
VLMaps 可直接在 3D 地图上进行标注,从而提高准确性。
三个要点
✔️ VLMap:空间地图表示法,将真实世界的三维地图与预先训练的视觉语言模型特征相结合
✔️ 可与 LLM 结合生成移动机器人行为
✔️ 大量实验表明,与现有方法相比,它能遵循更复杂的语言指令可以导航
Visual Language Maps for Robot Navigation
written by Chenguang Huang, Oier Mees, Andy Zeng, Wolfram Burgard
(Submitted on 11 Oct 2022 (v1), last revised 8 Mar 2023 (this version, v4))
Comments: Accepted at the 2023 IEEE International Conference on Robotics and Automation (ICRA)
Subjects: Robotics (cs.RO); Artificial Intelligence (cs.AI); Computation and Language (cs.CL); Computer Vision and Pattern Recognition (cs.CV); Machine Learning (cs.LG)
code:
本文所使用的图片要么来自论文、介绍性幻灯片,要么是参考这些图片制作的。
介绍。
近年来,利用人工智能生成机器人行为的研究层出不穷。例如,行为生成通常涉及一个人命令一个移动机器人从桌子上拿一个苹果,然后移动机器人把苹果拿过来。这种移动机器人行为生成使用自然语言处理来处理命令,并使用图像处理人工智能来识别物体。预训练的视觉语言模型可用于此类导航。
然而,现有的视觉语言模型虽然有助于将图像与物体目标的自然语言描述相匹配,但仍然与绘制环境地图的过程脱节,因此缺乏几何地图的空间精度。
本文介绍的 VLMaps 是一种空间地图表示法,它将预先训练的视觉语言模型特征与物理世界的三维重建相结合,从而解决了这些问题。
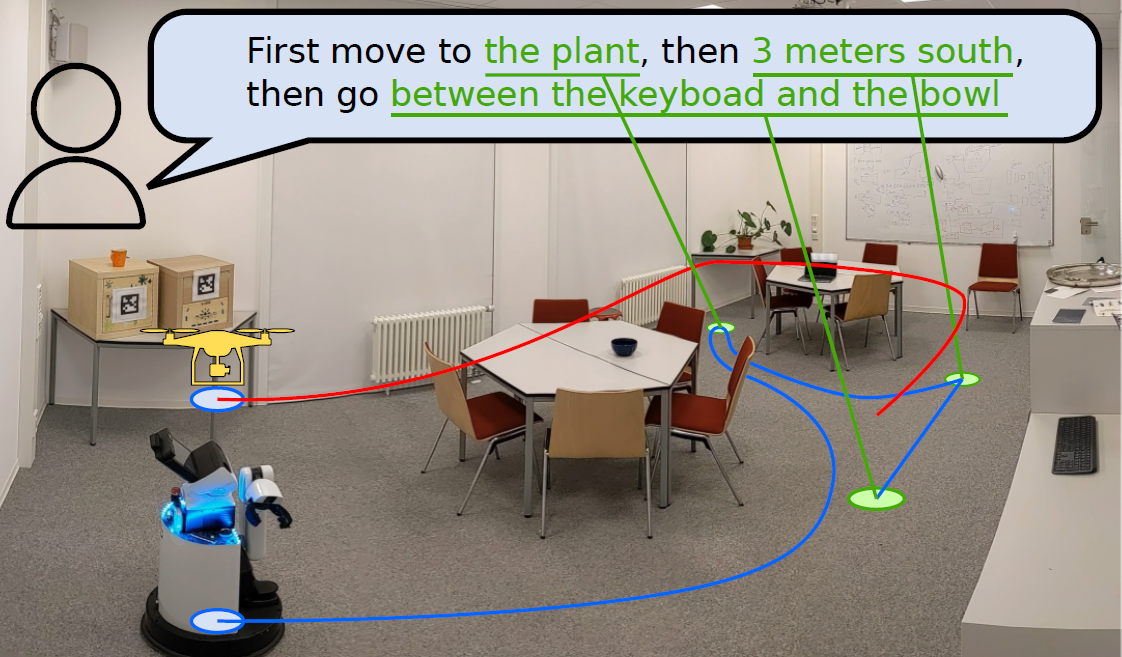
VLMaps 概览。
VLMaps 是一种针对这些问题的空间地图表示法,它将预先训练的视觉语言模型特征与物理世界的三维重建相结合。
它可以使用标准的搜索方法,从机器人的视频画面中自主建立,无需额外的标注数据,就能对地图进行自然语言索引。

具体来说,结合大规模语言模型(LLM),可以
- 将自然语言命令转换为一系列开放词汇导航目标,并直接在地图上定位。例如,"沙发和电视之间 "或 "椅子右侧 3 米处"。
- 要生成新的障碍物地图,无需事先准备,可以使用一个障碍物类别列表,多个机器人可以共享不同的实现方式。
VLMaps 方法
VLMaps 的目标是建立空间视觉语言地图表示法,可以直接识别自然语言中的地标("沙发")和空间参照物("沙发和电视机之间")。VLM 可以使用现成的视觉语言模型(VLM)和标准 3D 重建库构建。
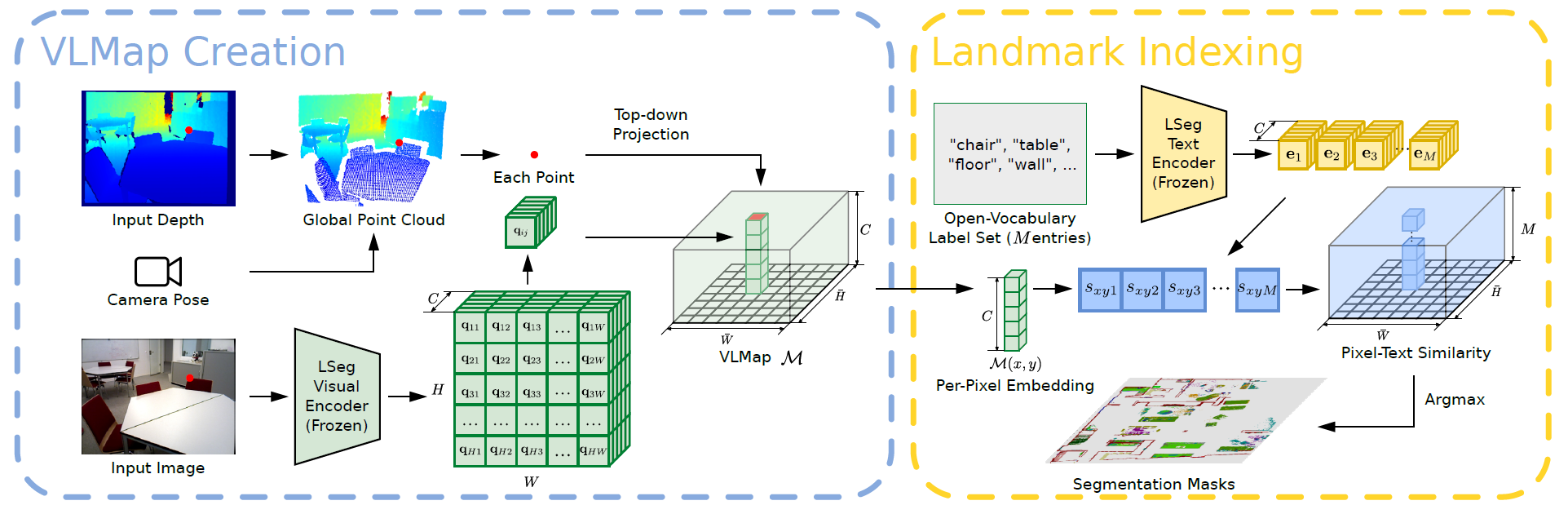 下面我们将介绍 VLMaps 的方法,具体分为以下几个部分。
下面我们将介绍 VLMaps 的方法,具体分为以下几个部分。
- 如何绘制 VLM
- 如何使用地图定位开放词汇地标。
- 从不同机器人实施例的障碍物类别列表中构建开放词汇障碍物地图的方法。
- 如何将 VLMaps 与大规模语言模型 (LLM) 结合使用,根据自然语言指令为真实机器人执行零点空间目标导航。
构建可视化语言地图
VLMaps 背后的主要理念是将预先学习的视觉语言特征与三维重建相结合。具体做法是根据现有的视觉语言模型计算机器人视频馈送中的高密度像素级嵌入,并将其反向投影到从深度数据中捕捉到的环境三维表面上。
VLMaps 使用 LSeg 作为视觉语言模型,这是一种语言驱动的语义分割模型,可根据一组自由形式的语言类别分割 RGB 图像。
VLMaps 方法将 LSegs 的像素嵌入与相应的 3D 地图位置相结合。这将强大的语言驱动语义先验与 VLM 的泛化能力结合在一起,而无需使用明确的人工分割标签。
其中,H 和 W 代表自上而下网格地图的大小,C 是每个网格单元的 VLM 嵌入向量的长度。加上比例参数 s,VLMapsM 代表的区域大小为 H × W 米。
为绘制地图,每个 RGB-D 帧都会反投影到每个深度像素 u 上,形成局部深度点云,然后将其转换为世界帧。
将点 PW投影到地平面上,即可得到网格地图上像素 u 的相应位置。下面是 px 地图和py 地图的计算公式,表示投影点在地图 M 中的坐标。
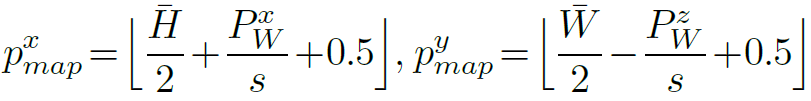
开放词汇地标本地化
本节介绍如何使用自由形式的自然语言定位 VLMaps 地标。
输入语言列表如["椅子"、"沙发"、"桌子"、"其他"]或["家具"、"地板"、"其他"]。为了将这些文本列表转换为矢量嵌入列表,需要使用预先训练好的 CLIP 文本编码器。地图嵌入也被平移到矩阵中。此外,每一行都代表自上而下网格地图中一个像素的嵌入。
最后的矩阵用于计算网格图中每个像素最相关的语言类别。
生成开放词汇障碍图
通过构建 VLMaps,可以生成障碍物地图,该地图继承了所使用的 VLMs(LSeg 和 CLIP)的开放词汇性质。具体来说,这是因为给定一个用自然语言描述的障碍物类别列表,就可以在运行时对它们进行定位,生成二进制地图,用于避免碰撞和规划最短路径。这方面的一个突出用例是,不同实现方式的机器人之间可以共享同一环境的 VL 地图,这对多机器人协调非常有用。
例如,只需提供两个不同的障碍物类别列表,一个用于大型移动机器人(包括 "桌子"),另一个用于无人机(不包括 "桌子"),就可以从相同的 VLMaps 中生成两个不同的障碍物地图,供两个机器人分别使用,而无需事先准备。可以
为此,首先要提取障碍物地图 O。其中,深度点云在自上而下地图中的每个投影位置都赋值为 1,否则赋值为 0。
为避免来自地板或天花板的点,点 PW 将根据其高度进行过滤。
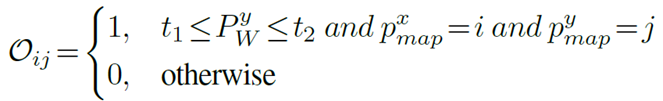
接下来,定义潜在障碍物类别列表,以获得适合特定实施方案的障碍物地图;应用开放词汇地标索引,以获得所有定义障碍物的分割掩码。在特定实施方案中,从整个潜在障碍物列表中选择一个类别子集,通过求取其分割掩码的总和来获得障碍物掩码;通过求取其与 O 的交集来忽略对 O 地面区域上障碍物的错误预测,从而获得最终的障碍物地图。
从语言出发的零点空间目标导航
本节将介绍我们的长视距(空间)目标导航方法,该方法给出了一组由自然语言指令指定的地标描述,例如

VLM 可以指精确的空间目标,如 "电视沙发之间 "或 "椅子东面 3 米处"。具体来说,LLM 用于解释传入的自然语言命令,并将其分解为子目标。然后,利用语义翻译和承受能力在语言中引用这些子目标,并利用 LLM 的代码编写功能为机器人生成可执行的 Python 代码。
机器人代码可以表示函数和逻辑结构,并对应用程序接口调用进行参数化。在测试过程中,模型可以接收新指令,并自主重新配置 API 调用,分别生成新的机器人代码。
在下面两张图中,提示符为灰色,输入任务命令为绿色,生成的输出高亮显示�
 |
 |
除了参考语言命令中提到的新地标外,LLMg 还通过连锁新的 API 调用序列,生成遵循未知指令的代码。
这样,语言模型调用的导航原始函数就可以使用预先生成的 VL 地图来确定地图中开放词汇地标的坐标,并用预先规定的偏移量进行修改。然后,它将使用一个现成的导航堆栈,以特定车身的障碍物地图作为输入,导航到这些坐标。
试验
本文介绍了 VLMaps 的基线比较以及在实践中将其应用于移动机器人的结果。
基线比较
在多目标导航的标准任务中,VLMaps 方法与最近的开放词汇导航基线进行了定量评估。
为评估物体导航,收集了 91 个任务序列。在每个序列中,随机指定机器人在一个场景中的起始位置,并从 30 个物体类别中选择 4 个作为子目标物体类型。
机器人需要依次浏览这四个子目标。在每个子目标序列中,当机器人到达一个子目标类别时,它必须调用一个停止动作来显示其进度。
如果停靠点与正确目标的距离在一米以内,则视为成功导航到一个子目标。
为了评估代理在长视野中的导航能力,我们计算了连续实现一至四个子目标的成功率(SR)(见下图)。
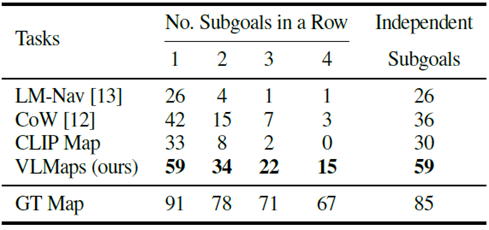
在多目标导航方面(成功率[%]),VLMaps 方法比其他开放词汇基线方法显示出更好的效果,尤其是在具有多个子目标的长期任务中。
LM-Nav 的性能也很差,因为它只能导航到存储在图节点中的图像所代表的位置。为了更好地理解基于地图的方法,下图显示了 VLMaps、CoW 和 CLIP Map 生成的对象掩码与 GT 的比较。

由 CoW(图:4d)和 CLIP(图:4c)生成的掩码都包含大量错误预测。由于规划生成的路径是通往最近的遮蔽目标区域,这些预测会导致规划走向错误的目标。相比之下,图 4e 所示的 VLMaps 所产生的预测噪声较小,因此能更成功地进行目标导航。
移动机器人实验
我们还利用高铁移动机器人进行了使用自然语言指令进行室内导航的真实世界实验,在包含 10 多种不同类别物体的语义丰富的室内场景中对 VLMaps 进行了测试。测试中定义了 20 种不同的基于语言的空间目标。
在推理过程中,RTAB-Map 的全局定位模块也用于初始化机器人姿态。
最终,六次成功的试验以空间为目标,如 "移动到椅子和箱子之间 "或 "移动到桌子南边";三次试验以机器人当前位置为目标,如 "向右移动 3 米,然后向左移动 2 米"。
结论
它是如何做到的?本文讨论的 VLMaps 可以将预先训练好的视觉语言模型的特征直接调整到三维地图上,这样就可以明确地识别出物体在地图上的位置。未来的研究有望朝着添加其他信息以进一步提高准确性的方向发展。
它还可以与 LLM 相结合,为移动机器人生成动作。未来,它不仅可能应用于机器人的动作生成,还可能应用于车辆的自动驾驶。



与本文相关的类别



![[HumanoidBench] 模拟仿人](https://aisholar.s3.ap-northeast-1.amazonaws.com/media/June2024/humanoidbench-520x300.png)

