由深度强化学习训练的机器人能否在工厂中用于组装任务?
三个要点
✔️ RL算法在NIST装配基准上进行了大规模的评估,在13K次试验中显示了99.8%的成功率。
✔️ 提出了一个名为SHIELD的框架,对DDPGfD进行了修改。
✔️ 与人类在两个更难的任务上的表现进行比较,显示了RL的有用性。
Robust Multi-Modal Policies for Industrial Assembly via Reinforcement Learning and Demonstrations: A Large-Scale Study
written by Jianlan Luo, Oleg Sushkov, Rugile Pevceviciute, Wenzhao Lian, Chang Su, Mel Vecerik, Ning Ye, Stefan Schaal, Jon Scholz
(Submitted on 21 Mar 2021 (v1), last revised 31 Jul 2021 (this version, v4))
Comments: RSS 2021
Subjects: Artificial Intelligence (cs.AI); Robotics (cs.RO)
code:
本文所使用的图片要么来自论文、介绍性幻灯片,要么是参考这些图片制作的 。
简介
目前,机器人在工厂中被用于将零件插入产品的任务,这可以通过在受限环境中预先编程机器人的技能来解决。然而,这种编程的时间和成本非常高,这使得机器人难以用于大规模的生产,但不能用于小批量生产。
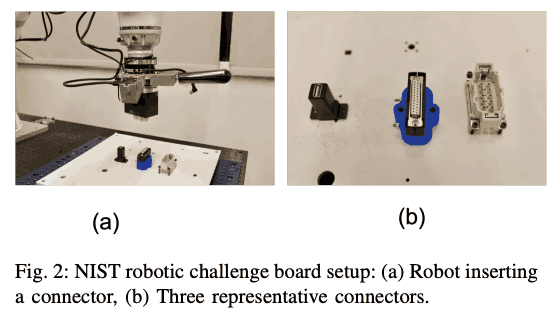
另一方面,深度强化学习在最近几年受到了很多关注,因为用较少的工程量来学习解决一个任务所需的技能已经成为可能。然而,尽管正在进行所有的研究,但人们认为它还没有达到可以实际用于工业的水平,也没有衡量它是否可以用于工业的基准。如下图所示,NIST的装配基准提供了一套有代表性的工业装配任务和这些任务的评价指数。
首先,DRL在解决工业组装任务中的重要性是什么?在本文中,我们重点关注三件事
1) 高效:假设必须是非政策性RL,而且算法必须能够通过给出任务的先验信息快速解决任务RL。在本文中,"示范 "被作为先验信息给出。
2) 经济性:用现有方法无法解决的问题,其解决方案是否真的可以部署。
3) 评估:应使用与实际行业相关的指标,如可靠性和周期时间,在工业基准中对所提出的方法进行评估。
在本文中,我们提出了一种名为SHIELD的新方法来评估DRL(深度强化学习)在这个NIST基准中的有效性。
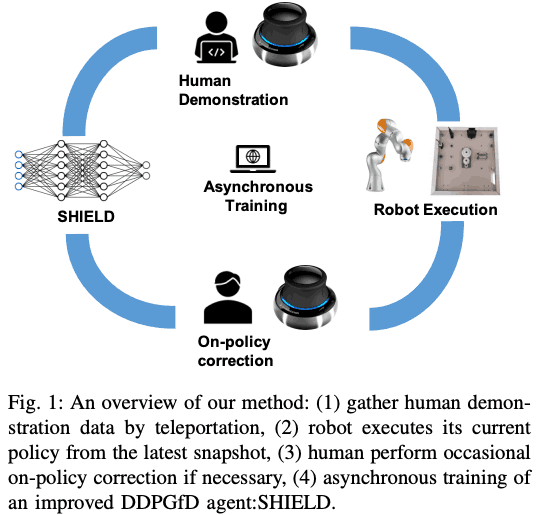
方法
该方法的总体情况如下图所示。流程按以下顺序进行
- 收集人类的演示,并将其存储在重放缓冲区。
- (可选)如果图像包含在RL输入中,那么图像的特征将使用演示进行预训练。
- 在你的环境中运行当前的政策并收集数据
- 如果有必要,由人类进行政策上的修正,以纠正机器人的错误。
- (可选)做课程学习
- Actort和Critic的训练是与数据收集异步进行的。
从示范中强化学习
为了训练RL代理,需要定义奖励,特别是定义形状的奖励函数是非常耗时的。另一方面,稀疏的奖励很容易定义,但很难探索。为了解决这个问题,在各种研究中,演示被用作解决搜索问题的一种方式。在本文中,我们使用了从示范到确定的政策梯度(DDPGfD)方法,主要是将以下算法中的红字修改为原来的DDPGfD,以便使用这种示范。使用了以下算法

更详细的变化如下
- 添加到行为者网络中的高斯噪声已被去除,并采用了确定性的政策。其原因是,由于噪音的存在,随机策略对于狭窄的路径,如插入任务,可能并不高效。
- 而不是使用优先级重放缓冲器,重放缓冲器中的所有样本都有相同的重要性。
- 通过逐步提高任务和行动空间的难度来引入课程学习。
- 在政策纠正方面,人类使用控制器移动机器人,以推翻政策的行动,例如,当机器人即将大幅偏离任务解决行动时。
相对坐标和目标随机化
为了防止策略对特定的绝对坐标进行过度学习,我们不给机器人在基本框架中的姿势信息作为策略的输入,而是给相对于重置机器人时的姿势信息。相反,我们使用相对于机器人的重置姿势的姿势信息作为输入。从机器人的角度来看,这可以被视为移动任务的目标,即本文中插座的位置,其优点是机器人可以为各种目标进行学习,而不需要每次都移动目标位置。
预先训练视觉特征
在以前的一篇论文中,通过从图像中学习策略成功地解决了一个USB插入任务,但要达到80%的成功率需要大约8小时。因此,在这项研究中,我们使用以前收集的示范和额外的数据来训练VAE,对图像特征进行预训练。然后,我们固定预训练编码器的权重,用它来学习策略。这使我们有可能更有效地学习政策。
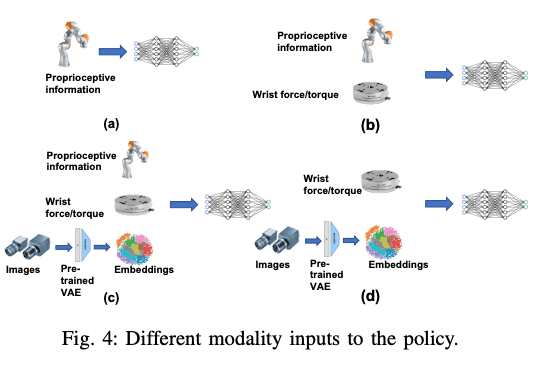
多式联运政策
最后,让我们来谈谈政策的投入。在本文中,我们尝试了以下四种模式
(a) 只有机器人的姿势信息
(b) 姿势信息 + 腕力/扭矩腕部力/扭矩
(c) 姿势信息+腕部力/扭矩+腕部摄像机图像
(d) 腕部力/力矩+腕部相机成像。
实验
在本文中,该方法在三个任务上进行了评估;NIST电路板插入任务、移动目标HDMI插入和钥匙锁插入。
NIST板的插入
任务设置如下图所示,有三种不同的输入;(1)本体信息(姿势信息),(2)本体信息+手腕力/扭矩,以及(3)本体感觉信息+手腕力/扭矩+视觉。
学到的策略被评估为成功的,与训练时一样在机器人的位置上添加了噪音。我们还评估了机器人的工具中心点(TCP)相对于原始方向沿Z轴移动45度时的成功率。此外,为了评估该策略以训练过的图像为输入的通用性,我们评估了在评估过程中手动移动NIST板时的解决效果。
在这个实验中,我们使用了库卡iiwa手臂,由末端执行器笛卡尔速度控制,使用阻抗控制器。如果你对供应商的评估细节感兴趣,请参考该文件。
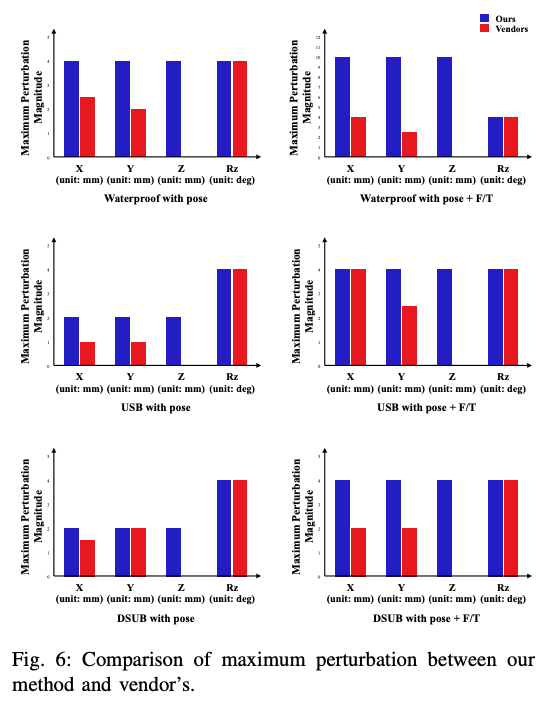
即使是这种预设的供应商的方法也能基本解决任务。然而,这里重要的是供应商的方法的泛化性能是否很高,即它是否对扰动等具有鲁棒性。下图显示了在保持几乎100%的成功率的情况下,建议的方法和供应商的方法可以容忍多少扰动,这表明建议的方法与RL具有更好的泛化性能。
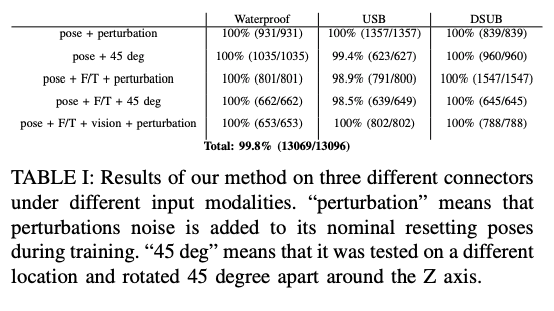
下图显示了每个连接器(防水、USB、DSUB)的每种模式的成功率,在13096次试验中共有13069次成功(99.8%)。
动态插入
在这个实验中,我们测试了所提出的方法是否能快速适应NIST装配板的运动,并在NIST装配板被人的手移动时解决任务,如下图所示,使用图像作为输入。因此,在50次试验中,我们取得了95%的成功率。失败的主要原因是,NIST检测板用手移动的速度太快,机器人无法适应这种移动。

移动HDMI的插入
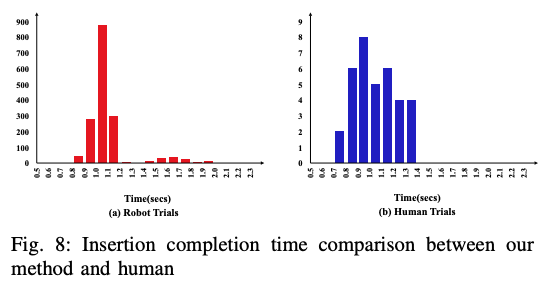
在之前的实验中,我们测试了所提方法的稳健性,但在真实的工厂中,周期时间(生产速度)是很重要的。在这个实验中,我们比较了两个机器人执行HDMI插入任务和一个人将HDMI连接器插入机器人所持的插座的周期时间(见下图)。在这项任务中,IIWA机器人拿着HDMI连接器,Sawyer手臂(在左边)拿着HDMI插座。Saywer手臂在垂直于插入方向的平面上做随机的圆形运动,IIWA机器人的任务是插入其中。
然而,从头开始学习这个任务是非常困难的,所以我们使用任务空间课程和行动空间课程进行课程学习。
在任务空间课程中,我们从固定索伊尔的初始位置和运动开始,通过增加初始位置的扰动和增加圆形运动的速度,逐渐增加任务的难度。最后,插座初始位置的范围增加到-+6厘米,速度增加到2.5厘米/秒。
在行动空间课程中,如果从一开始就把策略的行动空间做得很大,那么机器人就有可能与之相撞,并打破它,等等。因此,我们从一个小的行动空间开始学习,并以指数方式增加行动的大小我们从一个小的行动空间开始,以指数方式增加行动空间的大小。这使我们能够提高政策的可靠性。
结果,该药剂在1637次试验中取得了100%的成功率,平均插入时间为1093ms。相比之下,人类用HDMI解决该任务的平均周期时间为1041ms,这证实了所提出的方法的周期时间与人类的周期时间相当。

钥匙锁的插入
在以前的实验中,我们使用了一定大小和材料的物体,但在这个实验中,我们使用了普通的家用钥匙进行插入(见下图)。这个实验的目的是看当插入部分的表面很小,而策略必须通过增加扰动来搜索很长的距离时,是否可以解决插入任务。在这个实验中,初始位置总是离钥匙5厘米远(Z轴),X轴和Y轴是随机采样确定的。在这个实验中,本体感觉信息和手腕的力量/扭矩被用来作为训练政策的输入。
在这个实验中,和上一个实验一样,我们使用课程学习来增加任务的难度,在X/Y轴上的$b$和$b$之间随机抽样,从$b=0$开始,逐渐增加,直到最后达到$b=0.5$。
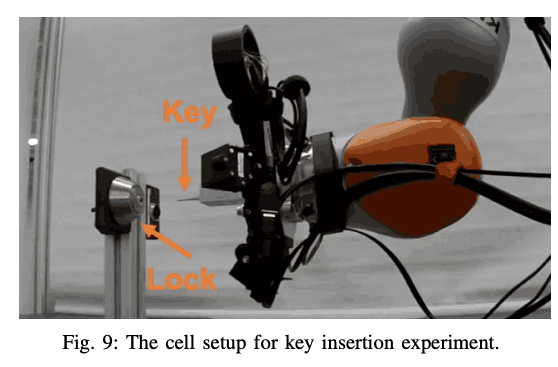
实验的最终结果显示如下。下面的结果表明,即使是小的物体,如钥匙,也能达到相对较高的成功率。

摘要
在本文中,我们使用NIST装配基准,通过大量的试验来评估RL在解决工业插入任务方面的能力。然而,存在各种问题,如需要将连接器固定在机器人上,需要学习每个连接器的策略。
作者的评论
关于摘要中指出的问题→然而,还有各种问题,如需要将连接器固定在机器人上,需要学习每个连接器的策略。
作者已经在下面的论文中进行了研究,我建议你也读一读!
Offline Meta-Reinforcement Learning for Industrial Insertion
written by Tony Z. Zhao, Jianlan Luo, Oleg Sushkov, Rugile Pevceviciute, Nicolas Heess, Jon Scholz, Stefan Schaal, Sergey Levine
(Submitted on 8 Oct 2021 (v1), last revised 12 Oct 2021 (this version, v2))
Subjects: Robotics (cs.RO)![]()
![]()
code: ![]()



与本文相关的类别






