一个离线的Meta-RL框架,使机器人能够利用以前收集的数据快速适应未知和复杂的插入任务!
三个要点
✔️ 我们提出一个离线元RL框架,可以解决复杂的插入任务。
✔️ 通过使用示范和离线数据,我们可以快速适应未知任务。
✔️ 通过微调,在30分钟内实现所有12个任务的100%成功率,即使在学习和测试的任务有很大不同。
Offline Meta-Reinforcement Learning for Industrial Insertion
written by Tony Z. Zhao, Jianlan Luo, Oleg Sushkov, Rugile Pevceviciute, Nicolas Heess, Jon Scholz, Stefan Schaal, Sergey Levine
(Submitted on 21 Mar 2021 (v1), last revised 31 Jul 2021 (this version, v4))
Comments: RSS 2021
Subjects: Artificial Intelligence (cs.AI); Robotics (cs.RO)
code:
本文所使用的图片要么来自论文、介绍性幻灯片,要么是参考这些图片制作的。
简介
近年来,各种研究表明,强化学习通过学习策略,可以在使用真实机器人的部件插入任务中取得很高的成功率。特别是,我们已经表明,本文所描述的方法可以使用少量的演示、强化学习和一些巧妙的方法来解决非常复杂的插入任务,而且成功率很高。然而,如果我们想解决一个有不同组件的插入任务,我们必须从头开始重新学习这个方法。在这篇文章中,我们提出了一篇名为《离线元强化学习的工业插入》的论文,它解决了这个问题。
近年来,元RL作为一种能够在瞬间适应未知数据的强化学习方法,一直备受关注。然而,meta-RL需要非常耗时的在线meta-RL训练,这在现实世界中很难执行。因此,在本文中,我们提出了一种方法,利用事先收集的各种离线数据集进行在线元RL,如下图所示,然后进行在线微调,即时适应未知部分。现在,我们将解释本文的细节。
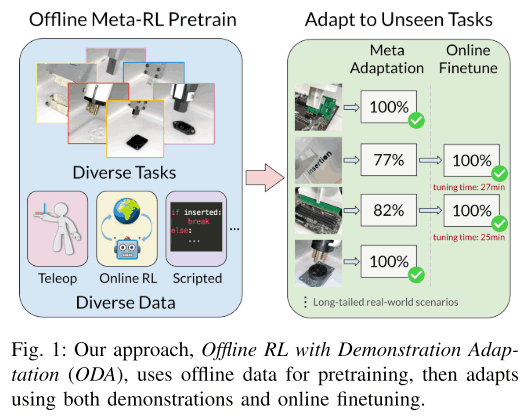
方法
在本章中,我们将详细解释所提出的方法。首先,通过离线RL的元训练来训练一个自适应策略。该数据集由事先收集的使用各种组件的任务演示和离线数据(如存储在以前训练的重放缓冲区的数据)组成。然后,这个自适应策略被用于未知任务,在那里,少量的演示和在线RL微调被用来获得最终的策略。这样一来,与使用在线RL将以前学到的策略应用于未知的任务相比,调整策略以适应未知的任务更加安全和容易。
该方法中使用的策略由策略网络$pi(a|s, z)$和编码器$q_{\phi}(z|c)$组成,其中$s$是当前状态,$z$是代表任务的潜在代码。因此,编码器从任务的演示中提取出知道如何执行该任务所需的关键信息,并将其放入潜伏代码。这与PEARL和MELD的方法类似,但潜伏代码是从演示中获得的,而这些方法是通过在线经验来获得潜伏代码。
然后,在适应未知任务时,给出少量的示范作为任务的背景,根据它可以推导出潜伏代码$z\sim q(z|c)$,并对未知任务使用策略。然而,如果未知任务与元训练中使用的任务非常不同,可能很难估计$z$,从而使策略能够解决未知任务。在这种情况下,我们使用在线RL对政策进行微调。本文的实验表明,这种微调大约需要5-10分钟。
现在我们将更详细地解释这些步骤中的每一步。
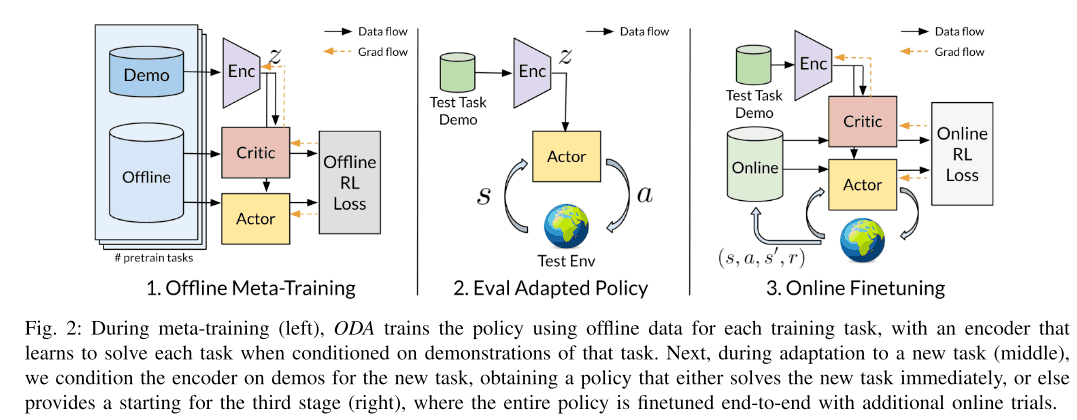
语境元学习和演示
如上所述,本文提出的方法使用演示作为任务背景来学习编码器$q_{phi}(z|c)$,与之前的方法如PEARL和MELD不同。然后,输出的潜伏代码$z$被传递给策略$pi_{theta}(a|s, z)$。接受这种示范的好处是,它可以减少训练和测试分布之间的差异造成的性能下降,这种差异称为训练-测试分布偏移。这是由于在测试时收集的未知任务的数据和训练时使用的离线数据是从不同的政策中收集的,这可能会导致分布偏移。这个问题是通过使用示范来解决的。
在训练过程中,编码器$q_{phi}(z|c)$和策略$pi_{theta}(a|s, z)$同时被训练,以最大化元训练任务的性能。在训练过程中还使用了两种类型的数据,一种是由演示数据组成的,另一种是由离线数据组成的,用于更新行为者-批评者。这种离线数据对应于存储在先前训练的任务的重放缓冲器中的数据。编码器还对潜伏代码$z$添加了KL发散损失,以使其尽可能不含不必要的信息。这些详细的算法显示在下面的算法图中。

离线和在线强化学习
由于这种方法需要用离线数据进行元训练,因此需要一种合适的离线RL算法,这种算法称为Advantage-Weighted Actor-Critic(AWAC)。由于事后还需要进行微调,我们使用了一种叫做Advantage-Weighted Actor-Critic(AWAC)的方法,该方法将奖励最大化,并学习一种政策以接近数据的分布$pi_{\beta}$,如以下公式所示AWAC学习政策,以使奖励最大化,并接近数据的分布$pi_{beta}$,如以下公式所示。
$$theta^{star}=arg\max\mathbb{E}_{mathbf{s} sim\mathcal{D}}\mathbb{E}_{pi_{theta}(\mathbf{a}\mid)\}\left[Q_{phi}(\mathbf{s}, \mathbf{a})\right] `text { s.t. } D_{K L}\left(pi_{theta}\| pi_{beta}\right) `leq `epsilon$$
这可以通过使用拉格朗日的加权最大和似然来近似,如下所示
$$theta^{star}=\underset{theta}{arg \max } \mathbb{E}_{mathbf{s}, \mathbf{a} \sim β}\left[log pi_{theta}(\mathbf{a} \mid\\A^{pi}(mathbf{s}, `mathbf{a})`right)`right] $$
其中$A^{\pi}(\mathbf{s}, \mathbf{a})=Q_{phi}(\mathbf{s}, \mathbf{a})-E_{mathbf{a} `pi_{theta}(\mathbf{a} `mid)\mathbf{s})}\left[Q_{\phi}(\mathbf{s}, \mathbf{a})\right]$.
使用这种技术,在元训练之后,必要时进行微调,以最大限度地提高未知任务的性能。具体算法如下

实验
在本文中,我们在12个未知任务上评估了所提出的方法,并回答了以下四个问题
1.与常规的离线RL相比,它是否更有优势
2.微调是否可以用来快速适应与训练用的任务有很大不同的未知任务
3.它是否能适应更困难的任务,如下面所展示的任务
4.是否可以通过使用更多的数据来改善元适应性
实验中使用了KUKA iiwa7机器人,TCP姿势、速度和作用在刀尖上的力矩(扳手)被作为观测值给出。在每一集的开始,机器人被给予一个从均匀分布$U$[-1mm, 1mm]中采样的噪声。
作为一个离线数据集,我们从11个不同的插头和插座对收集了数据,如下图所示。我们使用以前一篇使用DDPGfD的论文中存储在重放缓冲区的数据作为离线数据。我们还使用了与训练时相同的示范来训练我们的方法。

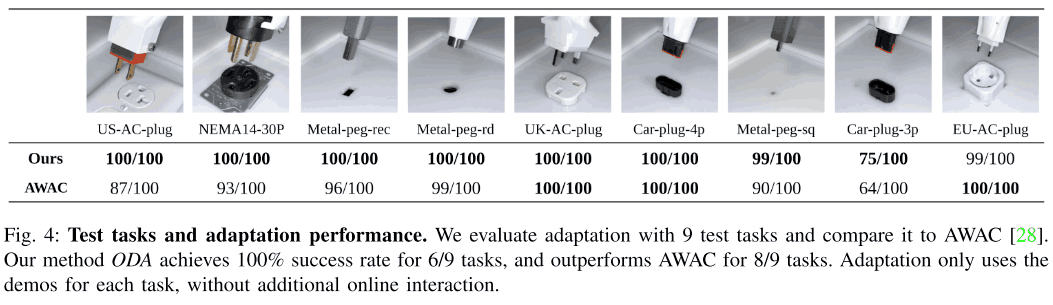
使用学习的编码器适应未知的任务
在这个实验中,我们评估了训练有素的编码器对使用演示的未知任务的适应程度。在这个实验中,我们在下图所示的9个测试任务中评估了编码器,并为每个任务收集了20个演示。在这个实验中,我们比较了所提出的方法与普通离线RL(AWAC)训练方法的性能。结果如下图所示,这表明总体而言,所提出的方法取得了更高的成功率。
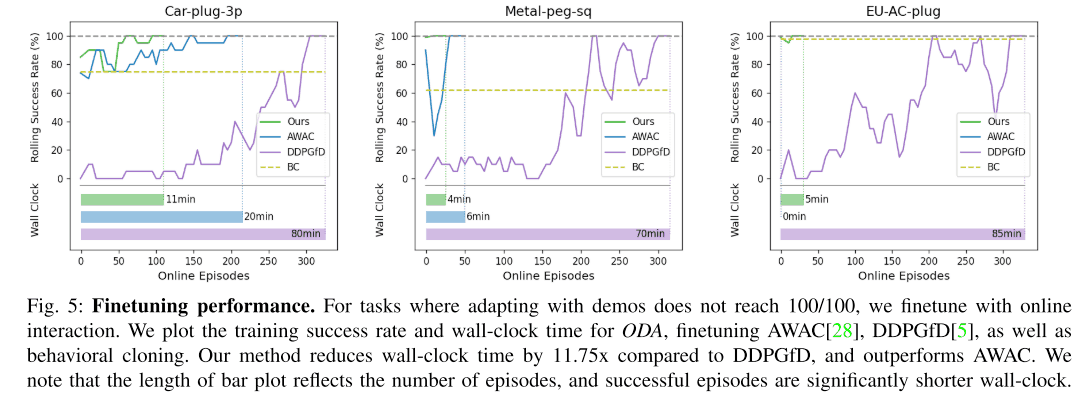
通过微调适应分配外的任务
在这个实验中,我们评估了当测试时的任务与训练时的任务有明显不同时,微调是否能迅速适应这样的未知任务。我们比较了AWAC、DDPGfD和Behavior Cloning,它们都经过了预训练。下图显示,在三个任务中的两个任务中,提议的方法能更快地适应未知的任务,并达到100%的成功率。对于第三项任务,仅经过5分钟的微调,提议的方法就达到了100%的成功率。至于DDPGfD,为了达到100%的成功率对于DDPGfD来说,实现100%成功率所需的时间几乎与从头开始学习政策的时间相同。这表明在拟议的方法中使用离线RL方法的重要性。
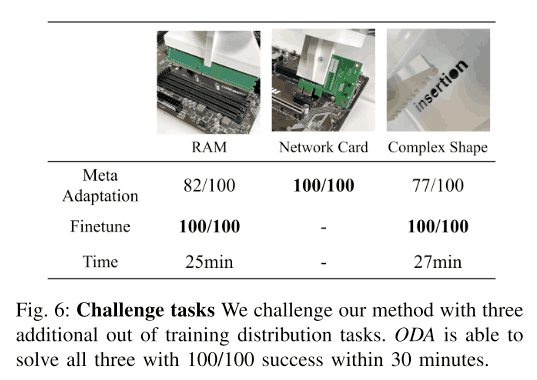
对于更困难的分配外任务
但更复杂的任务怎么办?在本文中,我们测试了以下三个任务。正如你在下图中看到的,我们在没有微调的情况下,网卡任务的成功率为100%,其他任务的成功率为70-80%,这些任务在经过大约25分钟的微调后也达到了100%的成功率。还需要注意的是,在微调过程中,主板不会被损坏。
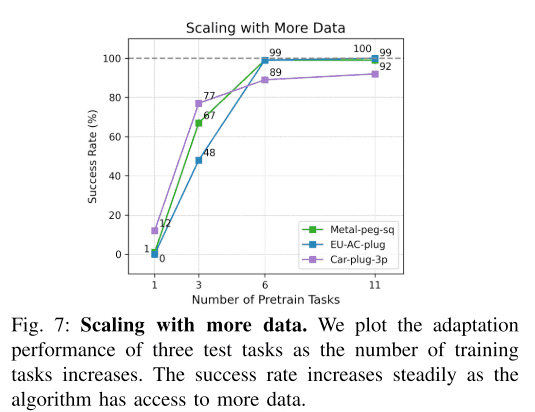
任务数与适应后的成功率之间的关系
最后,我们研究了任务与适应后的未知任务的成功率之间的关系。在这个实验中,我们没有使用微调,而只是演示。下图显示了这一结果。下图显示,当任务数为6时,成功率接近最大值,而当任务数较少时,成功率明显下降。因此,很明显,收集大量任务的训练数据对性能有很大影响。
摘要
本文解决了这一问题,特别是因为它不需要长时间的在线学习。我们认为这种方法非常有用,特别是因为它不需要对实际机器上的每个新任务进行长时间的在线训练。在这种方法中,对政策的观察是基于低维状态的,但它可能是解决以图像为输入的问题的一个关键。



与本文相关的类别






