一种通过分割强化学习任务来解决复杂任务的新算法!
三个要点
✔️提出了一个可以通过任务还原和自我模仿来高效解决复杂任务的SIR。
✔️对稀疏奖励问题有效。
✔️与对比方法相比,在操纵任务和迷宫任务上的表现较高。比较法
Solving Compositional Reinforcement Learning Problems Via Task Reduction
written by Yunfei Li, HUazhe Xu, Yilin Wu, Xiaolong Wang, Wi Wu
(Submitted on 26 Jan 2021)
Comments: Accepted to OpenReview
Subjects: compositional task, sparse reward, reinforcement learning, task reduction, imitation learning


Datasets

介绍
以下是一篇被ICLR 2021接受发表的论文。近年来,强化学习解决复杂任务的能力越来越强,但大多数方法需要精心设计奖励函数。这种奖励函数的问题是,它们需要特定领域的任务知识。另外,也有一些方法,如Hierarchical RL(层次强化学习),学习低级技能,学习高级政策使用哪些技能。然而,学习这种低级技能并不是一个简单的问题。在本文中,我们介绍了一种名为Self-Imitation via Reduction(SIR)的方法,它可以解决由多个任务(组成结构)组成的稀疏奖励问题。
技巧
SIR由两个主要部分组成:任务还原和imtiation学习。任务还原在参数化的任务空间中使用组成性来简化一个不可解的任务还原在参数化的任务空间中,利用构图性(构图原理),将一个无法解决的困难任务简化为一个已经知道如何解决的简单任务。然后,当一个困难的任务可以通过减少任务来解决时,就利用解决任务得到的轨迹进行模仿学习,以加快学习进程。下图是对象推送任务的任务减少概况。当任务简单时,只需直推蓝色物体就可以解决,但当任务困难时,由于棕色障碍物挡住了路,只推蓝色物体就不能解决。因此,我们首先在一个简单的任务(如左图所示)中解决棕色物体与初始状态不同的任务,然后,如果棕色物体阻挡了任务,我们进行任务还原,将棕色物体移动到一个可以解决任务的位置。如果棕色物体阻挡了任务,则将任务移动到可以解决的位置。在本章中,我们将详细解释这些任务减少和自我模仿。

减少任务
任务缩减将一个难以解决的任务$A \in \mathcal{T}$转化为代理可以学习解决的任务$B \in \mathcal{T}$,这样它只需要解决两个简单的任务就可以解决原来的任务$A$。换句话说,将任务$A$转换为$B$,然后解决任务$B$。为了更详细地解释这个问题,对于AGENT不能解决的任务$A$的初始状态$s_{A}$和目标$g_{A}$,寻找一个由初始状态$s_{B}$和目标$g_{b}$表示的任务$B$,并且$s_{B}$可以很容易地从$s_{A}$到达。这里,任务$B$的目标$g_{B}$与任务$A$的目标$g_{A}$相同($g_{B}=g_{A}$)。那么如何衡量任务$B$是否容易呢?这可以通过使用通用价值函数$V(\cdot)$来实现。换句话说,找到$s_{B}^{\star}$,使其满足下式。
$$s_{B}^{\star}=arg \max_{s_{B}}V(s_{A}, s_{B}) V(s_{B}, g_{A}):=arg \max_{s_{b}}V(s_{a}, s_{B}, g_{A})$$。
这里,$\oplus$表示commposition算子,有几种选择,最小值、平均值、乘积等,但本文用乘积表示$V(s_{A},s_{B},g_{A})=V(s_{A},s_{B})\cdot V(s_{B}, g_{A})$。以下是:
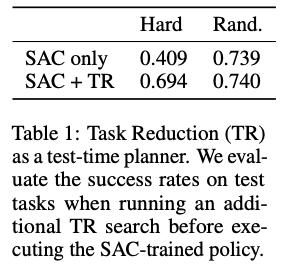
只要找到$s_{B}^{\star}$,代理就会从$s^{\star}_{A}$中运行$\pi(a|s_{A}, s_{B}^{\star})$。然后,在达到成功$s^{'}_{B}$后(即在$s_{B}^{\star}$附近),执行$\pi(a|s^{'}_{B}, g_{A})$,试图达到最终目标。然而,任务减少并不总是成功的,因为这两个策略的任何一个执行都可能失败。失败的原因可能有两个,一是价值函数的近似误差,二是任务A对于当前的策略来说实在太难。其次,可以提高样本效率,让任务减少只发生在有可能解决任务的时候。为了做到这一点,当$V(s_{A}, s_{B}^{\star}, g_{A})$超过阈值$\sigma$时,进行任务缩减。
自我模仿
如果对一个困难的任务$A$进行任务还原,成功地找到$s_{B}^{\star}$,那么从$s_{A}$和$s^{'}_{B}$两个轨迹,$s^{'}_{B}$。从$g_{A}$。然后,将这两个轨迹结合起来,就可以得到一个原始任务的演示。因此,通过收集这些示范,可以将模仿学习应用到这些收集的自我示范中。在本文中,我们使用由$A(s,g)$加权的模仿学习的目标函数如下。
$$L^{il}(\theta; \mathcal{D}^{il})=\mathbb{E}_{(s, a, g) \in \mathcal{D}^{il}}[\log \pi (a | s, g)]A(s, g)_{+}$$
在这里,$A(s,g)$代表削价优势,计算公式为$max(0,R-V(s,g))$。这种自我模仿可以让代理人高效地解决困难的任务。
SIR:通过减少任务进行自我模仿。
SIR可用于政策内和政策外的RL。在本文中,实验了软行动者批判(SAC)和接近政策梯度(PPO)。一般来说,RL算法使用收集到的推出数据$\mathcal{D}^{rl}$来学习演员-批评家。我们用$L^{actor}(\theta; \mathcal{D}^{rl})$和$L^{critic}(psi; \mathcal{D}^{rl})$来表示这个损失函数。
非政策RL只需将收集到的演示与经验回放数据对齐,并优化以下目标函数。
$$L^{SIR}(\theta; \mathcal{D}^{rl}, \mathcal{D}^{il})=L^{actor}(\theta; \mathcal{D}^{rl} \cup \mathcal{D}^{il}) + \beta L^{il}(\theta; \mathcal{D}^{rl} \cup \mathcal{D}^{il})$$
由于政策上的RL确保模仿学习只在收集到的演示上进行,并且由于$\mathcal{D}^{il}$的数据集大小基本上小于$\mathcal{D}^{rl}$的大小,所以以下加权目标函数用于每个损失函数。
$$L^{SIR}(\theta; \mathcal{D}^{rl}, \mathcal{D}^{il})=\frac{||\mathcal{D}^{rl}||L^{actor}(\theta; \mathcal{D}^{rl}) + ||\mathcal{D}^{il}||L^{il}(\theta; \mathcal{D}^{il})}{||\mathcal{D}^{rl}\cup \mathcal{D}^{il}||}$$
实验
在这个实验中,在三个不同的MuJoCo模拟环境中比较了SIR和不减少任务的基线方法:"推"任务,即机器人在清除障碍物后推送物体,"堆"任务,即机器人堆放物体,最后是"迷宫"任务。任务,机器人清除障碍物后推送物体,"堆叠"任务,机器人将物体堆叠起来,最后是"迷宫"任务。所有的任务都是稀疏奖励问题,即只有解决了任务,才给予1元的奖励,否则给予0元的奖励。作为基线方法,我们使用SAC来处理Push和Stack任务,使用PPO来处理Maze。
推送方案
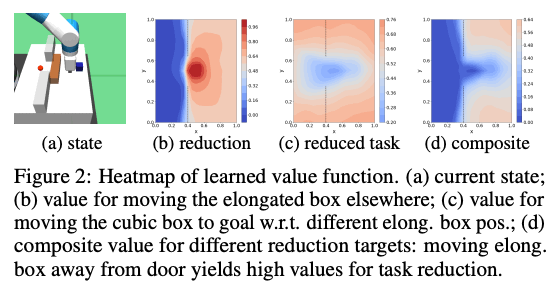
如下图所示,环境中有两个物体,一个是蓝色物体,一个是棕色拉长物体,机器人要把蓝色物体移动到红点的位置。在下图中,(b)表示移动拉长物体的学习值,(c)是关于不同拉长物体位置的蓝色物体移动到目标的学习值,(d)是综合值。
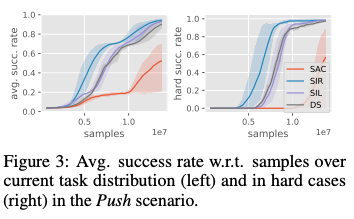
下图显示了这个任务的结果,其中左图显示了从困难任务和简单任务中随机抽样时的表现,右图显示了只使用困难任务的表现。右图是只使用困难任务的表现,下图中的SIL是SAC和Self-Imitation的组合,没有减少任务。DS代表了SAC被密集奖励训练的情况。从下面的结果可以看出,SIR能够更高效地解决困难的任务。
堆栈方案
在这个任务中,最多得到三个不同颜色的物体,必须将这些物体堆叠起来,使与目标颜色相同的物体到达目标。在这个任务中,物体的数量,它们的初始位置,以及它们的颜色都是随机指定的,每个情节。由于这个任务本身就很难,所以增加了一个取放任务作为辅助任务,这样一开始70%的任务由取放任务解决,剩下的由堆栈任务解决。随着学习的深入,采放任务的比例会不断降低,最终会降低到30%,让学生学会这项任务。

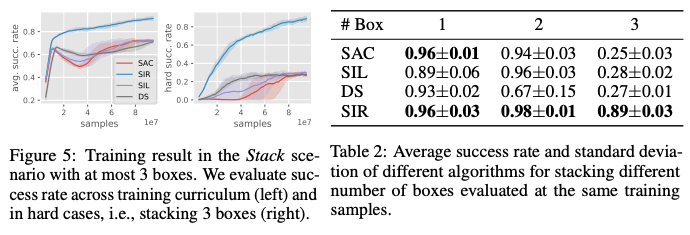
从下图可以看出,所提出的方法SIR即使在对象数量为3个时,也能成功地解决任务,且准确率很高,而其他方法的成功率随着对象数量的增加而降低,尤其是在对象数量为3个时。
迷宫场景
在这个迷宫任务中,要把绿色的物体推到红色的目标上才能解决任务。为了进入下一个房间,玩家必须将绿色物体推到红色的目标上,最后,为了解决任务,玩家必须将绿色物体推到红色目标上。在这项任务中,有一个困难的情况是,当物体必须移动到另一个房间,而至少有一扇门被长长的窄墙挡住。
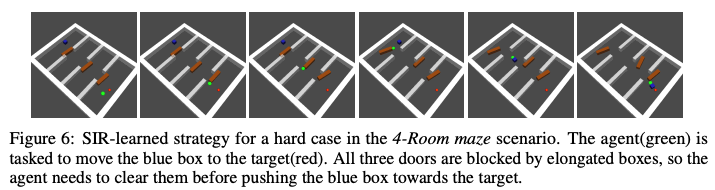
在下面的右图中,左图是包含了任务的所有难点和易点案例时的成功率,右图是只包含难点案例的结果。从结果可以看出,在困难任务情况下,提出的方法的成功率相对高于其他方法,而其他方法的成功率较低。此外,我们已经在下图右图所示的U-Wall迷宫上训练了所提出的方法。从下图右侧的图中可以看出,提出的方法SIR在任务中的成功率最高,这说明了这种方法的有效性。
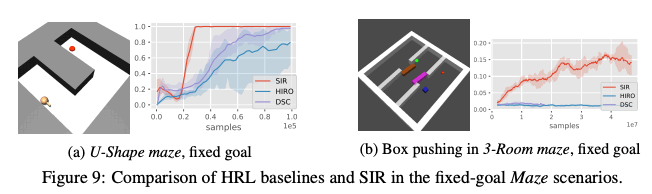
此外,在下图所示的U形迷宫和固定目标的3-Room迷宫中,比较了SIR与HIRO、层级RL(Hierarchical RL)和DSCtode。因此,如下图所示,SIR的精度高,采样效率高,而其他方法的采样效率差,无法达到同样的成功率。
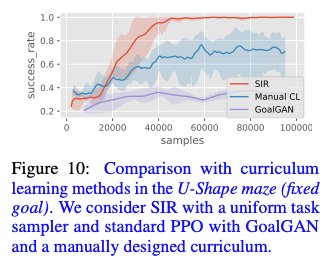
与课程学习的比较
所提出的方法SIR是先解决一个简单的任务,然后将一个困难的任务划分为已经解决的任务进行任务还原。因此,在有固定目标的U-maze任务中,将所提出的方法与使用SIR和课程学习的Goal-GAN以及手动创建课程的Manual CL进行了比较。从下图所示的结果可以看出,所提出的方法SIR显示出很高的成功率。
摘要
在本文中,我们介绍了一种名为SIR的方法,它将一个困难的任务拆分为已经解决的问题和待解决的任务,通过任务还原来解决。RL在相对简单干净的环境中学习效果很好,但在复杂的环境中,比如本文中的环境中,学习效果就不是很好。我们认为这是一个非常重要的课题,因为很多现实世界的问题也是复杂的环境。



与本文相关的类别






