强化学习能解决真实机器人上的复杂任务吗?
三个要点
✔️ 提出一种方法,通过结合反馈控制器和RL来解决实际机器上的复杂操纵任务。
✔️ 我们表明该方法对噪声和其他不确定因素具有鲁棒性
✔️ 与单独的RL相比,实现了高的采样效率和性能
Residual Reinforcement Learning for Robot Control
written by Tobias Johannink, Shikhar Bahl, Ashvin Nair, Jianlan Luo, Avinash Kumar, Matthias Loskyll, Juan Aparicio Ojea, Eugen Solowjow, Sergey Levine
(Submitted on 7 Dec 2018 (v1), last revised 18 Dec 2018 (this version, v2))
Comments: Accepted at ICRA 2019.
Subjects: Robotics (cs.RO); Machine Learning (cs.LG)
code:
本文所使用的图片要么来自论文、介绍性幻灯片,要么是参考这些图片制作的 。
简介
机器人在制造业中被用来执行重复性任务,但它们容易受到各种任务和不确定因素的影响。最常用的控制机器人的方法之一是PID控制,它允许机器人遵循预定的轨迹。许多制造任务需要适应不确定性和对环境的反馈,而设计一个反馈控制器来应对这种情况可能非常昂贵。这是因为反馈控制器不仅要遵循轨迹,还要考虑到与物体的接触以及接触引起的摩擦,即使给出了合适的物理模型,要确定接触的物理参数也是非常困难的。另一个缺点是,这种控制器的用途不是很广,因为它在预先设计的范围内工作。
另一方面,强化学习(RL)通过与环境的互动来学习,这意味着它可以解决涉及接触的任务,并有一定的通用性。然而,RL有一个问题,即它需要大量的样本来训练机器人,这非常困难,特别是在使用实际机器的时候。此外,RL需要大量的探索以进行学习,但在用真实的机器人进行实验时,会涉及到安全问题。因此在本文中,我们处理了传统反馈控制器难以解决的控制问题,但我们并不是只用RL来解决这些问题。本文的主要贡献是表明RL不是解决问题的唯一方法。本文的主要贡献是提出了一种结合传统反馈控制器和RL的方法。 本文将介绍这种方法,并展示它在实际机器上的实验表现。
方法
那么,你如何将传统的反馈控制器与RL结合起来?下图说明了一般的方法。正如你在下图中所看到的,机器人通过将RL学到的策略的行动和控制器的预定义行动相加,并将结果作为机器人的行动,来学习最大化其奖励。右图是用这种方法解决的一个装配任务。这是方法的基础,我们将在本章中更详细地解释。

剩余强化学习
对于大多数基于机器人的任务来说,奖励函数可以被认为是如下的
$$r_{t} = f(s_{m}) + g(s_{o})$$。
这里,$s_{m}$代表机器人状态,$s_{o}$代表物体状态。$f(s_{m})$表示机器人状态之间的几何关系,例如,将机器人的抓手移近要操纵的物体所获得的奖励。而$g_{s_{o}}$是对物体状态的奖励,例如,保持物体垂直的奖励。
当我们这样划分时,传统的反馈控制器适用于优化$f_{m}$,而RL适用于优化涉及与物体接触的$g(s_{o})$。为了利用这两个优势,AGENT的行动应该是这样的。
$$u=pi_{H}(s_{m})+ pi_{theta}(s_{m}, s_{o})$。
其中$pi_{H}(s_{m})$代表人类设计的控制器,$pi_{theta}(s_{m}, s_{o})$是通过RL学习的策略,$theta$代表参数。设计的反馈控制器$pi_{H}$能够快速优化$f(s_{m})$,从而达到更高的采样效率。此外,反馈控制器产生的误差可以由剩余RL补偿,使任务最终得到解决。
下面显示了该方法的算法,该方法使用双延迟深度确定性策略梯度(TD3)作为RL方法进行训练。

实验
在这个实验中,我们将尝试找出以下几点
- 使用手工设计的控制器是否能提高RL的采样效率和性能? 另外,对于不完整的手工设计的控制器,是否可以恢复?
- 提出的方法是否可以解决各种环境的问题?(通用性)
- 所提出的方法是否能解决噪声系统上的任务?
为了验证这一点,我们在模拟环境和真实环境中对装配任务进行了实验。两者的目标是解决相同的任务,即在两个积木之间插入一个积木,该积木由机器人的抓手抓着。下面的章节描述了模拟和真实环境的不同设置。
仿真环境: 在仿真环境中,使用笛卡尔空间位置控制器来控制机器人。为了允许插入区块,两个区块之间有足够的间隙。奖励函数表示如下
$$r_{t} = -||x_{g} - x_{t}||_{2} - \lambda (||theta_{l}||_{1} +||theta_{r}||_{1})$$
其中$x_{t}$为当前区块位置,$x_{g}$为目标位置,$theta_{l}$和$theta_{r}$为左、右区块角度(y轴),$lambda$为超参数。

真实环境:在真实的实验中,我们使用了一个符合要求的联合空间阻抗控制器作为机器人控制器。该任务与模拟环境中的任务相同,但代理不是接收物体等的地面真实位置坐标,而是接收使用摄像机跟踪系统获得的估计坐标。我们使用了以下奖励函数
$$r_{t}=-\|x_{g}-x_{t}|_{2}-\lambda(\|\theta_{l}|_{1}+\|\theta_{r}|_{1})$$
$$-\mu\|X_{g}-X_{t}\|_{2}-\beta(\|\phi_{l}\|_{1}+\|\phi_{r}\|_{1})$$
其中,$x_{t}$是末端效应器的坐标,$x_{g}$是目标的坐标,$X_{t}$是两个站立块的当前坐标,$X_{g}$是物体的期望位置,$theta_{l}$和$theta_{r}$是左右物体在Y轴方向上的角度,$?phi_{l}$和$phi_{r}$是左右两个物体相对于Z轴方向的角度。$lambda$、$mu$和$beta$分别代表超参数。

在这个实验中,我们将提出的方法--剩余RL与只用RL(Only RL)解决任务的情况进行了比较。
剩余的RL样本效率
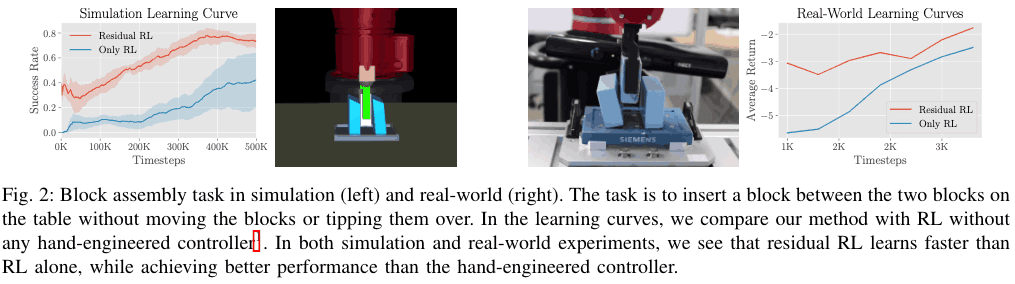
下图显示了在模拟和真实世界环境中的Only RL和Residual RL的实验结果。从下图可以看出,Residual RL在这两种情况下的表现都比较好,在样本较少的情况下成功率较高,这说明它的样本效率更高。这是因为,与Residual RL相比,Only RL必须通过与环境的互动从头学习位置控制问题,这就降低了采样效率。特别是,样本效率问题对于真实机器上的实验非常重要,因此Residual RL特别适用于解决真实机器上的问题。
在不同环境中的影响
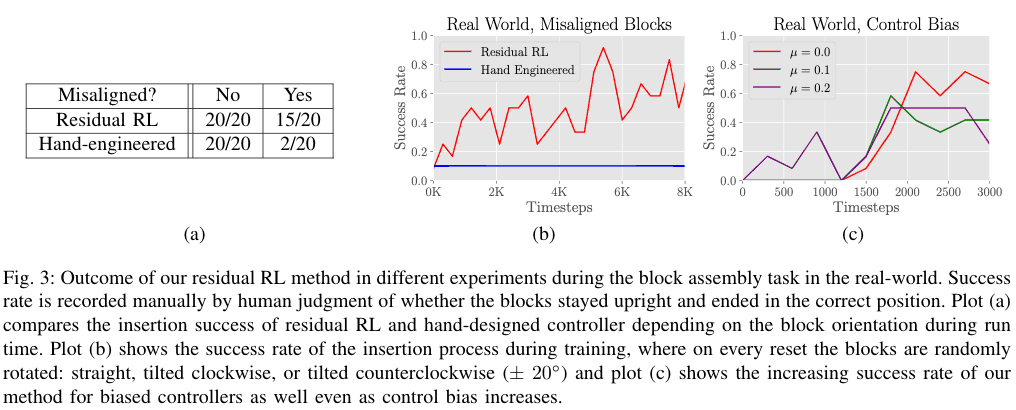
如果两个区块之间有足够的空间,并且两个区块的初始位置没有误差,手工设计的控制器可以以很高的成功率解决问题。另一方面,当有误差时,用手工设计的控制器很难解决,成功率为2/20,如下表(a)所示,而用残差RL的成功率为15/20。这是由于为了在求解时将木块插入抓手的手中正在被放置的块如果用手工设计的控制器,这是很难做到的,但Residual RL能够处理这种情况。结果如下图(b)所示,8000个样本在短短3小时内就在实际机器上进行了训练,显示了很高的样本效率。
从控制噪音中恢复
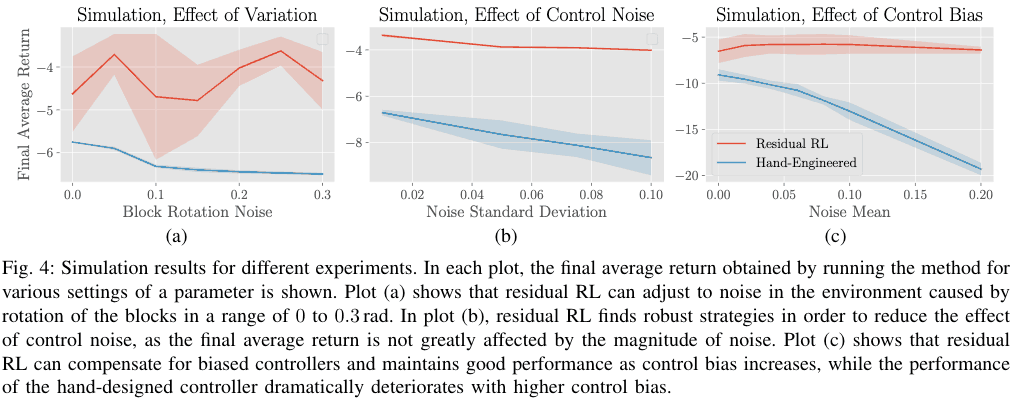
在这里,我们将残差RL与单独的手工设计的控制器的结果进行了比较,当使用有偏差的控制器和存在控制噪声时。在下面的(b)中,当包括控制噪声时,手工设计的控制器显示出奖励的大幅下降,而残余RL显示出较小的下降,表明它对噪声更稳健。同样,当使用有偏差的控制器时,手工设计的控制器的性能随着噪声的增加而急剧下降,而残余RL的性能却没有下降。相比之下,剩余RL的性能并没有随着噪声的增加而降低,这表明有可能解决现实世界应用中可能出现的问题,如传感器漂移。
残留RL中的模拟到现实
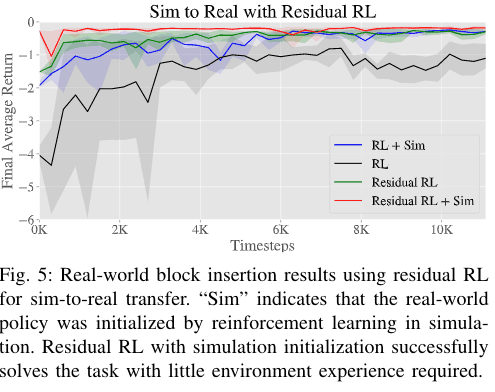
在我们的模拟到现实的实验中,我们发现,当残差法策略在模拟中被初始化,然后转移到现实世界的环境中时,它能够比残差法只在真实机器上或只在RL上训练时更快地解决任务。因此,有可能解决有困难接触的任务。因此,我们认为这是一个非常有效的方法来解决有困难的联系人的任务。
摘要
许多旨在利用强化学习解决机器人任务的论文许多旨在利用强化学习解决机器人任务的论文在本文中,我们提出了一种新的方法来提高采样效率。在本文中,我们将传统的反馈控制器与强化学习相结合,以提高采样效率,并使其在真实的机器上学习成为可能。最近,我们看到越来越多的论文旨在通过将传统方法与RL相结合来提高采样效率,如用RL进行运动规划。在未来,我认为更重要的是找出如何最有效地使用RL,而不是在模拟中,而是在实际机器中。



与本文相关的类别





