
RT-1机器人学习系统根据图像和自然语言进行操作。
三个要点
✔️ 基于Transformer的机器人学习系统,使用一个移动的机械臂机器人Transformer 1
✔️ 从图像和自然语言指令生成机械臂运动和任务管理
✔️ 机器人的实时控制模型和现实世界中的使用机器人任务的数据集对该模型进行归纳。
RT-1: Robotics Transformer for Real-World Control at Scale
written by Anthony Brohan, Noah Brown, Justice Carbajal, Yevgen Chebotar, Joseph Dabis, Chelsea Finn, Keerthana Gopalakrishnan, Karol Hausman, Alex Herzog, Jasmine Hsu, Julian Ibarz, Brian Ichter, Alex Irpan, Tomas Jackson, Sally Jesmonth, Nikhil J Joshi, Ryan Julian, Dmitry Kalashnikov, Yuheng Kuang, Isabel Leal, Kuang-Huei Lee, Sergey Levine, Yao Lu, Utsav Malla, Deeksha Manjunath, Igor Mordatch, Ofir Nachum, Carolina Parada, Jodilyn Peralta, Emily Perez, Karl Pertsch, Jornell Quiambao, Kanishka Rao, Michael Ryoo, Grecia Salazar, Pannag Sanketi, Kevin Sayed, Jaspiar Singh, Sumedh Sontakke, Austin Stone, Clayton Tan, Huong Tran, Vincent Vanhoucke, Steve Vega, Quan Vuong, Fei Xia, Ted Xiao, Peng Xu, Sichun Xu, Tianhe Yu, Brianna Zitkovich
(Submitted on 13 Dec 2022)
Comments: Published on arxiv.
Subjects: Robotics (cs.RO); Artificial Intelligence (cs.AI); Computation and Language (cs.CL); Computer Vision and Pattern Recognition (cs.CV); Machine Learning (cs.LG)
code:

本文所使用的图片要么来自论文、介绍性幻灯片,要么是参考这些图片制作的。
介绍
最近,你听到很多关于在计算机视觉、自然语言处理和语音识别中使用人工智能的技术。我们也可能已经看到更多的机器人(无人机和餐饮机器人)使用这些技术。然而,众所周知,在机器人技术中,机器学习模型是很难普及的。其中一个原因是,需要收集真实世界的数据来概括模型。
在机器人技术中推广模型的两个挑战是
- 收集适当的 数据集 --需要在规模和广度上涵盖一系列任务和环境的数据集 。
- 设计适当的模型 --需要足够高效的模型来实时操作,并且足够大,适合多任务的学习。
作为这些问题的解决方案,本文介绍的Robotics Transformer 1(以下简称RT-1)构建了一个能够实时控制机器人的模型,并通过使用从现实世界中广泛的机器人任务中获得的数据集,使模型更接近泛化。
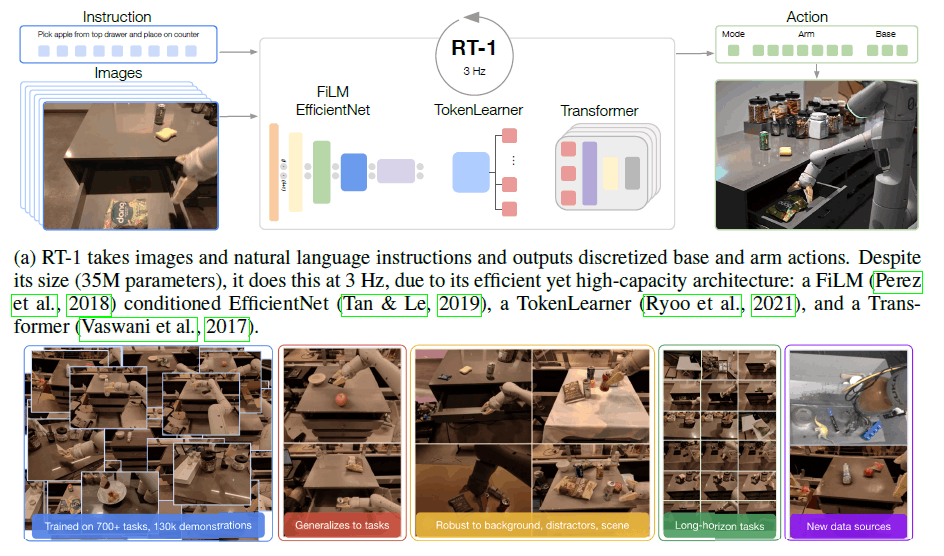
概述
这项研究的目标是建立并展示一个通用的机器人学习系统的性能,该系统可以捕获大量的数据并有效地进行概括。所用的机器人是一个来自Everyday Robots的移动机械手,它有一个7-DOF的手臂,一个双指的手抓器和一个移动底座。(如下图(d))

RT-1是一个高效的模型,它可以吸收大量的数据,有效地进行概括,并以实时速率输出行动,用于实际的机器人控制。它将简短的图像序列和自然语言指令作为输入,并在每个时间步骤中输出机器人动作。
RT-1架构
下图显示了RT-1模型的结构。该模型的组成部分从图的顶部开始描述。
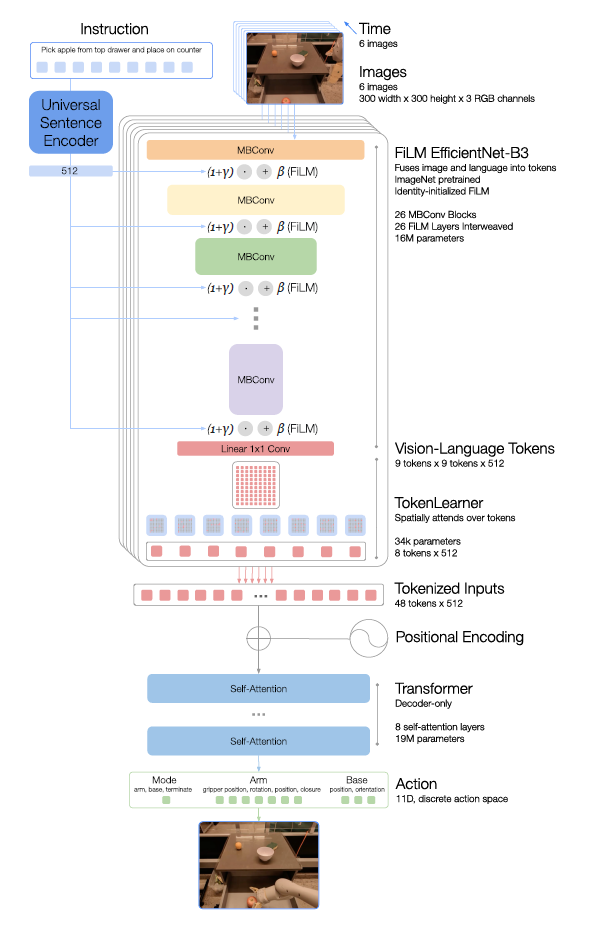
指令和图像标记化
RT-1架构依赖于对图像和语言指令的数据高效和紧凑的标记化:6张分辨率为300×300的图像被输入到Images,通过ImageNet的预训练EfficientNet-B3模型,最后一个卷积层产生的形状9×x 9 x 512的空间特征图被输出。
指令是以自然语言作为指令填充的。该指令由通用句子编码器进行自然语言处理,并被用作身份初始化的FiLM层的输入,该层被添加到预训练的EfficientNet中用于图像编码器的调节。
符号学习者(TokenLearner
TokenLearner用于进一步压缩RT-1需要关注的标记数量,并加快推理速度。TokenLearner学习将大量的标记映射为较少的标记。Element-Wise注意模块。这允许只将重要的标记组合传递给转化器层。
转换器
Transformer是一个只有解码器的序列模型,有8个自我注意层和19M个参数,输出动作标记。
行动标记化
为了标记动作,RT-1中的每个动作维度都被离散成256个仓。对于每个定义的变量,例如机器人手臂的运动,目标被映射到256个仓中的一个。
损失
使用标准的分类交叉熵目标和基于变压器的控制器在相关研究中所利用的因果掩码。
推断速度
将推理时间预算设定为小于100毫秒,这接近于人类执行相同动作的速度(大约2-4秒)。
这个过程根据输入的图像和指令(自然语言)生成机器人手臂的动作。 使用的数据集和发送给机器人的指令以及机器人执行的动作(技能)如下。
数据集
主要数据集包括在17个月内用13个机器人收集的约13万个机器人演示。这种广泛的数据收集是在办公室的厨房里进行的,如下图(a)-(c)所示。还提供了各种物体以增加机器人手臂运动的多样性,如下图(e)、(f)所示。
技能和指示
它计算的是系统可以执行的语言指令的数量。这些指令对应于被一个或多个名词包围的动词,可以是诸如 "把水瓶竖起来"、"把可乐罐转移到绿色薯片袋上"、"打开抽屉 "等句子。在实验中评估的几个真实的办公室厨房环境中,RT-1可以执行700多条语言指令。它可以执行700多条口头指令。
实验和结果
针对RT-1模型的性能,制定了以下实验政策。
- 执行可见的任务。
- 隐蔽性任务的一般化。
- 稳健性
- 长线方案
基于上述情况,RT-1在三个环境中使用Everyday Robots移动机械手进行了评估:两个真实的办公室厨房和一个模仿这些真实厨房的训练环境。本文包括RT-1和基线的性能比较,以及用模拟环境的数据对数据集进行补充时的结果。
RT-1和基线的总体性能比较
所有的模型都是在与RT-1相同的数据上训练的,评估不比较任务集、数据集或整个机器人系统,只比较模型架构。

在该类别中,RT-1明显优于其前辈。在边看边做的任务中,RT-1在200多条指令中成功了97%,这比BC-Z高25%,比Gato高32%。这种对新指令的概括性使该策略能够理解已经看到的概念的新组合。所有的基线也是自然语言条件下的,原则上享有同样的好处。
一个RT-1代理轨迹的例子,包括涵盖不同技能、环境和对象的指令,在板图中显示。

仿真数据被纳入RT-1时的实验结果

与Real Only数据集相比,可以看出,性能并没有随着模拟数据的加入而降低。然而,模拟上的对象和任务的性能有了明显的提高,从23%提高到87%,这几乎与真实数据的性能相同。未知指令的性能也有明显改善,从7%到33%。考虑到对象在真实数据和未知指令上得到了验证,这是一个有趣的结果。
结论
虽然RT-1对大规模的机器人学习与数据吸收模型做出了贡献,但它也有一些局限。作为一种模仿学习方法,它继承了该方法的挑战,如可能无法超过演示者的性能。此外,对新指令的归纳仅限于以前未见过的概念的组合,RT-1无法归纳到完全未知的新行为。
然而,RT-1可以进行升级,以进一步提高其对背景和环境的稳健性。出于这个原因,RT-1是开源的,任何人都可以为其发展做出贡献。
我们相信,不仅是研究人员,企业和普通用户也会对RT-1的技术发展负责,这将使模型从不同角度构建,并进一步通用。如果各种技术能够融合在一起,机器人模型能够被泛化,那么用不了多久,机器人就会在城市中普及。



与本文相关的类别



![[HumanoidBench] 模拟仿人](https://aisholar.s3.ap-northeast-1.amazonaws.com/media/June2024/humanoidbench-520x300.png)

