物理嵌入式规划:强化学习的新挑战! 机器人能解决符号游戏吗?
三个要点
✔️提出RL环境下新的物理嵌入式规划问题
✔️提出解决问题的基准方法。
✔️专家规划师可以让你解决问题,但目前效率较差。
Physically Embedded Planning Problems: New Challenges for Reinforcement Learning
written by Mehdi Mirza, Andrew Jaegle, Jonathan J. Hunt, Arthur Guez, Saran Tunyasuvunakool, Alistair Muldal, Théophane Weber, Peter Karkus, Sébastien Racanière, Lars Buesing, Timothy Lillicrap, Nicolas Heess
(Submitted on 11 Sep 2020)
Comments: Accepted at arXiv
Subjects: Artificial Intelligence (cs.AI); Machine Learning (cs.LG)
Paper Official Code COMM Code
介绍
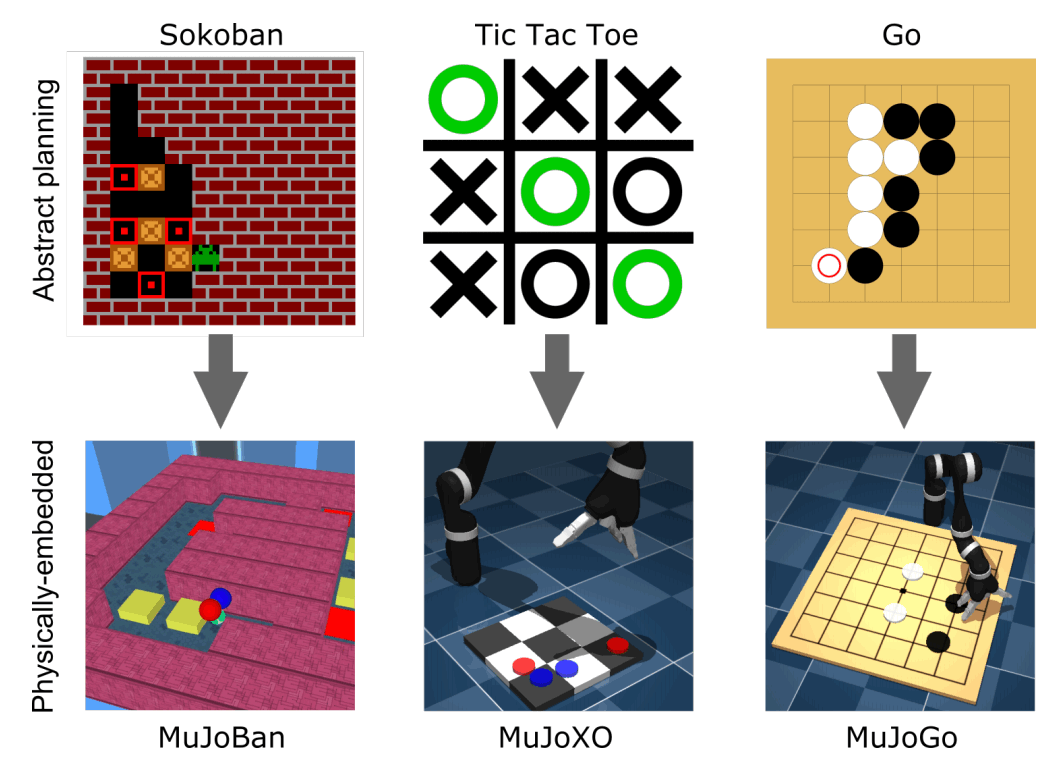
这里有一篇论文,提到了DeepMind提出的强化学习的新挑战。 说到著名的强化学习应用,大家首先想到的是DeepMind公司的Alpha Go,Alpha Go可以让你在围棋中学习到最佳的布局,实际上专业人士也在使用它。你可能还记得,它打败了一个围棋手。然而,在阿尔法围棋这样的游戏中,即使能找到最好的位置,但真正移动游戏的是人。在实际对战中,人类棋手根据Alpha Go的布局输出,在该位置下棋。机器人不是人,能不能抓起一个走,然后把它准确地放在它想放的地方?观察下图,我们可以看到,强化学习可以用符号代表游戏中的三个符号(白色是0,黑色是1等)分别解决游戏中的状态,但在游戏由机器人控制的情况下,能不能正确地完成呢?这些被称为物理嵌入式规划问题。这被认为是强化学习的难点,因为你必须在很长的范围内考虑到感知、推理和运动控制。DeepMind提供了一个提供这类问题的环境,有兴趣的朋友可以去看看。在这篇文章中,我们将更详细地解释这些问题,然后以论文中显示的一些简单的实验结果。
背景
本章介绍了运动控制的挑战,以及为什么在长视野任务中推理如此困难。
电机控制的挑战
机器人控制的研究范围很广。例如,许多研究都集中在机器人的灵巧性和长视野任务上。然而,结合机械臂的操作复杂度和长距离任务的研究还不多。另外,这类问题在图像等高维输入的情况下特别困难,当动作空间是连续的时候,问题就特别困难。基本上可以解决从图像输入到抽象信息(抓取物体、放置物体等)的问题。)可以提取出来解决问题,但目前提取这些信息的难度很大,使电机控制变得困难。
长期任务中的理由
长线任务是非常困难的,比如在围棋中,当一个决策对未来的影响很大时,而当时采取的行动的正向回报来得很晚,这时就要推理出这个行动和它对未来的影响变得非常困难。因此,学习高水平的推理,并根据推理来控制机器人是一个非常困难的问题。强化学习中另一个常见的问题是硬探索,这在长视野任务中尤为明显。这意味着,当你必须找到一种罕见的策略,以各种策略来奖励你时,你很难找到这种策略。解决这种艰难探索的方法之一是更详细地定义奖励,并向代理提供信息。我们还可以考虑一些方法,比如课程学习,逐渐增加问题的解决难度,再比如通过专家代理的示范学习,以及内在奖励,代理获得一个未知的奖励有一些方法可以鼓励人们去探索较新的州,例如当他们访问一个州时,给予他们奖励。
环境
DeepMind准备的环境实例如上图所示,其中包括一个围棋问题等。在本章中,我们将对这些游戏逐一进行详细介绍。
慕乔班
MuJoBan是基于MuJoCo模拟的环境,它是基于Sokoban的单人解谜游戏。这两个环境的左边是顶视图,右边是玩家的视图。在这个谜题中,代理人可以推黄色物体,但不能拉它。因此,如果不打算推物,推物后就无法拉动物体,也就无法解题。因此,规划是非常重要的。在这个提供的环境中,环境的样子、迷宫的难度、迷宫的大小都不一样。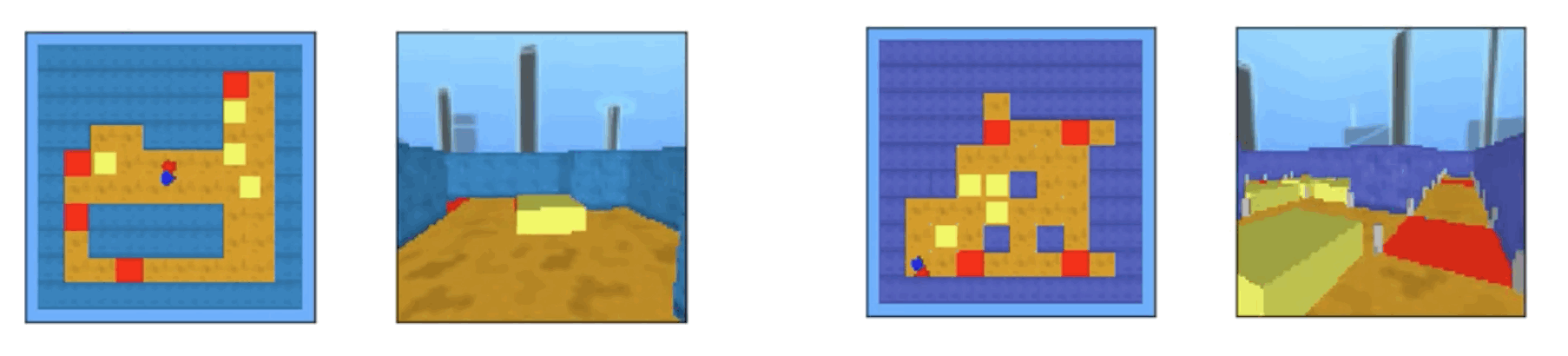 ,这个环境中的代理是一个2DoF,你可以通过身体相对于物体的旋转来移动物体。有三种类型的观察:关节扭矩、速度和物体的位置,从上面看到的环境,以及代理人的视角。代理人有耳朵,左边是蓝色的,右边是红色的,以显示代理人从上面看时的状态。如果代理们能够将每个物体移到红色垫子上解决问题,则在剧情结束时,他们将获得10美元的奖励,每将一个物体放在红色垫子上,将获得1美元的奖励,并且如果您未能解开谜题,您将获得1-1美元的奖励。基本上,一些简单的问题,只要移动代理200次左右就可以解决,而另一些比较困难的问题,则需要移动900次左右才能解决。
,这个环境中的代理是一个2DoF,你可以通过身体相对于物体的旋转来移动物体。有三种类型的观察:关节扭矩、速度和物体的位置,从上面看到的环境,以及代理人的视角。代理人有耳朵,左边是蓝色的,右边是红色的,以显示代理人从上面看时的状态。如果代理们能够将每个物体移到红色垫子上解决问题,则在剧情结束时,他们将获得10美元的奖励,每将一个物体放在红色垫子上,将获得1美元的奖励,并且如果您未能解开谜题,您将获得1-1美元的奖励。基本上,一些简单的问题,只要移动代理200次左右就可以解决,而另一些比较困难的问题,则需要移动900次左右才能解决。
另外,当Sokoban是一个需要代理推送物体来解决的游戏时,游戏可能无法正确反映所有规则。例如,代理人不能在迷宫的角落里推一个物体,因为他不能拉动它。因此,在这种环境下,规则就有点不一样了,如果代理人的动作像摩擦物体一样,物体被摩擦力隔开了角,可以移动。还有其他的限制条件,比如不能以一定角度移动物体。
MuJoXO
MujoXO是物理引擎中井字游戏的实现,机器人手臂触碰棋盘上的正确垫子,代理的彩色棋子就会出现在垫子上。然后,在棋子下完后,用抽象的计划器将对方的棋子下完。根据实际情况,垫子的位置已经没有了。然后,在剧情的开始和每次移动之后,机器人在棋盘上的位置会随机变化。为了表示各种问题的难易程度,对手的下棋方式采用了$\epsilon$-greedy的方式,在$\epsilon$中随机下棋的概率和剩余概率中的最优下棋。
奖励在游戏期间为0元,如果你赢了游戏,奖励为1元,平局奖励为0.5元;观察到的是关节角、速度、扭矩、末端执行器坐标和棋盘坐标。还可以使用其他图像输入,如下图所示。使用训练有素的代理,可以在100步左右完成游戏。

MuJoGo
最后,我想介绍一下MuJoGo,它是围棋在MuJoCo中的实现。在这种环境下,有一个7x7的格子,每个格子的交叉点上都有垫子,机器人的末端执行器碰到交叉点就可以放置走。另外,你还可以通过触摸下图所示的格子左右两边的空格来通关。给你一个时间限制来解决这个问题,如果超过时间限制你就输了。有了高效的代理,大约需要50招才能完成游戏。你的对手的棋步是由GNU程序(一个围棋程序)决定的。用$0.25$-greedy以及MuJoXO来决定对手的实力。
实验
在本文中,他们正在实验这个环境,作为未来研究的基线;虽然他们使用Ststate-of-the-art RL方法学习基本没有成功,但他们已经能够给行动者批判性地提供专家规划者的信息了。我们发现,在所有的任务中,效果都要好一些。这表明,通过更精细地定义奖励函数,高层策略的信息会传递给RL代理学习计划。现在,我们研究了必须给出多少关于任务的抽象信息,例如,状态、动态或解决方案,以了解通常的RL方法在这种环境下有什么不足之处。具体来说,实验是在以下三个条件下进行的
1.提供有关状态、动态和解决方案的信息(专家规划师条件)。
2.提供状态和动态的信息,但不提供解决方案的信息(随机规划器条件)。
提供最少或不提供抽象信息(香草剂条件)
代理商结构
代理人的结构如下,并采用演员-批评家网络。训练采用分布式IMPALA演员批判算法进行训练。下面的结构与连续控制中使用的其他方法的结构有两方面的不同。一是它包含了一个专家计划器,它将地面真理的抽象状态映射到目标的抽象状态和游戏的行动中去。由于这些状态很难从图像等信息中推断出来,而这些抽象的信息足以解决这个问题,所以我们考虑结合这些信息来研究这些状态在问题中具体起到什么作用。
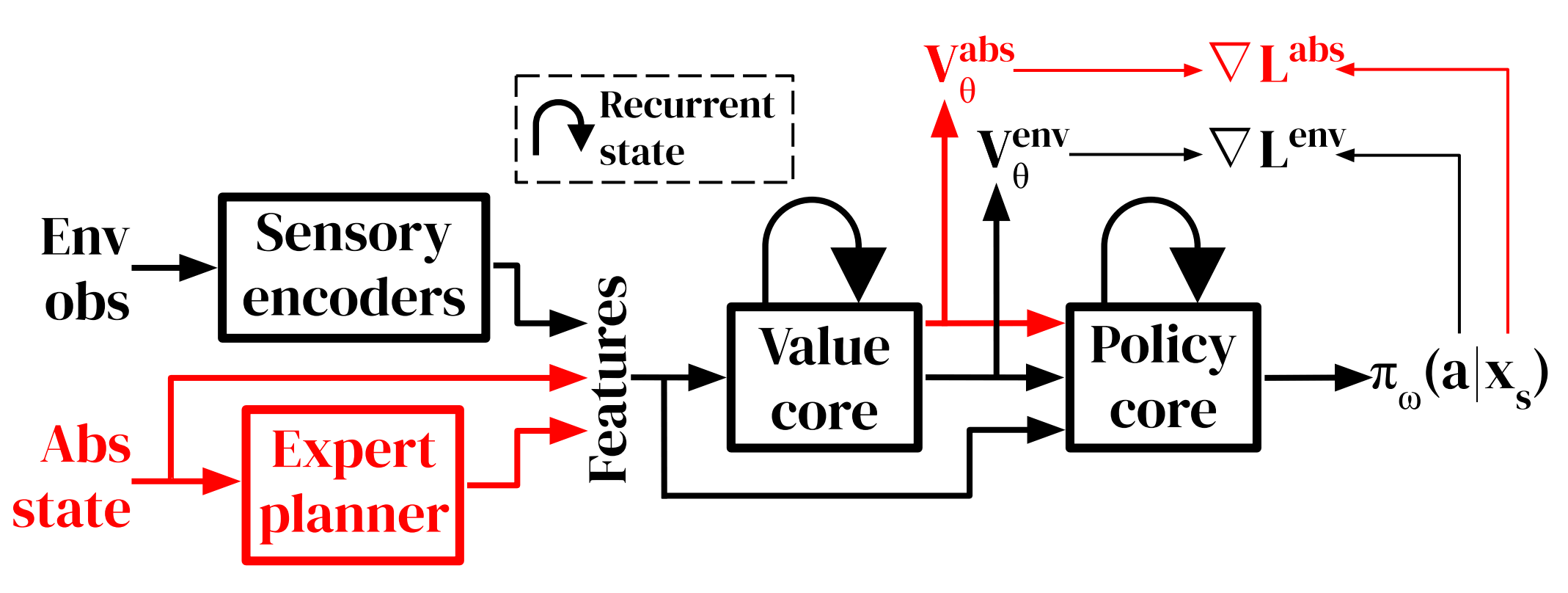
另一个不同的部分是增加了一个辅助任务,在抽象状态下听从专家的指示。这意味着,当代理人能够访问专家给出的状态空间转换时,将获得奖励。这个辅助任务比原来的任务长度短,有固定的时间限制。当代理解决辅助任务时,或超过时间限制时,辅助任务被重置。通过把这个任务交给代理,我们可以向代理提供抽象状态空间的信息,然后我们可以告诉代理低级机器人的运动对状态空间的影响。
在这种使用行为者批评的方法中,我们必须预测价值。在我们的方法中,我们使用两种不同的神经网络分别训练主任务的值和辅助任务的值。最后代理更新所需的政策梯度方程由以下公式给出
$$\nabla \mathcal{L}^{e n v}=\mathbb{E}_{x_{s}, a_{s}}\left[\rho_{s} \nabla_{\omega} \log \pi_{\omega}\left(a_{s} \mid x_{s}\right)\left(r_{t}^{e n v}+\gamma^{e n v} v_{s+1}^{e n v}-V_{\theta}^{e n v}\left(x_{s}\right)\right)\right]$$
$$\nabla \mathcal{L}^{a b s}=\mathbb{E}_{x_{s}, a_{s}}\left[\rho_{s} \nabla_{\omega} \log \pi_{\omega}\left(a_{s} \mid x_{s}\right)\left(r_{t}^{a b s}+\gamma^{a b s} v_{s+1}^{a b s}-V_{\theta}^{a b s}\left(x_{s}\right)\right)\right]$$
第一种表达方式与主任务有关,第二种表达方式与辅助任务有关。$\gamma$为贴现系数,$x_{t}$为状态,而$v_{s+1}$是一个价值目标。的...$r_{t}$代表补偿,$a_{s}$代表机动行动,$\pi_{\omega}$代表政策,$\rho_{s}$代表重要性抽样权重。
在专家规划师方法中,将当前抽象状态和专家规划师预测的目标抽象状态作为价值和政策输入。其他输入由代理给出,如图像信息,以及速度、触摸、位置和加速度,这取决于任务。
结果
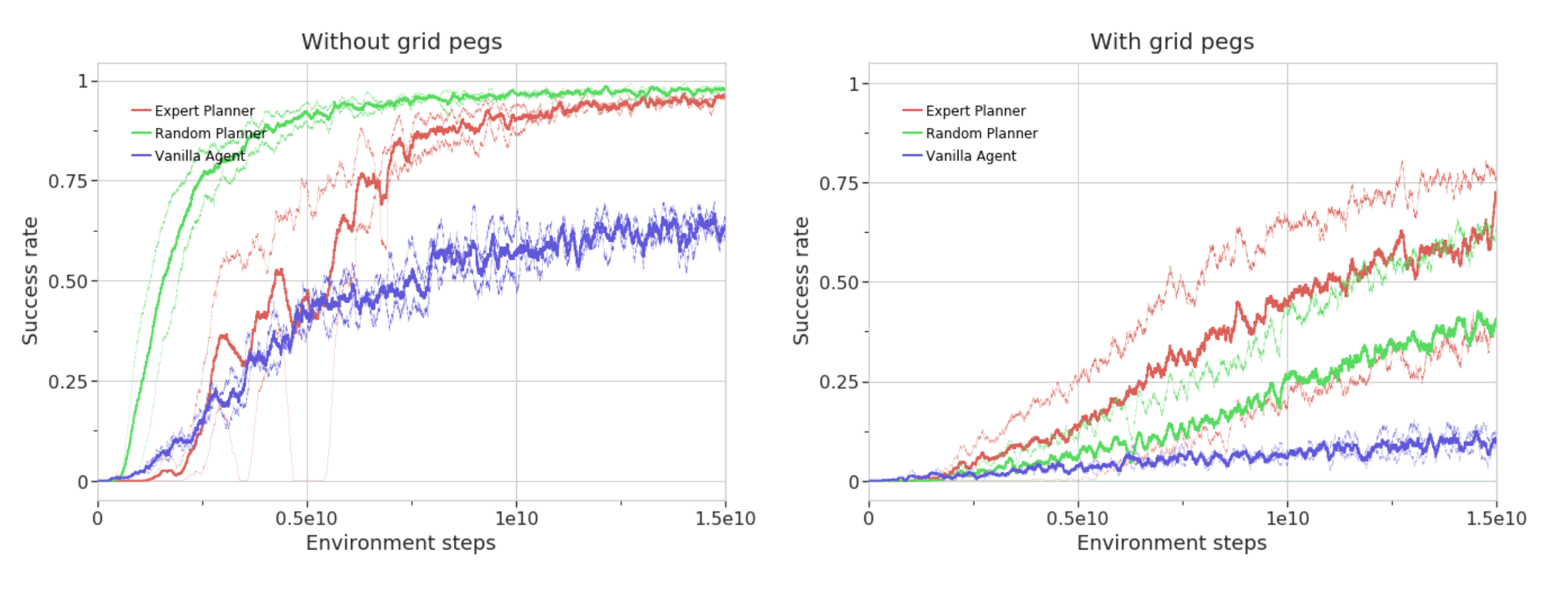
下图是在MuJoBan上的实验结果,可以看出用一般的RL方法训练的难度很大,反而用planner的时候更准确。"而"带格子钉"则更像原版的Sokoban,因为不能以一定角度推送物体,所以作为任务难度较大。从下图可以看出,"有网格钉"的成功率,专家规划师比随机规划师高,而"无网格钉"的成功率,随机规划师更高。这是有道理的。这可能是由于在"无网格钉"的情况下,由于"无网格钉"的灵活性,规划师和实际问题的匹配度不高,这可能会使专家规划师的信息作用降低"带网格钉"的方法更接近要解决的问题。另一方面,"带网格钉"更接近要解决的问题,专家规划师的信息更有用,因为它假设预测的子目标基本上是在最佳路径上,因此成功率比随机规划师的结果更高相信是这样的。
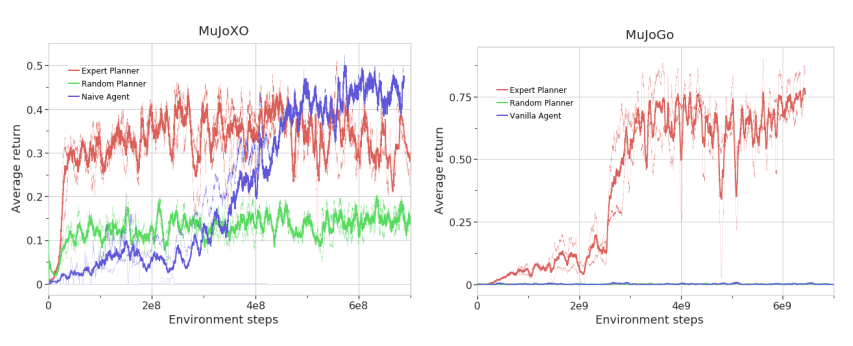
最后,对于MuJoXO和MuJoGo的结果,虽然MuJoXO比其他任务的分支少,规划相对容易,但它还是需要更多的数据来训练,即使是专家planenr。规划师的规划相对简单,但即使是专家规划师,也需要大量的数据来学习。另一方面,专家规划师在原始游戏和物理模拟之间没有不匹配的情况,可以让专家规划师选择最佳策略,但还是为代理人提供了一个可靠的赢得游戏的方法。亩收益值相对较低,说明这还不足以找到。
至于MuJoGo,由于棋局本身的长度和复杂度较大,学习起来比较困难。常规的RL根本没有学习,因为它太难探索了;使用专家计划器的代理最终能够击败对手,但学习的效率非常低。在他们的实验中,要玩4M左右的游戏才能达到60%的胜率。因此,在普通的RL中基本上很难解决这个问题,但是通过使用专家规划师,发现学习效率不高,但是他们还是可以解决这个问题。
摘要
在本文中,我们介绍了强化学习的一个新挑战。本文所介绍的游戏对于抽象推理和相关的运动控制是很重要的,我们认为这些游戏为使用强化学习进行这个方向的研究提供了非常有用的环境。人类从专家示范和其他游戏中得到的提示是多种多样的,例如。有鉴于此,我们很期待看到未来在这种新环境下,有什么新的RL算法可以更高效地解决。



与本文相关的类别





