requery 和 Rerank 任务的改进是进一步提高性能的关键
MMSearch: Benchmarking the Potential of Large Models as Multi-modal Search Engines
written by Dongzhi Jiang, Renrui Zhang, Ziyu Guo, Yanmin Wu, Jiayi Lei, Pengshuo Qiu, Pan Lu, Zehui Chen, Guanglu Song, Peng Gao, Yu Liu, Chunyuan Li, Hongsheng Li
(Submitted on 19 Sep 2024)
Comments: Project Page: this https URL
Subjects: Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI); Computation and Language (cs.CL); Information Retrieval (cs.IR)
code:
本文所使用的图片要么来自论文、介绍性幻灯片,要么是参考这些图片制作的。
背景
传统的搜索引擎主要只处理文本,因此很难充分搜索和处理图像与文本相结合的信息。例如,网站通常会显示图像和文本的复杂交集,但目前的人工智能搜索引擎无法有效处理此类内容。
为了解决这个问题,研究人员开发了一个名为 MMSEARCH-ENGINE 的系统。该系统旨在提供可应用于任何 LMM 的多模式搜索功能。它能让 LMM 响应更复杂的搜索要求,利用图像信息和文本搜索。实际的网络搜索过程涉及一系列步骤,包括将用户问题转换成更适合搜索引擎的格式,对搜索结果进行重新评估和排序,最后以摘要的形式呈现这些信息。
该系统的所有步骤都由 LMM 完成,其最终目的是提供更准确、更相关的信息。
建议方法
本文提出的方法是 MMSEARCH-ENGINE,它侧重于将 LMM 作为多模态搜索引擎。
MMSEARCH-ENGINE 是一个为 LMM 增加多模态搜索功能而开发的框架,可以同时处理图像和文本信息。该系统首先要将用户的查询(搜索请求)重新转换(Requery)为合适的格式。在很多情况下,用户输入的查询可能并不适合搜索引擎,因此 LMM 会对查询进行优化。接下来,对搜索结果中最相关的网站进行重新排名(Rerank),最后根据这些信息进行总结(Summarisation)。
该 MMSEARCH-ENGINE 能够整合并处理视觉和文本信息,特别是通过使用 Google Lens 从图像中提取信息,以及通过截取网站截图并将其传递给 LMM,从而使视觉线索也成为搜索过程的一部分。这样,视觉线索也成为搜索过程的一部分。这样,即使用户的查询包括图片,也能根据图片内容提供更准确的搜索结果。
此外,还建立了一个基准 MMSEARCH 来评估该方法。它使用人工收集的 300 个查询来衡量 LMM 的多模态搜索能力。这些查询涵盖了最新新闻和专业知识领域,每个查询都包含图像和文本信息相结合的复杂内容。
试验
本文使用多个大规模多模态模型(LMM)进行了实验评估,以验证所提出的 MMSEARCH-ENGINE 方法。实验使用封闭式 LMM(如 GPT-4V 和 Claude 3.5 Sonnet)和开源 LMM(如 Qwen2-VL-7B 和 LLaVA-OneVision)测量了所提方法的性能。
实验涉及三大核心任务。它们分别是 "Requery"、"Rerank "和 "Summarisation"。首先,"Requery "任务将用户的查询转换成适合搜索引擎的格式,然后是 "Rerank "任务,即根据从多个网站检索到的信息选择最相关的信息。最后,执行总结任务,从选定的信息中提取适当的答案。
除了这三项任务外,还进行了 "端到端 "评估,该评估贯穿所有步骤。端到端 "任务衡量的是整个系统为用户查询提供结果的准确度,模拟的场景与实际使用情况最为接近。
结果,GPT-4o 在闭源 LMM 中表现最佳,而开源的 Qwen2-VL-72B 也表现出色。特别值得注意的是,所提出的方法的性能优于商业人工智能搜索引擎 Perplexity Pro。这表明,与现有系统相比,MMSEARCH-ENGINE 具有更出色的多模态搜索能力。
实验结果还凸显了模型在 Requery 和 Rerank 部分的弱点,表明这些任务需要改进,尤其是开源模型。另一方面,许多模型在 "总结 "任务中表现出了相对较高的性能,这证明了它们总结提取信息的能力很强。
结论
本文的结论表明,提议的 MMSEARCH-ENGINE 在当前的多模态搜索中大有可为。大规模多模态模型(LMM)的使用证实了它有能力有效处理包括图像和文本在内的复杂查询。
所提方法的另一个缺点是,目前的 LMM 在 Requery 和 Rerank 任务中没有足够的准确性。提高这些任务的性能是未来的挑战,而进一步的改进将大大提高 LMM 在多模态搜索中的性能。
图表说明

该图显示了多学科问题及其答案,并提供了一个如何评估 MMSearch 系统功能的示例。
图中的问题主要与新闻和知识有关,并按类别进行了细分。首先,与新闻相关的问题分为六类:金融、体育、科学、娱乐、综合和错误假设。在每个类别中,都给出了具体的例题及其答案。例如,在 "金融 "部分,有一个关于公司股价的问题。
接下来,知识部分分为六个类别:天文、汽车、时尚、艺术、建筑和动画。其中,"时尚 "板块询问服装的发布日期。
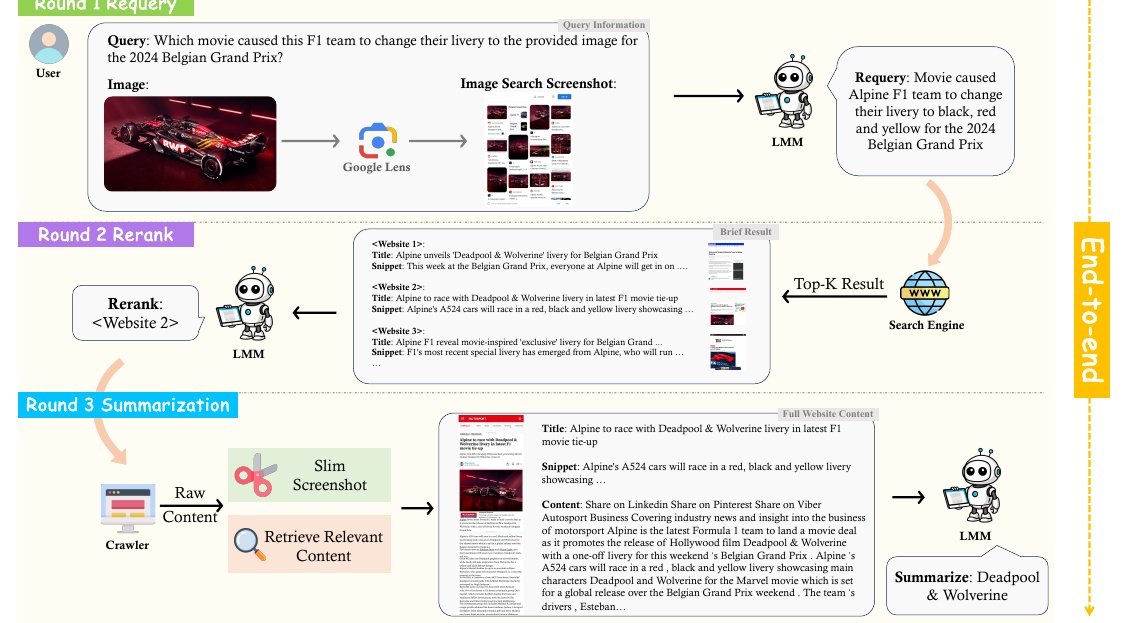
本图显示了检索 F1 车队重新命名变更信息的程序。内容包括
首先,用户问:"是什么电影导致 F1 车队在 2024 年比利时大奖赛上改变了这张图片中提供的涂装?问题已提出。用户使用相关图片,然后通过 Google Lens 搜索相关信息。
在下一步 "Requery"(请求重构)中,LMM(大型多模态模型)根据图像和检索到的信息在搜索引擎中创建一个新的搜索查询:"为 2024 年比利时大奖赛将遐想变为黑色、红色和黄色的电影"。然后,最相关的网站被列为搜索引擎的前 K 位。
在 "重新排名 "步骤中,LMM 会从列出的网站中选择能提供最佳信息的网站。在本例中,"网站 2 "被选中。
最后,在 "总结 "步骤中,LMM 对所选网站的细节进行分析,总结出电影《死侍与金刚狼》引起了遐想的变化。
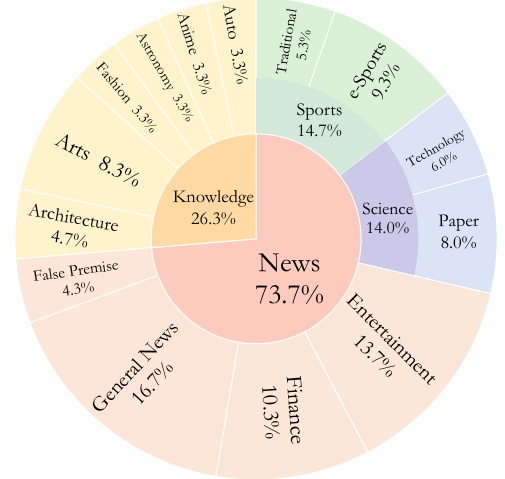
该图显示了论文所评估的数据集 MMSEARCH 的类别和子类别的百分比。其中 73.7% 属于 "新闻 "类别,26.3% 属于 "知识 "类别。
新闻 "类别的细分更为详细,"综合新闻 "占 16.7%,"体育 "占 14.7%,其中包括传统体育和电子竞技。娱乐 "占 13.7%,是许多人感兴趣的话题。此外,"财经 "占 10.3%,包含大量经济信息。科学 "和 "技术 "分别占 14.0% 和 6.0%,也包含了丰富的科技新闻。论文 "也包含学术信息,占 8.0%。
在 "知识 "类别中,"艺术 "和 "建筑 "分别占 8.3% 和 4.7%,涉及艺术和建筑的具体知识。错误前提 "占 4.3%,涉及涉及错误前提的问题。天文学"、"动漫"、"汽车 "和 "时尚 "各占 3.3%,涉及这些领域的知识。
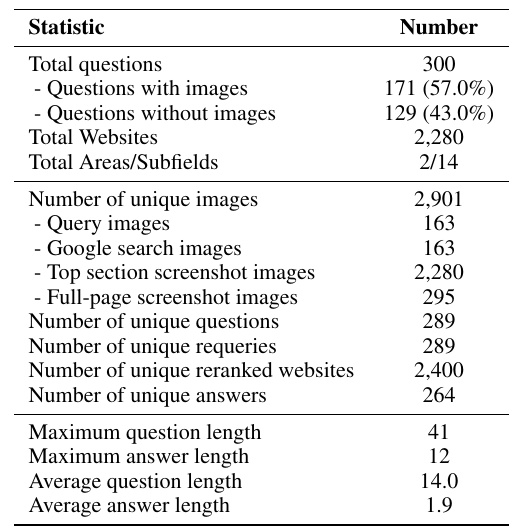
本表介绍了一项研究中数据集的统计数据。总共包含 300 个问题,其中 171 个有图片,129 个是纯文字问题。与每个问题相关的网站数量为 2280 个。数据集还分为 14 个领域,但只有两个重点领域。
共有 2,901 张独特的图片,其中 163 张用于查询,163 张来自谷歌搜索,2,280 张为网站顶部截图。此外,还有 295 张整个网页的截图。
共有 289 个独特的问题,以及 289 个独特的重新查询。有 2,400 个重新排名的网站,264 个独特的答案。最大问题长度为 41 个字,最大答案长度为 12 个字。平均问题长度为 14 个字,平均答案长度为 1.9 个字。

该图给出了与本文相关的数据集概览。首先,问题总数为 300 个,其中 57% 有图片,43% 无图片。使用了 2280 个网站。数据分为两大领域,每个领域包括 14 个子领域:新闻和知识。新闻占 73.7%,具体包括综合新闻、娱乐、体育、钱包、科技等。知识占 26.3%。
在图片方面,共有 2,901 张独特图片,其中 163 张为查询图片,163 张为谷歌搜索图片。网站顶部截图有 2280 张,内容截图有 2280 张,整页截图有 295 张。唯一问题数为 289 个,唯一重新查询(查询)数也是 289 个,唯一重新排名网站数为 2,400 个。有 264 个唯一答案。
问题文本的最大长度为 41 个字,答案的最大长度为 12 个字符;平均而言,问题的长度为 14.0 个字,答案的长度为 1.9 个字符。根据这些数据,我们对一系列新闻和知识问题进行了研究。

该图表分别描述了四个不同任务(重新查询、重新排序、摘要和端到端)。具体来说,它显示了每个任务的输入内容、大型多模态模型 (LMM) 输出和正确答案(地面实况)之间的对应关系。
1. requery:.
- 输入:使用名为 "查询信息 "的数据。
- LMM 输出:模型产生一个新的 "LMM 重新查询"。
- 正确答案:重新查询的正确答案将作为 "重新查询注释 "给出。
2. reerank:.
- 输入:使用 "查询信息 "和 "简化结果"。这决定了哪些信息是重要的。
- LMM 输出:模型输出 "LMM 重新排序",挑选出最重要的信息。
- 正确:"重新排序注释 "中给出了正确的排序。
3. 总结:。
- 输入:"查询信息 "和 "完整的网站内容"。
- LMM 输出:模型根据查询汇总为 "LMM 答案"。
- 正确:"答案注释 "中给出了准确的摘要。
4. 端到端:。
- 输入:"查询信息 "用于表示流程,其中包括一系列过程(重新查询、重新排序、汇总)。
- LMM 输出:在整个过程中获得的 "LMM 答案 "作为最终交付成果。
- 正确:"答案注释 "是整个端到端流程的结果。
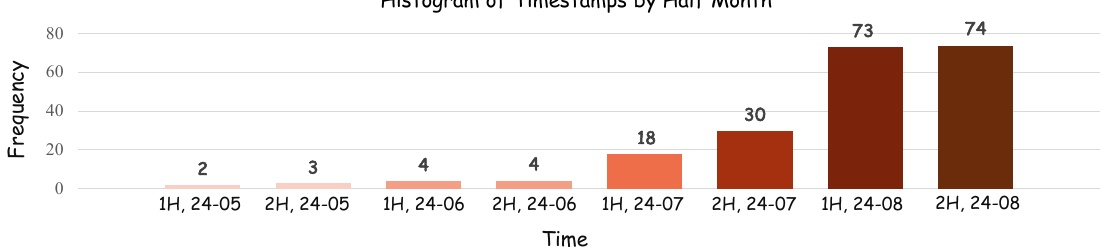
该图是一个直方图,显示了以半月为单位的数据出现频率。横轴代表时间(年-月),纵轴代表频率。从图中可以看出,2024 年 5 月至 8 月的数据都包含在内,其中 8 月的数据频率尤其高。
标签 1H 和 2H 表示半月划分,直观地显示了每个时期产生的数据量。其中,2024 年 8 月下半月的数据量最大,可以看出数据收集主要集中在这一时期。

该图显示了美国国家航空航天局 VIPER 月球探测计划取消的日期和时间。该图分为三个步骤。
1. 重新查询(任务 1 Requery):.
- 第一个问题是:"在 2024 年的哪一天,这张图片中显示的月球探测计划被宣布取消?答案是
- LMM(大规模语言建模)建议重新查询 "VIPER 被宣布取消"。在这一阶段,对问题进行重新结构化,以获取准确信息。
2. 重新排名(任务 2 重新排名):.
- 显示了根据重新查询从搜索引擎检索到的候选网站。
- 例如,它包含 NASA 官方公告和相关新闻文章的片段。
- LMM 选择 < 网站 2> 作为最有用的信息来源。这一步是确定哪些资源提供的信息最多。
3. 总结(任务 3 总结):.
- 对所选网站的详细信息进行分析,得出最终答案。
- 图中显示答案为 "7 月 17 日"。这个答案表示勘探计划被取消的日期。
通过这一过程,可以看出 LMM 具有利用图像和在线信息提取准确信息的能力。
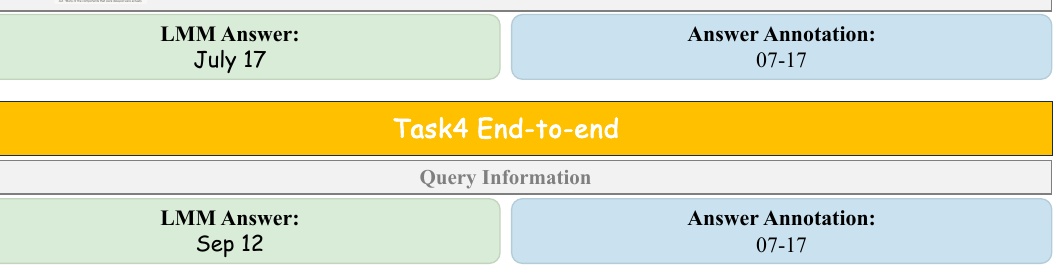
本图展示了多模态模型(LMM)在端到端任务中的表现。图中,LMM 对 7 月 17 日的判断与正确答案注释 "07-17 "并列显示。
LMM 答案 "7 月 17 日 "显示在图表上方,而 "07-17 "则作为答案的注释显示在图表下方。这些注释旨在评估模型根据所给信息正确推导出答案的能力。
这些信息表明了模型回答问题的准确程度。因此,我们可以通过观察 LMM 生成的答案与正确答案注释的对比情况来了解模型的性能。
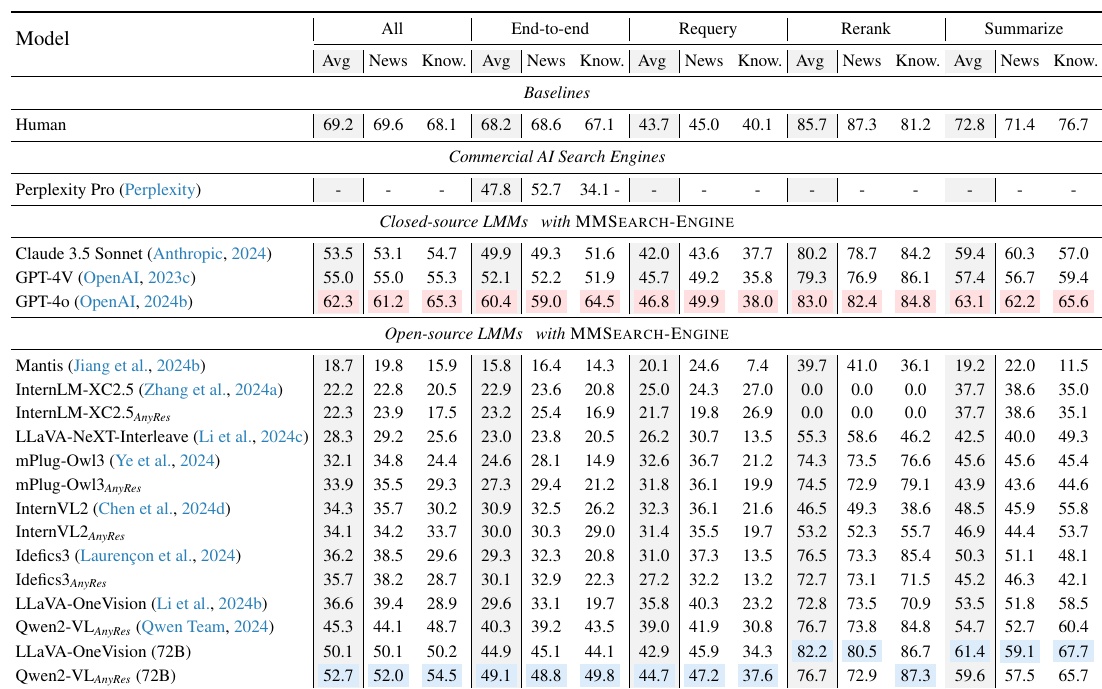
该图表显示了不同的大规模多模态模型(LMM)在 "MMSEARCH-ENGINE "上的表现。评估分为四个主要任务:"端到端"、"requery"、"重排 "和 "汇总"。
- 行列结构:每行显示不同的 LMM,每列显示任务中的具体评价指标(平均得分、新闻领域得分和知识领域得分)。
- 模型比较:分为两大类:"闭源 LMM "和 "开源 LMM"。在 "闭源 LMM "中,GPT-4o 得分最高。另一方面,Qwen2-VL 在 "开源 LMMs "中表现相对较高。
- 得分分布:每个机型在不同任务中的表现差异很大。例如,GPT-4o 在 "端到端 "任务中的得分为 64.5,是该任务中的最高分。它在 "重新排名 "任务中也取得了很高的成绩。
- 人类标准:人类得分也是比较的基础。总体而言,人类得分最高,但也有机器在某些任务中得分接近的例子。
该图表是衡量大规模多模态模型执行多方面任务能力的指标,有助于了解模型的改进和优势。

该图显示了搜索引擎模型中的错误类型。左边的饼图显示了重新搜索过程中的错误类型,右边的饼图显示了汇总过程中的错误类型。
重新搜索错误类型:
- 不相关:占 27.6%,表明重新搜索查询不合适。
- 缺乏针对性:24.1% 的错误是由于缺乏查询细节造成的。
- 低效查询:20.7%,原因是查询未针对搜索引擎进行优化。
- 不包括图像搜索结果:这里也有 20.7% 的查询缺乏图像信息。
- 不变:6.9%,查询按原样使用。
摘要错误类型:
- 文本推理错误:53.0%,主要原因是未能根据文本进行推理。
- 非正式(格式不兼容):24.2%,表明输出不适合该格式。
- 图像-文本聚合错误:10.6% 未正确整合图像和文本信息。
- 图像推理错误率:9.1%,图像推理存在问题。
- 幻觉:3.0%,包含与现实不符的信息。
该图强调了具体的挑战,尤其是在生成对用户问题的模型回答过程中。
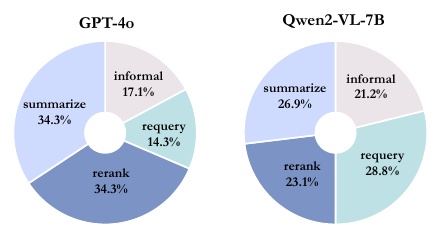
该图显示了两种不同型号 GPT-4o 和 Qwen2-VL-7B 的误差细目。每个饼图都直观地显示了每种型号的误差类型和误差程度。
左边是 GPT-4o 的错误分类。大部分错误是 "总结 "和 "重排 "错误,各占 34.3%。非正式 "错误占 17.1%,"重排 "错误占 14.3%。这表明还有改进的余地,尤其是在总结和重新排序任务方面。
右侧显示了 Qwen2-VL-7B 的错误分类,其中 "requery "错误最常见,占 28.8%。总结 "错误占 26.9%,"非正式 "错误占 21.2%,"重排 "错误占 23.1%。可以看出,该模型中与重新研究有关的错误特别多。尽管在结构上存在一些差异,但两个模型都显示出错误发生在多个工作步骤中。
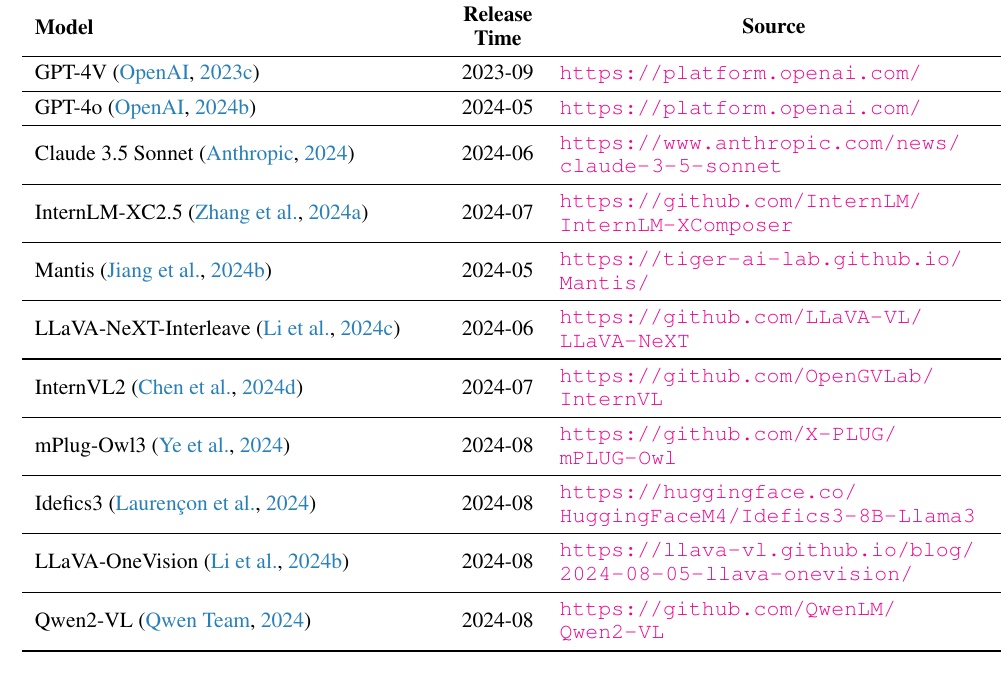
本表汇集了多个大规模多模态模型(LMM)的相关信息。表中列出了每个模型的名称、发布日期和源代码链接。其中特别列出了 OpenAI、Anthropic 和几个 GitHub 资源库等来源,以帮助了解最新的研究和开发情况。
表格左侧列出了模型名称,并包含指向各自开发者和相关论文的链接。如果需要更多信息,可以通过这些链接直接访问。右侧一栏还列出了发布日期,以便比较每个模型的发布时间。

本图展示了 "2024 年 LPL 夏季赛 Ascend 组有多少支队伍 "这一问题的答案。答案是:九支队伍。
图的上半部分显示了问题和答案,说明该信息属于体育新闻的一部分。
接下来,图的中央部分显示了模型向搜索引擎提出的三种不同查询的示例。在这里,GPT-4o、Qwen-VL 和 LLaVA-OneVision 都产生了类似的查询,试图找到信息。
下面是 "简要结果 "部分,列出了不同网站的标题和信息片段。这提供了一个例子,说明该模型如何筛选出最相关的结果。
最后,图表底部显示了 GPT-4o 选择的网站,即 "维基百科 "页面。

该图显示了不同搜索引擎如何显示同一查询的网站搜索结果。
首先,顶部标有 "Round2 Rerank "的部分显示了根据特定查询检索到的多个网站的摘要。这里列出了每个网站的标题和片段(简要描述),概述了它们的内容。例如,网站包括 "LPL 2024 夏季赛 - 小组赛 "等信息,其中描述了联赛分组和比赛形式。
图的中央部分显示了 Qwen2-VL 选择的网站示例。该模型会对搜索结果进行评估,并选择包含最佳信息的网站。
底部的 "LLaVA-OneVision 简要结果 "显示了由另一个搜索引擎生成的相同查询结果。
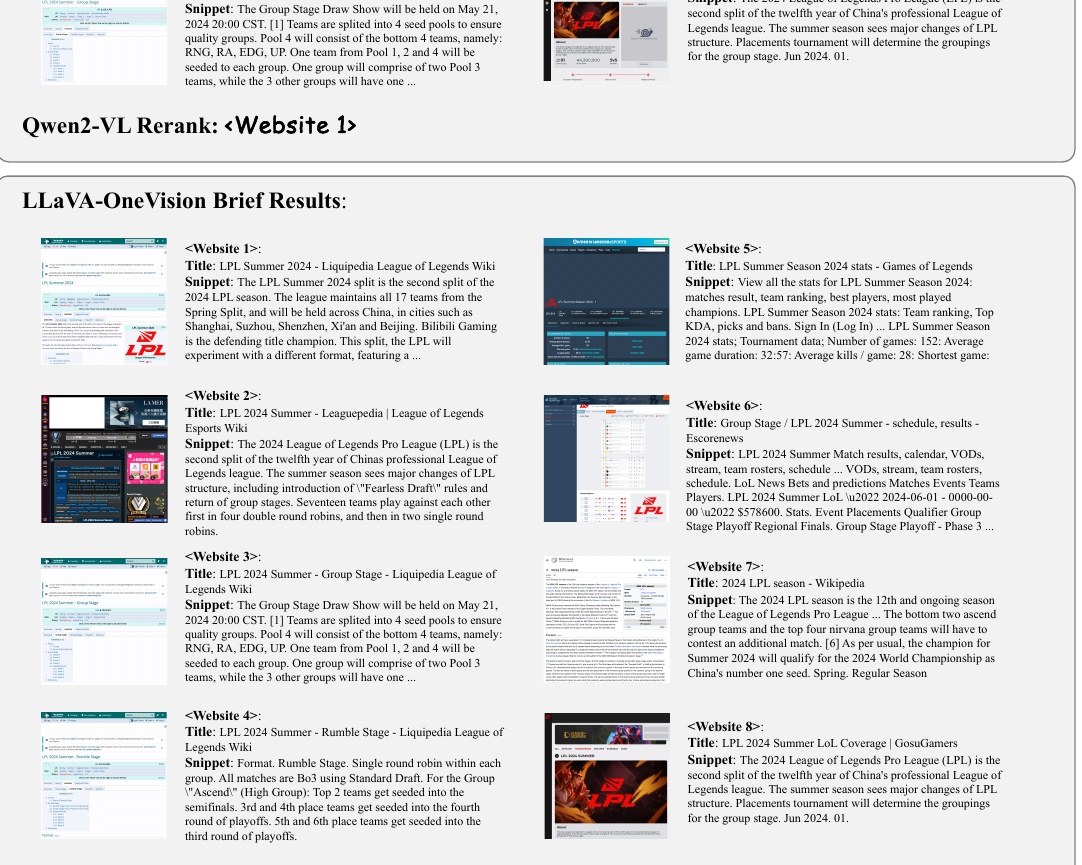
本图显示了从多个网站收集到的信息。每个网站都包含有关 2024 年英雄联盟职业联赛(LPL)夏季赛的信息。具体来说,这些网站涉及比赛结果、战队排名和观看相关信息,还包括有关 LPL 赛制和参赛战队的详细信息。
图中列出了多个网站的摘要和标题,例如:LPL 2024 夏季赛 - Liquipedia 英雄联盟维基。每个网站涉及 LPL 夏季赛的不同方面,但通常都会介绍队伍、比赛结构和最新比赛结果。
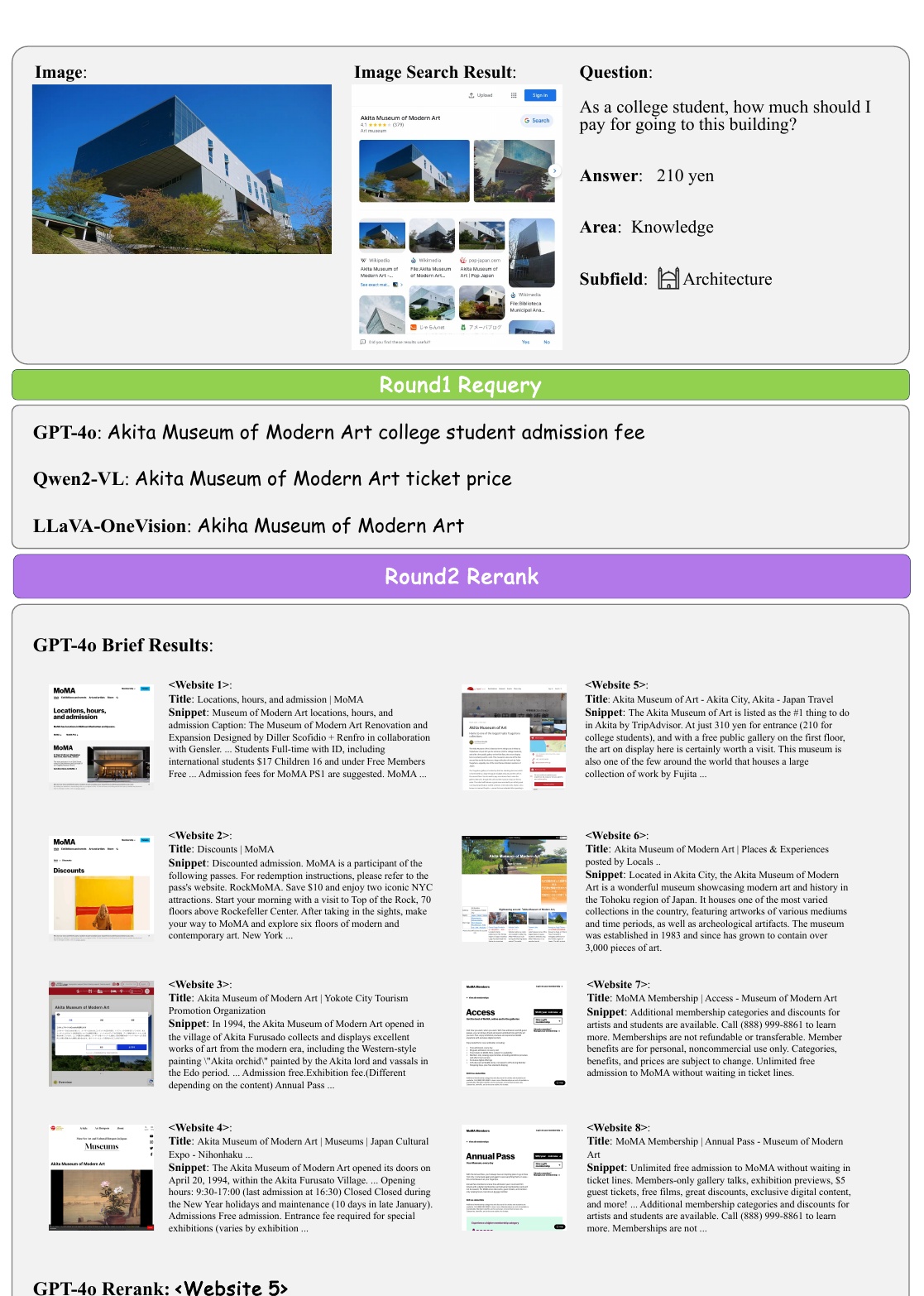
本图说明了一名大学生查找秋田现代美术馆门票价格的过程。图片搜索结果用于说明查找相应信息的过程。
首先显示的是秋田现代美术馆的外观图片及其图片搜索结果。接下来是问题 "大学生进入这座建筑应支付多少费用?这一问题表明了希望了解该建筑入场费的意图。
根据图像搜索结果,人工智能模型向搜索引擎输入不同的问题。GPT-4o "和 "Qwen2-VL "采用了略有不同的方法来查找信息,例如分别查找 "大学生入学费用 "和 "票价"。
最终,GPT-4o 判定网站 5 最为相关,并根据其内容提出了 210 日元的正确入场费。

这张图片显示的是该建筑的外观,搜索结果显示该博物馆名为 "秋田现代艺术博物馆"。问题是作为大学生进入这座建筑需要多少钱,答案是 "210 日元"。这些信息与知识中的 "建筑 "领域有关。展示的信息旨在利用图像及其搜索结果来确定具体地点和费用。
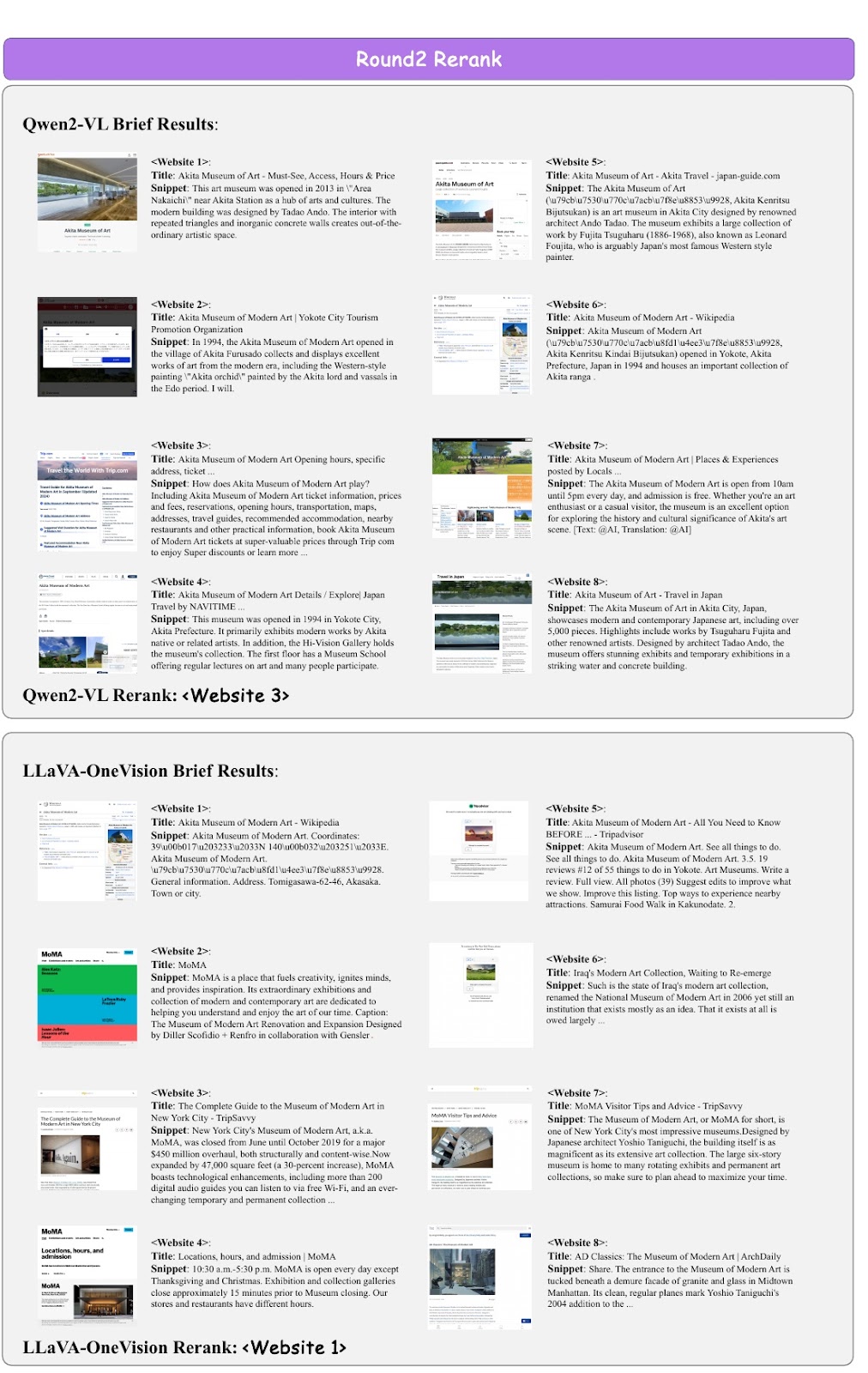
该图展示了本文 "第二轮重新排序 "过程中搜索结果的选择。具体来说,Qwen2-VL 和 LLaVA-OneVision 这两个不同的模型将从给定信息中选择合适网站的场景可视化。
我们先来看看 Qwen2-VL 的结果。该模型基于秋田现代美术馆(Akita Museum of Modern Art)的信息。在搜索结果中,Qwen2-VL 选择了 "网站 3"。该网站提供了博物馆的开放时间和具体地址信息,还包括旅游指南和周边推荐。
下一节将讨论 LLaVA-OneVision 的结果。本模型还涉及秋田现代美术馆的信息,并从提供的网站中选择了 "网站 1"。该网站基于维基百科的信息,包含一般信息和位置信息。
这两种模式都能从得到的信息中挑选出他们认为最有用的网站。

本图位于本文题为 "Round2 Rerank "的部分,显示了 Qwen2-VL 模型用于重新排序的网站的简单结果。该图的目的是评估哪些网站为问题提供了最有用的信息。
图中显示了八个网站的标题和片段(简要描述)。这些片段概述了每个网站的内容。在整个过程中,模型会决定选择哪个网站,以及该选择会如何影响接下来的信息收集和回复生成。
具体来说,Qwen2-VL 模型显示 <Website 3> 已被选中。该网站提供了秋田现代美术馆的详细信息,其中包括游客希望了解的展览和门票价格等信息。这有助于模型为问题确定最合适的信息源,并根据这些信息生成答案。



与本文相关的类别
![[Libra] 利用解耦视觉系统对大规模](https://aisholar.s3.ap-northeast-1.amazonaws.com/media/February2025/libra-520x300.png)




