
什么是 "提示音调整"?
三个要点
✔️ 建议的提示调整只学习冻结的通用 LLM 的提示部分
✔️ 命中精度接近微调
✔️ 允许大幅减少参数
The Power of Scale for Parameter-Efficient Prompt Tuning
written by Brian Lester, Rami Al-Rfou, Noah Constant
(Submitted on 18 Apr 2021 (v1), last revised 2 Sep 2021 (this version, v2))
Comments: Accepted to EMNLP 2021
Subjects: Computation and Language (cs.CL)
code:
本文所使用的图片要么来自论文、介绍性幻灯片,要么是参考这些图片制作的。
介绍
本文介绍了有关提示调整的研究,这是 LLM 的提示技术之一。
最近的高精度 LLM(如 GPT-4 和 T5)的参数数量远远超过 100 亿。如此庞大的参数数使得以通用方式解决各种任务成为可能。
因此,利用这种庞大的法学硕士来专门从事特定领域的工作的举措已变得流行起来。例如,专门从事医疗领域工作的法律硕士或专门从事教育领域工作的法律硕士。为了专门从事这些领域的工作,主流方法是培训预先训练好的 LLM,并为每个领域提供专门的附加数据。
这种方法被称为附加学习,主要有以下几种技术
- 模型调整(微调)
- 普罗普特设计公司(普罗普特工程公司)
此外,如何以低成本进行额外学习的问题也经常被讨论。这是因为,正如所预料的那样,学习具有数千亿个参数的 LLM 计算成本高昂,如果不引入与大型企业同等的计算资源,就不可能做到这一点。
为了解决这些计算成本问题,本文提出了一种名为 "提示调整 "的方法。
什么是模型调整(微调)?
模型调整是一种更新整个模型或其部分参数的方法,具体做法是在预训练模型的最后一层添加一个特定任务层,以便为每个任务专门设计 LLM。这需要大量的待解任务数据,这些数据需要被训练到预训练模型中。
这样,通用 LLM 就可以针对每项任务进行专门化,从而提高该领域的准确性。
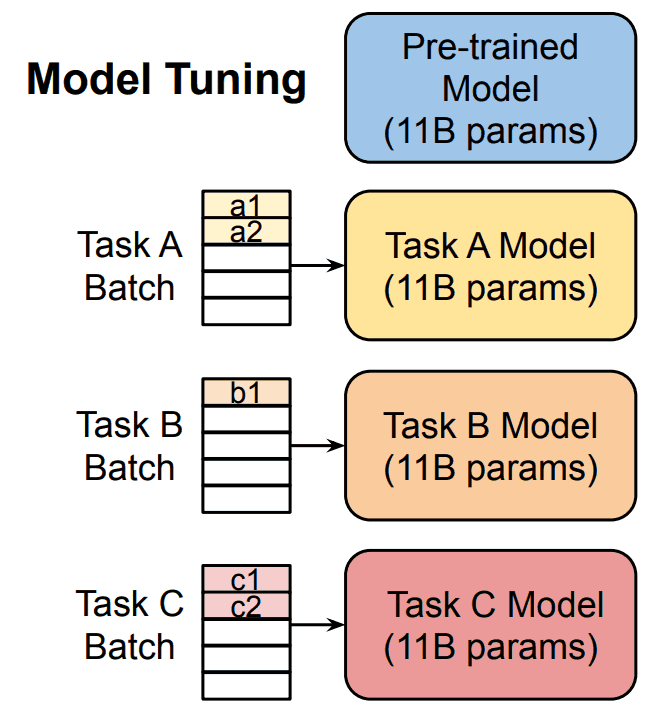
模型调整(微调)的问题
然而,如前所述,用数千亿个参数训练一个 LLM 需要巨大的计算资源。此外,从资源角度来看,为每项任务创建大量专门的 LLM 是不现实的。
什么是 Prompt 设计(Prompt Enginnering)?
自从讨论 ChatGPT 以来,"提示"(Prompt)一词也被使用。简而言之,"提示 "是 "给 LLM 的指令",主要有两种类型的提示
- 硬提示
- 软提示
除了 "提示 "一词外,"提示设计"(Prompt Enginnering)一词也经常被使用。这是一种由人工对提示进行适当设计以提高准确性的方法,无需额外的 LLM 学习。
针对这种方法,人们发明了各种技术,如 Few-shot 和 CoT,每种技术都有硬提示。
提示设计的问题(提示工程)
这种提示设计的成本相对较低。然而,本研究的作者指出了这些硬提示存在的以下问题
- 要求设计师具备迅速的技能。
- 准确度远低于模型调整。
特别是在准确率较低方面,下图提供了证据。
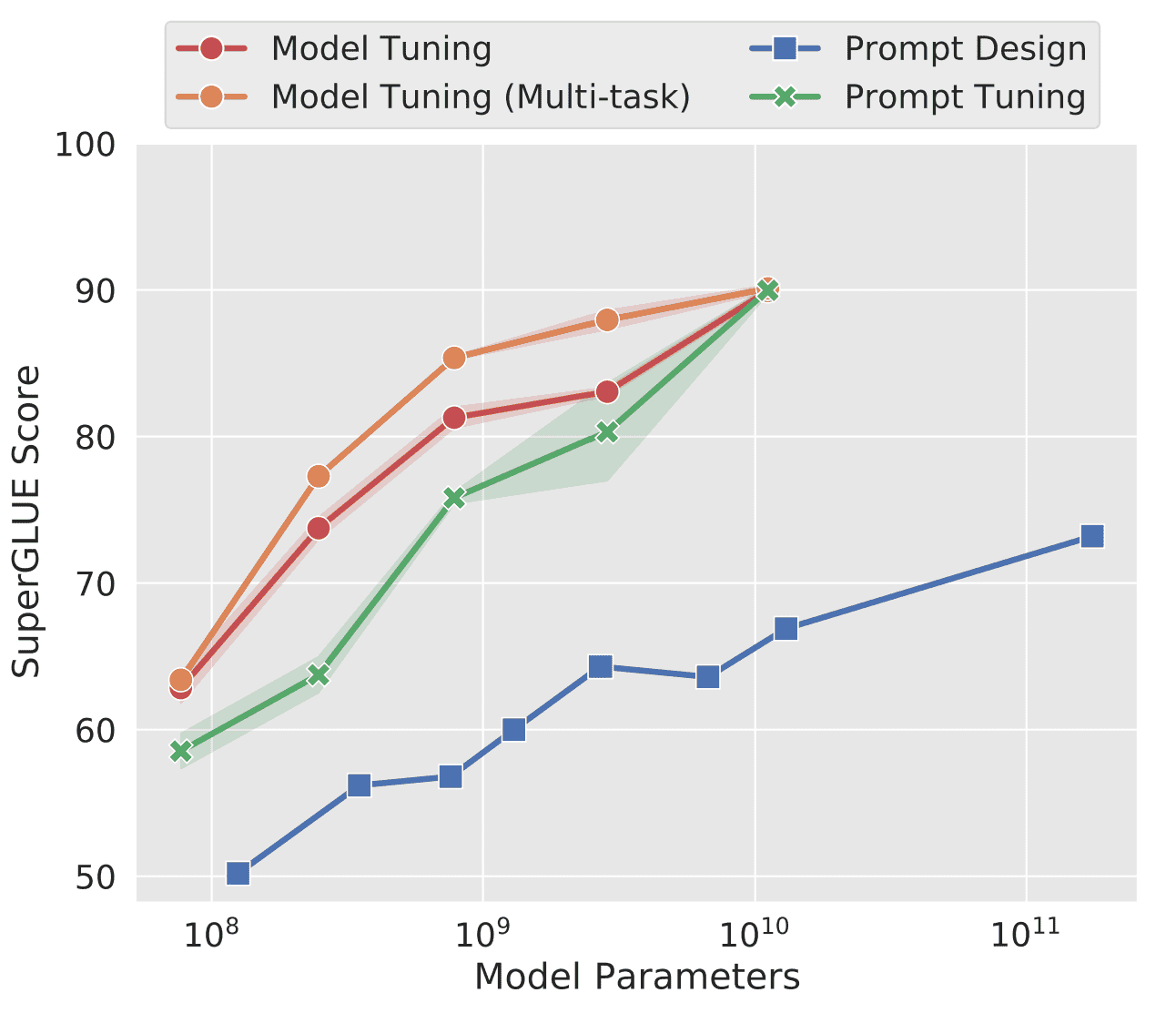
图中纵轴指的是 SuperGLUE,即 "各种 NLP 任务准确度的总分"。横轴也是参数的数量,随着参数数量的增加,SuperGLUE 自然也会增加。
从图中可以清楚地看出,"提示设计 "的精确度最低,最多比 "模型调整 "精确 25 个点。
什么是本文提出的 "提示调整 "方法?
在这里,我们最后介绍本文提出的方法:"提示符调整法",即让 "提示符 "学习。
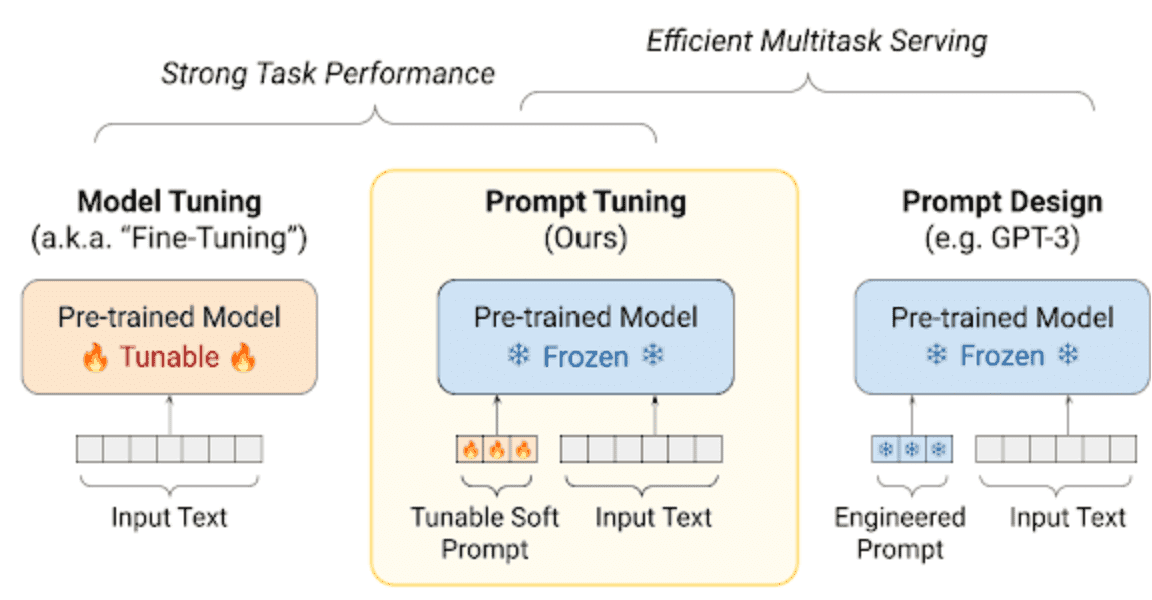
https://blog.research.google/2022/02/guiding-frozen-language-models-with.html
从上图可以看出,在与提示相对应的输入文本中添加了一个可调整参数的提示(软提示)。这就是训练向量。请注意,它也被称为软提示。
在 "模型调整 "中,没有这样的软提示,只有输入文本。提示设计还显示,软提示和预训练模型都不会被冻结,也不会进行训练。
此外,使用 Prompt Tuning 技术,只需一个预先训练好的模型就能专门用于多个任务,而不必像使用 Model Tuning 技术那样,为每个任务都建立一个模型。
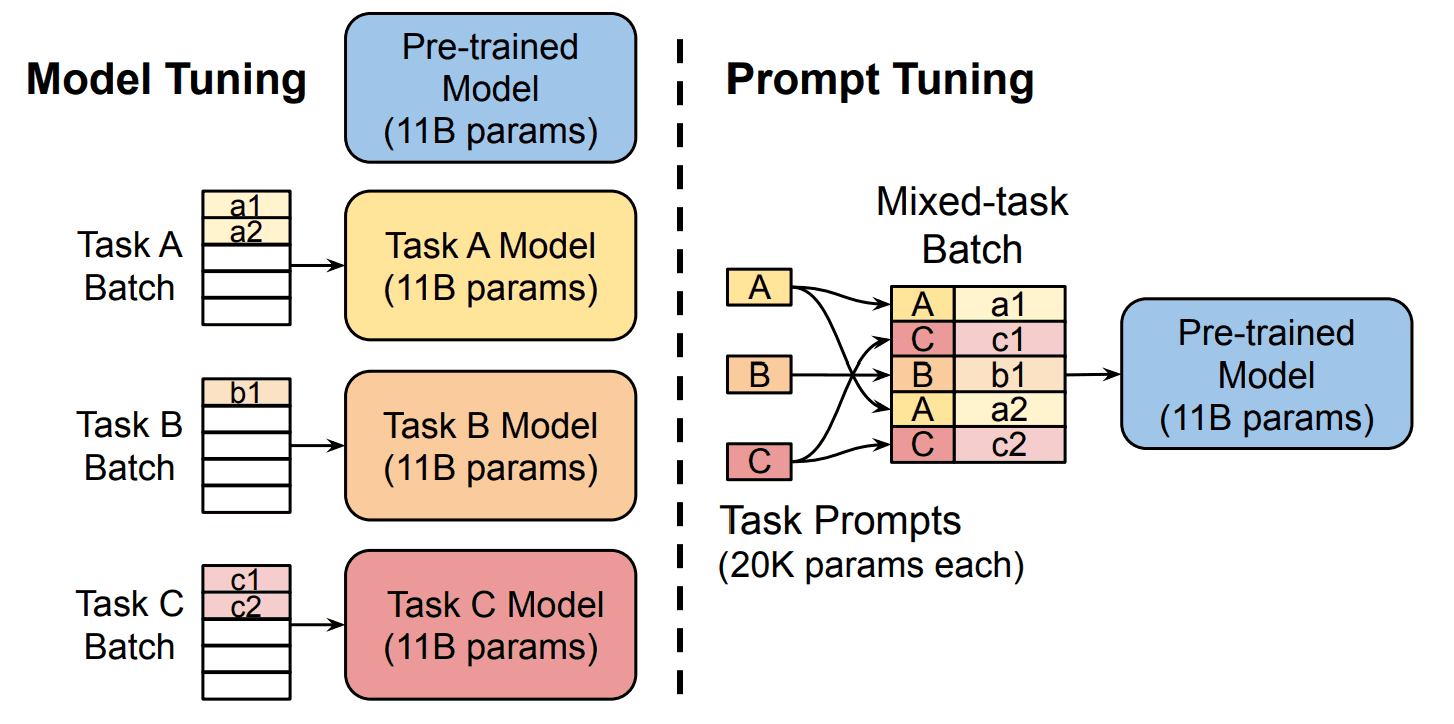
在这里,软提示包括 "标记计数 "和 "嵌入"。两者的定义如下。
- 标记数:如输入的字数
- 嵌入:每个标记的向量表示(嵌入)
如果软提示标记的数量为 p,每个标记的嵌入向量维数为 e,那么软提示 参数的数量就用 p*e 表示。 现在比较一下提示调整和模型调整的训练参数数。
例如,如果软提示中的词块数量 p 为 100,单词 e 的嵌入表示维度为 4096,那么训练参数的数量如下。
- 提示调整:100*4096=409600 参数
- 模型调整:当预训练模型设置为 T5 时,最多可设置 110 亿个参数
与 "模型调整 "相比,"提示调整 "的效率要高得多。
最佳软提示标记数p是多少?
软 提示的 标记数 p 或长度越小,训练参数就越少,因此效率更高。然而,一般来说, 参数数量越少,准确率就越低,那么 Prompt Tuning 又如何呢?
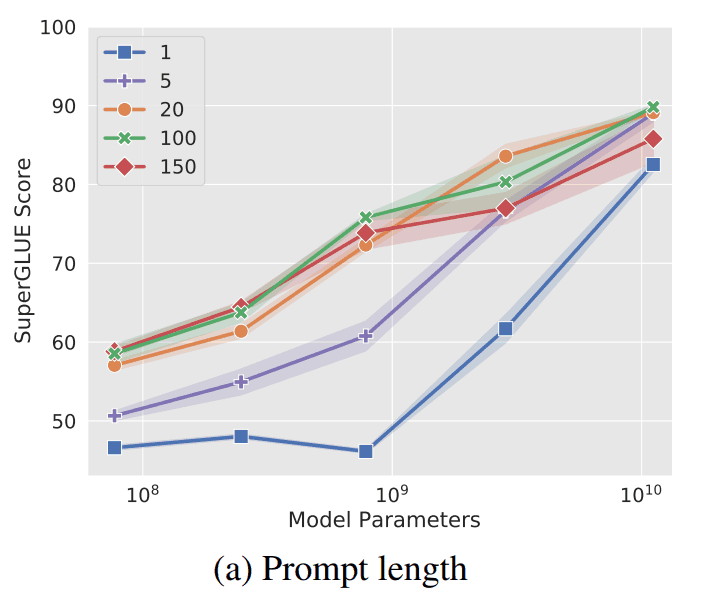
从上图可以看出,令牌数越多,准确率越高。然而,当参数数为1010= 100 亿(与 T5 中的参数数相当)时,可以看出即使令牌数为 1,也能达到很高的精度。
因此,如果将庞大的模型用于预训练模型,则标记数可能无关紧要。
结果
尽管本研究中有许多验证,但我们将重点关注以下三个方面。
- 每种方法与提示调整法的精确度比较。
- 适应领域转移。
- 提示合奏
让我们依次来看看它们。
每种方法与提示调整法的精确度比较
在本研究中,进行了模型调整和提示设计的对比实验,以验证提示调整的准确性。在这里,T5 作为预训练模型用于模型调整和提示调整,GPT-3 用于提示设计。
结果如下图所示。这是一个复述。
可以看出,Prompt Tuning 比 Prompt Design 强大得多。此外,当参数数增加到1010= 100 亿时,"提示调整 "的精度几乎与 "模型调整 "相同。
适应领域转移
域转移问题是指 LLM 过度适应数据集的现象。例如,在一个数据集上训练的模型不一定能适应另一个数据集。
为了避免这种过度拟合,并测试适应领域变化的能力,本研究将在 QQP 和 MRPC 数据集上分别进行训练和测试。例如,在 QQP 数据集上进行训练时,会在 MRPC 数据集上进行测试。
此外,验证还包括模型调整和提示调整的准确性比较。结果如下
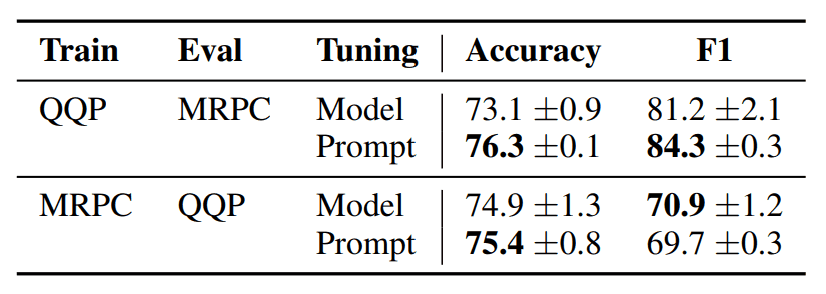 从 QQP 到 MRPC,提示调整的准确度和 F1 都更高;从 MRPC 到 QQP,提示调整的准确度也更高。
从 QQP 到 MRPC,提示调整的准确度和 F1 都更高;从 MRPC 到 QQP,提示调整的准确度也更高。
因此,"即时调整 "在处理域转移问题时可能更具适应性。
提示合奏
有一种 "集合学习",即通过多数投票等方式,从多个模型的输出结果中计算出最终输出结果。
在本研究中,这种集合学习也通过应用于 Prompt 得到了验证。具体来说,不是准备多个模型,而是准备多个 Prompt 模式,并对它们应用 Ensemle 学习。
结果如下
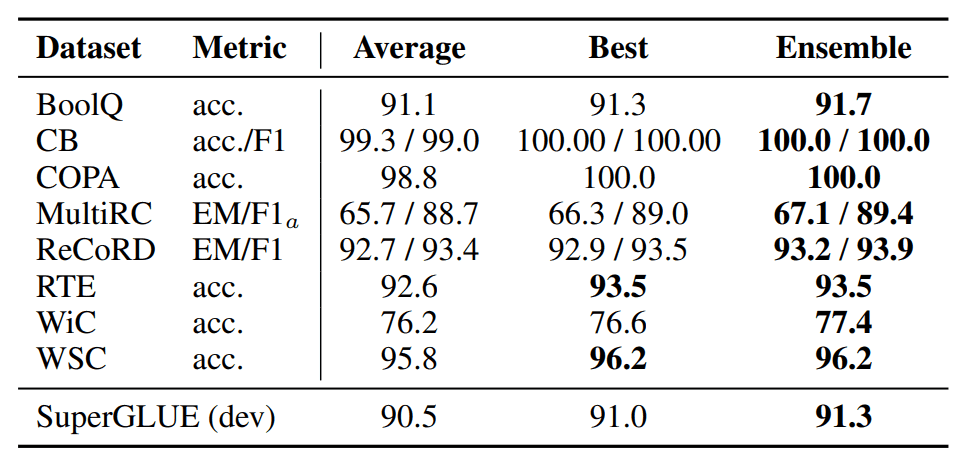
上图中的结果表明,即使使用了 "提示调整"(Prompt Tuning),集合学习也能达到很高的精度。
摘要
本研究提出 "提示音调整 "的动机是 "让我们也优化提示音"。
迄今为止,最主要的方法是提示工程师(人工)设计最佳提示句。不过,通常有人认为,在使用大量数据和计算资源对 LLM 进行训练之后,人类再为 LLM 的后续使用付出艰辛努力是低效的,因此最好也让 LLM 自动创建提示句。
本研究为这些观点提供了有效的方法和理由。
此外,这项研究本身并不新鲜,预计未来还会出现更有效的方法。这样一来,我们人类所做的可能仅限于 "直观地指挥 LLM,而无需考虑提示技术",而后面的 "提高 LLM 的准确性 "的任务可能会留给 LLM 自己去完成。
事实上,还有一些代理和其他相关技术值得您去了解。



与本文相关的类别


![[情感提示] 情感提示输入可提高 LLM](https://aisholar.s3.ap-northeast-1.amazonaws.com/media/January2024/emotionprompt-520x300.png)
