
TaPA:使用 LLM 的机器人行为生成代理。
三个要点
✔️TAsk Planing Agent (TaPA) 具有 LLM 和视觉感知模型,可根据场景中的物体生成可执行的计划
✔️ 开放式词汇,可处理现实中的复杂任务对象检测器的通用化。
✔️ 与 ChatGPT3.5 相比,机器人行动步骤的平均成功率有所提高
Embodied Task Planning with Large Language Models
written by Zhenyu Wu, Ziwei Wang, Xiuwei Xu, Jiwen Lu, Haibin Yan
(Submitted on 4 Jul 2023)
Comments: Project Page
Subjects: Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI); Robotics (cs.RO)
code:
本文所使用的图片要么来自论文、介绍性幻灯片,要么是参考这些图片制作的。
介绍。
最近,随着 ChatGPT 的出现,您可能会越来越多地听到自然语言处理这个名字。自然语言处理不仅适用于 ChatGPT 等任务,也适用于机器人。例如,当机器人被引入家政服务、医疗和农业等领域时,它们需要完成这些复杂的任务。他们面临的问题之一是,机器人可替代的行为和自主驾驶情况因领域而异。此外,要针对每个领域和情况对机器人进行预测和培训实际上是不可能的。
然而,最近在大规模语言建模(LLM)方面取得的进展,使得从大量数据中获取丰富的 "知识 "成为可能。这将使机器人能够在各种情况下根据人类的(自然语言)指令产生行为。
挑战
不过,使用 LLM 生成机器人行为也存在一个问题。那就是 LLM 无法识别周围的场景。另一个问题是可能产生不可行的行为,因为机器人行为的产生需要与不存在的物体进行交互。
例如,在人类发出 "给我一些酒 "的指令后,GPT-3.5 生成的操作步骤是 "把酒从瓶子里倒进杯子里"。然而,现实中可能只有一个杯子而没有酒杯,因此可行的操作步骤应该是 "将酒从瓶子倒入杯子"。因此,在现实世界中执行由 LLM 生成的任务计划对于建立一个完成复杂任务的化身 Agent 是非常必要的。
*这里的 "Agent "指的是 LLM 根据用户要求选择并执行手段和顺序的能力。
本文介绍的 TAsk Planing Agent(TaPA)是一个结合了 LLM 和视觉感知模型的 Agent,可根据场景中的物体生成可执行的计划。
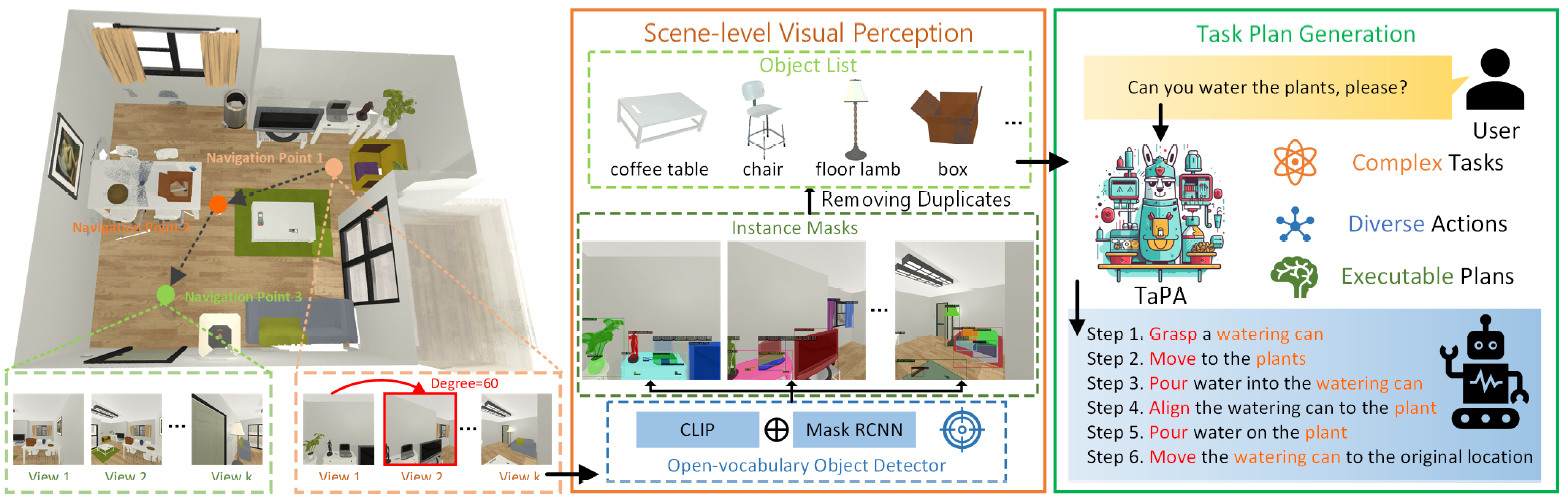
TaPA:TAsk 刨光剂。
TAsk Planing Agent(以下简称 TaPA)是一个结合了 LLM 和视觉感知模型的代理,可根据场景中的物体生成可执行的计划。
具体来说,它首先建立了一个多模态数据集,其中包含三个室内场景、指令和行动计划。接下来,通过提供 GPT-3.5 生成的提示和场景中出现的对象列表,生成一些指令和相应的行动计划。
生成的数据用于调整预训练 LLM 的执行计划,使其与实际情况相符。在推理过程中,通过将开放词库对象检测器扩展到在不同可实现位置收集的多视角 RGB 图像,找到场景中的对象。
TaPA 主要通过以下两种方法实现
嵌入式任务规划的数据生成
本节介绍了多模式指令数据集的构建情况,该数据集将用于调整 TaPA 任务规划器。
给定一个具体的三维场景 Xs,我们直接使用所有物体的类名作为场景的表示:Xl=[桌子、椅子、键盘...]。并删除所有重复的名称,为 LLM 提供场景信息。
根据上述场景信息,LFRED 基准方法是人工设计一套具有相应分步动作的指令,从而生成遵循体现任务计划数据集的多模态指令。然而,人工设计需要很高的注释成本,才能为现实中的服务机器人生成实用而复杂的任务计划,例如用于清洁厕所或制作三明治的机器人。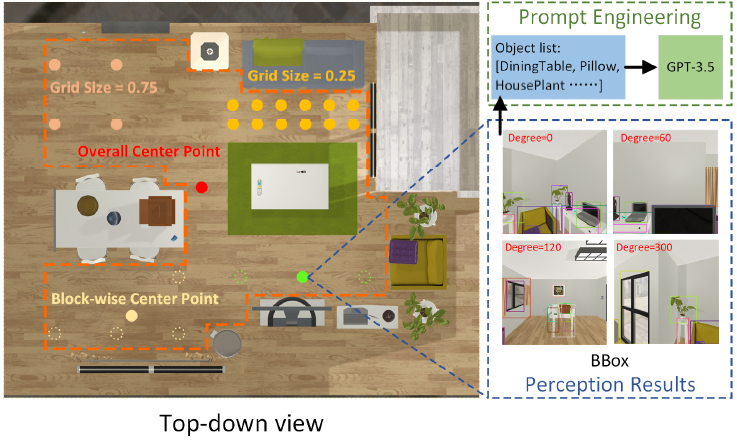
因此,TaPA 利用 GPT-3.5 以及所呈现的场景表示和提示,旨在为 Agent 调整生成大型多模态数据集。
在 GPT-3.5 中,我们设计了一个提示符来模拟具体任务规划场景,该场景可根据对象名称列表 Xl 自动合成数据,从而针对给定的 3D 场景高效生成大型复杂指令 Xq 和可执行的对应计划 Xa。
具体来说,这些提示通过设计服务机器人与人类之间的对话、生成可执行的指令和操作以及提供来自人类的请求,来模拟机器人在一个具身环境中的探索。生成的指令多种多样,包括请求、命令和询问,只有具有明确可执行操作的指令才会被添加到数据集中。在生成数据集的提示中使用的对象列表中,使用了场景中存在的实例的真实标签。
下图显示了一个生成样本的示例,其中包含一个场景的对象名称、指令和可执行操作步骤列表。在具体任务计划中,Agent 只能访问包含所有对话对象的可视场景,而不能访问真实对象列表。

因此,通过为每个样本定义 X = (Xv,Xq,Xa)来构建多模态数据集。任务规划器训练使用每个场景的真实物体列表,以避免视觉识别不准确的影响。推理则通过扩展的开放词汇表对象检测器来预测场景中存在的所有对象列表。
AI2-THOR模拟器也被用作Agent的具体环境,其中80个场景用于训练,20个场景用于评估。为了对有效的任务规划器进行微调,通过修改地面实况对象列表,将原来的 80 个训练场景扩展到 6400 个训练场景,以扩大训练样本中指令和行动步骤的规模和多样性。
对于每个场景,我们首先枚举同一房间类型的所有房间,以获得该类型场景中可能出现的物体列表。接下来,我们会用其他未观察到的物体随机替换出现的物体,因为这些物体可能出现在同一类型的房间中。
将任务计划与周围场景联系起来。
本节详细介绍了通过图像收集和开放词汇检测为场景制定具体任务计划的基础。
为了使所体现的任务计划适应可行的现实,有必要准确获取场景中的物体列表,而不出现实例遗漏或误报。为了探索周围的三维场景,设计了多种图像采集策略。位置选择标准包括遍历位置、随机位置、全局中心点和分块中心点;Agent 针对每个位置选择标准旋转摄像头并获取多视角图像。
图像收集策略 S 用以下公式表示
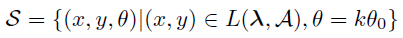
(x,y,θ):位置和摄像机方向,L(λ,A):通过超参数 λ 选择位置的标准。
θ0:摄像机旋转的单位角度,k:定义不同场景方向的整数
所有位置选择标准的共同超参数是网格边缘的长度,它将可实现区域划分为网格。
遍历位置选择 RGB 图像集合的所有网格点。总体中心点代表整个场景的中心,不含超参数。分块中心点选择场景中每个片段的中心,目的是有效获取细粒度的视觉信息。
聚类方法采用 K 均值聚类法,因为整个场景可被划分为多个子区域,以提高感知性能。此外,还采用了簇内平方误差之和(WCSS)原则来为每个场景选择最佳的簇数。
此外,假设场景中出现了新的物体,而这些物体并不在训练有素的检测器中,则需要获取一个物体列表。因此,开放词汇的物体检测器是通用的。此外,Agent 还会收集不同位置的 RGB 图像,用于检测场景中出现的物体。
预测对象列表 Xl用以下公式表示
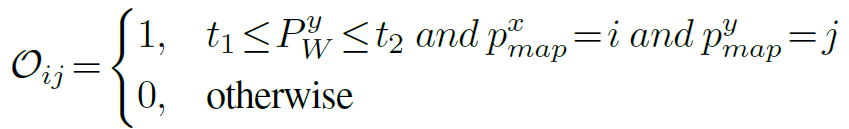
预测对象列表是从多视角图像的检测结果中去除重复对象名称而得到的。其中,Rd 表示去除重复对象名称的操作,D(Ii) 表示场景中第 i 张 RGB 图像检测到的对象名称。
通过这两种方法,Agent 可以生成可执行的计划,同时预测场景中存在的未知物体。
试验
实验中使用了 60 个验证样本,将 TaPA 方法与包括 LLaMA 和 GPT-3.5 在内的最先进 LLM 以及包括 LLaMA 在内的 LMM 进行比较。不同方法生成的行动步骤的成功率如下表所示。

在包括厨房、客厅、卧室和浴室在内的所有四个场景中,TaPA 在所有大型模型中都取得了最佳性能。TaPA 的平均成功率比 GPT-3.5 高出 6.38%。
此外,目前较大型模型的性能比其他房间类型要低,因为厨房场景中的代理通常要处理更多步骤的复杂烹饪指令。另一方面,LLaVA 的低性能表明,在视觉问题解答任务中,整体场景信息无法用单一图像表示,场景信息不足导致任务规划成功率低。

此外,上图还显示了针对给定场景从不同大型模型生成的行动步骤示例。这些场景以自上而下的视图显示,同时还提供了一个地面实况对象列表供参考;LLaMA 的内容独立于人类指令,而 LLaVA 则为不存在的对象提供不可执行的计划。GPT-3.5 也能生成具体化的任务计划,而 TaPA 的行动步骤更为完整,更接近人类的价值观。
结论
最近,通过自然语言处理生成机器人行为的研究变得更加活跃。如果进一步开发技术,使机器人能够根据人类的指令行动,那么就有可能创造出能够应对环境变化(如天气条件)的机器人,而这正是自动驾驶技术所面临的问题。
此外,如果交互技术在未来得到发展,就像本文讨论的研究一样,预计人类和机器人之间将实现安全协作,人们的工作方式也将发生改变。



与本文相关的类别
![[Libra] 利用解耦视觉系统对大规模](https://aisholar.s3.ap-northeast-1.amazonaws.com/media/February2025/libra-520x300.png)




