
白日梦:梦想家终于是一个真正的机器人了!他的名字叫 "白日梦"
三个要点
✔️ 显示Dreamer可以在四个真实世界的机器人上学习。
✔️ 使一个四足机器人能够在大约一小时内从背部转向地面,站起来并向前移动。
✔️ 机器人可以学习使用图像作为输入抓取物体,然后使用稀疏的奖励将其放置在不同的位置。
DayDreamer: World Models for Physical Robot Learning
written by Philipp Wu, Alejandro Escontrela, Danijar Hafner, Ken Goldberg, Pieter Abbeel
(Submitted on 28 Jun 2022)
Comments: Published on arxiv.
Subjects: Robotics (cs.RO); Artificial Intelligence (cs.AI); Machine Learning (cs.LG)
code:
本文所使用的图片要么来自论文、介绍性幻灯片,要么是参考这些图片制作的。
介绍
近年来,学习机器人解决复杂的现实世界的任务已经引起了机器人研究的广泛关注。特别是,深度强化学习(RL)已成为改善机器人行为的可能,并最终通过反复试验和错误解决复杂的任务。然而,使用Deep RL学习机器人的缺点是必须与环境进行长时间的互动,并且需要收集大量的样本。
相比之下,近年来备受关注的一种名为世界模型的方法,从过去与环境的交互数据中学习环境本身,并能想象在特定情况下,如果在该环境中采取某种行动,会有什么结果。这使得它有可能,例如,通过使用少量的与环境的交互数据,来计划或学习机器人的行为,即它的政策。到目前为止,这种方法已经得到了验证,特别是在游戏中,但它在现实世界中的作用直到现在还没有得到证明。
为了证实这一点,本文将一种名为Dreamer的世界模型学习方法应用于以下四个机器人,表明它可以通过在线学习在现实世界中有效地学习。本文介绍了Dreamer方法和每个机器人实验的结果。

技术
在这篇论文中,一种名为Dreamer的方法被应用于现实世界的机器人,它使用在线学习来学习世界模型,同时学习行为。本章介绍了梦想家。下图显示了梦想家方法的总体情况。
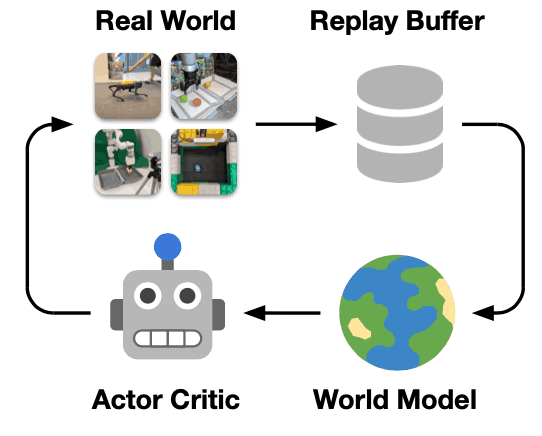
梦想家从过去与环境互动的经验数据中学习世界模型,然后使用演员批评算法,根据所学世界模型预测的轨迹来学习行为。因此,行为本身是利用所学世界模型想象出来的数据来学习的,而不是从与真实世界环境的互动中学习的。此外,在本研究中,数据收集和模型更新,即更新世界模型,行为者和批评者是分开的,这样行为者在一个线程中继续收集数据,同时在另一个线程中更新模型,以提高学习效率。该模型同时在一个单独的主题中被更新。
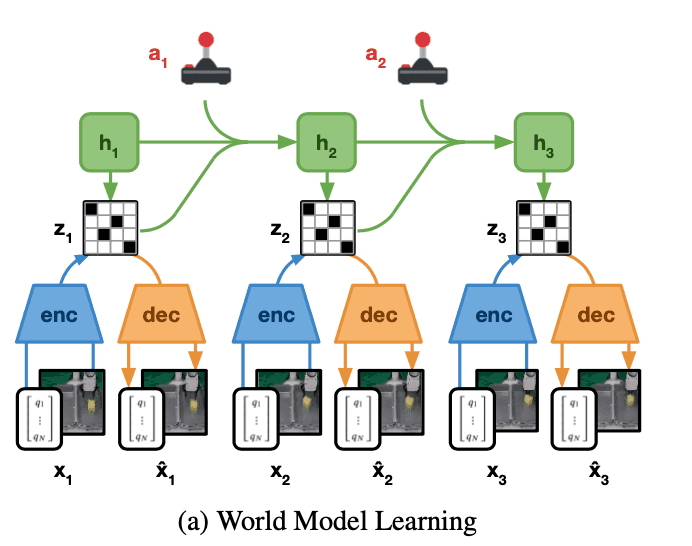
世界模型学习
首先,它解释了世界模型是如何训练的。下图给出了世界模型的概况,其目的是估计环境的动态变化,如下图所示。然而,如果直接使用图像等数据来估计未来图像,估计的未来图像和实际图像之间的误差很可能很大,这导致在估计长期未来动态时的误差积累。世界模型是基于递归状态空间模型,由以下四个网络组成
编码器网络:$enc_{theta} (s_{t} | s_{t-1}, a_{t-1}, x_{t})$
解码器网络:$dec_{theta} (s_{t}) \approx x_{t}$
动态网络:$dyn_{theta} (s_{t} | s_{t-1}, a_{t-1})$
奖励网络:$rew_{theta}(s_{t+1}) `approx r_{t}$
机器人基本上配备了多个传感器,例如,机器人关节的角度、力传感器、RGB和深度摄像机图像等,都可以作为信息获得。因此,"梦想家 "世界模型的编码器将这些传感器信息结合起来,并输出一个随机的表征$z_{t}$。然后,动力学模型利用当前状态$h_{t}$输出下一个随机表示$z_{t+1}$。输出结果不直接用于学习行为。在这项研究中,机器人通过在真实世界的环境中行动来获得奖励;奖励网络被训练来预测这些收集的奖励。
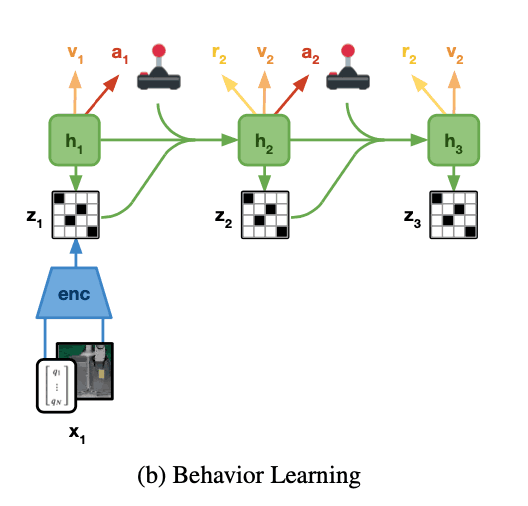
演员-批评家学习
在世界模型学习与任务无关的环境动态表征的同时,行为者批评算法被用来学习特定任务的行为。学习使用世界模型的潜在空间中估计的展开来学习行为,如下图所示。这个演员批评家算法由以下两个神经网络组成。
演员网络:$pi (a_{t}| s_{t})$
批评者网络:$v(s_{t})$
这里,行为者网络学习的是使每个潜在空间状态$s_{t}$的估计任务报酬最大化的行动$a_{t}$分布。另一方面,批评者网络使用时间差异学习进行训练,以估计任务的未来总奖励(价值)。批评网络对价值函数的这种学习是很重要的,因为它也考虑到了规划范围(H=16)以外的奖励。批评是根据估计的状态奖励学习的,学习的目标轨迹是返回如下($\lambda$-returns)。
$V_{t}^{lambda}\doteq r_{t} + \gamma((1-\lambda) v(s_{t+1}) + \lambda V_{t+1}^{lambda}, \quad V_{H}^{lambda} \doteq v(s_{H}) )$
训练演员的目的是使价值最大化,但也鼓励他们在学习时探索环境,从而鼓励他们保持高熵。考虑到这一点,使用下面的损失函数来训练演员。
$mathcal{L}(pi)\doteq-\mathrm{E}[sum_{t=1}^{H} \ln \pi(a_{t} | s_{t}) sg(V_{t}^{lambda}-v(s_{t})) + \eta \mathrm{H}[\pi(a_{t}| s_{t})s_{t})]]$
这里,$sg$表示梯度计算被停止。这意味着评论家本身没有被更新。
实验
在本文中,Dreamer在四个机器人上进行了训练和评估。除了运动、操纵和导航等重要任务外,这些机器人还被评估为各种模式,如连续或不连续的行动空间,奖励是密集的还是稀疏的,以及本体感觉信息(机器人自身的信息,如关节状态)、图像或其他传感器是否信息,如关节状态)或图像或其他传感器的综合输入。
本实验的目的是看世界模型的方法是否能更有效地获得机器人在现实世界中的行为。具体而言,正在对以下问题进行测试
- 梦想家》是否可以直接应用于现实中的机器人
- Dreamer是否能够在不同的机器人、传感器模式和行为空间类型中获取行为
- 与其他强化学习方法相比,基于Dreamer的方法的效率如何?
基线。
在A1型四足机器人的实验中,由于行动空间以连续值和低维信息作为输入,因此使用了软演员批评(SAC)作为基线并与Dreamer进行了比较;在XArm和UR5机器人的实验中,图像和在XArm和UR5机器人的实验中,DQN被训练成一个基线,因为它将图像和先验信息作为输入,并且动作空间采取离散值。特别是,在学习中使用了一种叫做彩虹的方法。对于UR5,我们还将其与PPO进行了比较。最后,在Sphero导航任务中,图像被作为输入,行动空间是连续的,DrQv2方法被作为基线进行比较。
A1四足行走
在这个实验中,我们使用了一个名为Unitree A1机器人的机器人,如下图所示,它可以完成从俯卧姿势旋转、站起来和以恒定速度向前移动等任务。在以前的论文中,主要使用了一些方法,如在模拟中使用领域随机化学习策略,然后将其转移到真实世界的机器人上,使用一种称为恢复控制器的机制来学习,以避免危险情况,以及学习行动轨迹发生器的参数。本研究中使用的学习方法没有使用这些方法中的任何一种。一个密集的奖励函数被用于学习。如果你对奖励函数是如何定义的感到好奇,请参考论文中的方程式(5)。
经过一个小时的学习,机器人能够使用Dreamer学习一系列动作,包括转身、站起来和从背对地面的位置向前走,如下图所示。在最初的5分钟里,机器人能够转身并把脚放在地上,20分钟后,它学会了站起来,最后学会了走路。再经过10分钟的学习,机器人已经能够承受从外面推过来的力量,并且能够在摔倒后迅速重新站起来。相比之下,SAC能够从后退的位置转身并将脚放在地上,但无法站起来行走。

UR5多对象视觉拾取和放置
如下图所示,抓起一个物体并将其放入另一个垃圾箱的任务是很重要的,因为这是仓库里的一项常见任务。这项任务非常具有挑战性,因为它的目的是使用稀疏的奖励函数进行学习,而且它必须能够从图像中估计物体的位置,以及几个移动物体的动态变化。来自传感器的信息将是机器人关节的角度、抓手的位置和末端执行器的直角坐标,以及RGB图像。作为奖励,当检测到抓手处于半闭合状态时,给予+1的奖励;如果物体被释放到同一仓内,给予-1的奖励;如果物体被放置在对面的仓内,给予+10的奖励。动作空间包括将末端执行器相对于X、Y和Z轴移动一定距离,以及关闭或打开抓手的动作,这些动作采取离散值。
梦想家需要8个小时的学习才能平均每分钟抓取2.5个物体。它学得不是很好,特别是在开始的时候,因为奖励很稀少,但两个小时后,它的表现开始改善。与此相反,基线PPO和Reinbow未能学习,虽然他们能够抓住物体,但他们的行为被认为是立即释放物体。这些方法被认为需要更多的经验,并被认为在现实世界条件下很难学习。

XArm视觉取放系统
UR5是一个工业机器人,而XArm是一个相对便宜的7DoF机器人,与UR5实验一样,它的训练任务是从图像中估计一个物体的位置,并将其移动到另一个仓。在这个实验中,使用了一个柔软的物体,抓手通过绳子与物体相连,这样即使物体在垃圾箱的边缘,它也能抓住物体,使物体得以移动。奖励功能的学习是使用与UR5实验中相同的稀疏奖励,行为线索也是类似的。除了UR5实验中使用的信息外,深度图像也被用作输入信息。
梦想家使政策局在10小时内平均每分钟抓取3.1个物体,并将它们移到另一个垃圾箱。此外,在使用Dreamer时,机器人最初在改变光线条件时未能解决任务,但经过几个小时的学习,能够迅速适应。相比之下,当使用Rainbow时,它没能学会,就像UR5实验中一样,因为它需要大量的经验。

Sphero导航
最后,对一项导航任务进行了实验,在这项任务中,一个有轮子的机器人,即Sphero Ollie机器人,被操纵到一个预先确定的目标。这是只用RGB图像作为输入进行的训练。行动空间是连续值的,车轮移动的方向被估计为行动。作为奖励,从当前位置到目标的L2距离是负数。
梦想家能够在两个小时内前往目标,并留在目标附近。基线DrQv2的表现与Dreamer相似。

摘要
在这项研究中,我们测试了Dreamer学习措施的效率,这在以前还没有用真实的机器人验证过,结果表明它可以比无模型RL基线更有效地学习。我们相信将来会在这一领域进行更多的研究,因为人们发现诸如学习世界模型的方法,如Dreamer,可以适应现实世界的机器人。例如,即使Dreamer可以高效地学习,但它仍然需要大约8-10个小时来学习,所以有各种方向可以选择,例如可以缩短这个时间的学习方法,特别是更有效地学习结构化的潜表征。以下是需要解决的一些最重要的问题。



与本文相关的类别





