
FiLM解决了时间序列预测模型中去除噪声和变异性检测之间的权衡问题。
三个要点
✔️ 这是一篇在NeurIPS 2022上被接受的论文。它有效地利用深度学习方法的特性来解决时间序列预测中的常见挑战,即噪声和信号的分离。
✔️ 具体来说,它提出了一个FiLM,该FiLM应用Legendre多项式投影来近似历史信息,使用Fourier投影来去除噪声,并添加低秩近似来加速计算。
✔️ 在多元和单元长期预测中,它分别将最新模型的准确性提高了20.3%和22.6%。值得一提的是,它也可以作为其他深度学习模块的插件使用。用
FiLM: Frequency improved Legendre Memory Model for Long-term Time Series Forecasting
written by Tian Zhou, Ziqing Ma, Xue wang, Qingsong Wen, Liang Sun, Tao Yao, Wotao Yin, Rong Jin
(Submitted on 18 May 2022 (v1), last revised 16 Sep 2022 (this version, v4))
Comments: Accepted by The Thirty-Sixth Annual Conference on Neural Information Processing Systems (NeurIPS 2022)
Subjects: Machine Learning (cs.LG); Machine Learning (stat.ML)
code:

本文所使用的图片要么来自论文、介绍性幻灯片,要么是参考这些图片制作的。
概述
最近的研究表明,RNN和变形金刚等深度学习模型通过有效利用历史信息,可以在时间序列的长期预测中提供显著的性能提升。然而,研究发现,在避免对历史上出现的噪声进行过度拟合的同时,历史信息在神经网络中的存储方式仍有很大的改进空间。解决这个问题将使深度学习模型的能力得到更有效的利用。
为此,本文设计了一个频率改进的Legendre记忆模型(FiLM:Frequency improved Legendre Memory)。它应用Legendre多项式投影来逼近历史信息,使用傅里叶投影来消除噪音,并增加了一个低等级近似来加快计算速度。
实证研究表明,所提出的FiLM在多变量和单变量长期预测中明显提高了最先进模型的准确性(分别为20.3%和22.6%)。这也证明了本研究中开发的表示模块可以作为一个通用插件来提高其他深度学习模块的长期预测性能。
介绍。
长期预测与短期预测的不同之处在于它是基于一个长范围的未来历史。长期时间序列预测有许多重要的应用,包括能源、天气、经济和运输。它比常规时间序列预测更具挑战性。挑战包括长期的时间依赖性,错误传播的便利性,复杂的模式和非线性的动态。这些挑战使得用传统的学习方法(如ARIMA)进行准确预测一般是不可能的。
深度学习方法如RNN在时间序列预测方面取得了突破性进展,但Rangapuram等人(2018);Salinas等人(2020),Pascanu等人(2013)经常受到梯度损失/爆炸等问题的困扰,实际性能有限 NLP和继Transformer Vaswani等人(2017)在CV社区取得成功后,Wen等人(2022b)、Zhou等人(2022)、Wu等人(2021)和Zhou等人(2021)在捕捉时间序列预测的长期依赖关系方面表现出良好的性能。
为了实现准确的预测,许多深度学习研究人员增加了模型的复杂性,希望能够捕捉到重要而复杂的历史信息。然而,这些方法都未能实现他们的目标。图1显示了真实世界ETTm1数据集的大实话时间序列和香草变压器模型Vaswani等人(2017)和LSTM模型Hochreiter &Schmidhuber(1997a)的预测进行了比较。可以看出,预测结果完全偏离了地面实况分布。我们认为,这些错误源于这些模型试图保留真实的信号,而错误地捕获了噪声。
作者的结论是,准确预测有两个关键:
1)如何尽可能全面地捕捉重要的历史信息。
2)如何有效地消除噪音。
因此,为了避免预测出轨,我们不能简单地通过提高模型的复杂性来改善它,而是决定考虑一种稳健的表示方法,可以在没有噪音的情况下捕捉Wen等人(2022a)的时间序列中的重要模式。
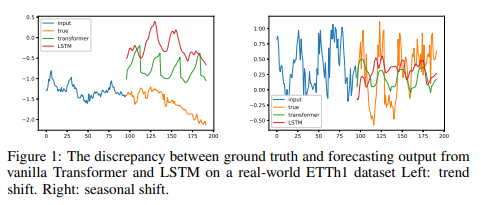
这一观察促使人们转换视角,从长期时间序列预测转向长期序列压缩。递归存储模型在函数逼近任务中取得了令人印象深刻的结果:具有Legendre投影的递归存储单元(LMU)为长期时间序列提供了良好的表示;S4模型为数据表示提出了另一种递归存储设计,这导致了长程预测基准(LRA),大大改善了最先进的结果。然而,当涉及到长期时间序列预测时,这些方法还不能与基于Transformer的方法的最先进性能相媲美。
仔细检查发现,与LSTM/Transformer模型相比,这些数据压缩方法在恢复历史数据的细节方面很强大,如图2所显示。然而,它们倾向于过度拟合所有过去的尖峰,这意味着它们对嘈杂的信号很弱,限制了它们的长期预测性能。LMP中采用的Legendre多项式只是正交多项式(OPs)家族中的一个特例。值得注意的是,OPs(包括Legendre、Laguerre、Chebyshev等)和其他正交基数(Fourier和Multiwavelets)已经在许多领域得到了广泛的研究,最近还应用于深度学习。
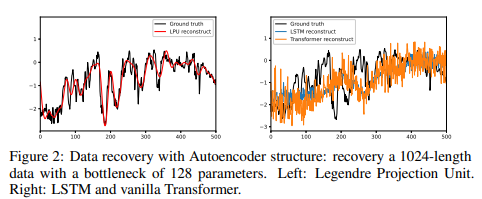
上述观察结果表明,需要开发准确和稳健的方法来代表时间序列数据,以便进行未来预测,特别是长期预测。所提出的方法将这些表示方法与一个强大的预测模型结合起来,并在几个基准数据集上明显优于现有的长期预测方法。
作为实现这一目标的第一步,我们直接利用LMU Voelker等人(2019)使用的Legendre投影来动态更新具有固定大小向量的时间序列的表示。然后将这个投影层与各种深度学习模块相结合,以提高预测性能。直接利用这种表示法的主要挑战是信息保存和数据过拟合之间的两难问题,即Legendre投影的数量越大,历史数据被保存的越多,但噪声数据更有可能被过拟合。
因此,作为第二步,引入了一层降维,结合傅里叶分析和低秩矩阵近似,以减少噪声信号对Legendre投影的影响。具体来说,Legendre投影中没有大维度的表示,因此历史数据的所有重要细节都被保留了下来。接下来,结合应用傅里叶分析和低秩近似,以保留与低频傅里叶分量相关的部分表示和上层特征空间,以消除噪声的影响。
因此,它不仅能捕捉到长期的时间依赖性,还能有效地减少长期预测中的噪音。作者将提出的方法命名为用于长期时间序列预测的频率改进型Legendre记忆模型,简称FiLM。
该研究的主要贡献可归纳为以下几点
1. 用于稳健的多尺度时间序列特征提取的混合专家频率改进的勒格朗德记忆模型(FiLM)架构
2.重新设计Legend Projection Unit(LPU),使其成为一个通用的数据表示工具,时间序列预测模型可以用它来解决历史信息存储问题
3.频率扩展层(FEL),它结合了傅里叶分析和低秩矩阵近似,以降低维度,最大限度地减少时间序列的噪声信号的影响,并缓解过拟合问题。
4. 在多个领域(能源、交通、经济、天气和疾病)的六个基准数据集上进行大规模实验。
实证研究表明,所提出的模型在多变量和单变量预测中分别将最先进方法的性能提高了19.2%和26.1%。此外,实证研究还显示,由于降维,计算效率有了极大的提高。
Legendre-Fourier域中的时间序列表示。
Legendre投影。
传奇多项式投影允许将长时间的数据序列投影到一个有界维度的子空间上,从而导致对不断发展的历史数据进行压缩或特征表示。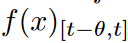 形式上,给定一个在线观察的平滑函数f,目的是保持一个固定大小的历史压缩表示,其中θ指定窗口大小。
形式上,给定一个在线观察的平滑函数f,目的是保持一个固定大小的历史压缩表示,其中θ指定窗口大小。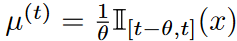 在每个时间点t,一个近似的函数g(t)(x)被定义为与度量有关的。在本文中,最多使用N 1阶的Legend多项式来构造函数g(t)(x)。
在每个时间点t,一个近似的函数g(t)(x)被定义为与度量有关的。在本文中,最多使用N 1阶的Legend多项式来构造函数g(t)(x)。
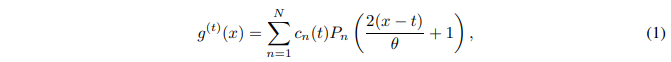
其中Pn(⋅)是n阶Legendre多项式。系数cn(t)由以下动态方程捕获
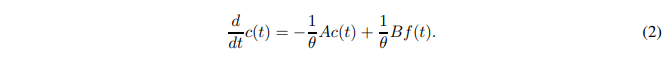
其中A和B的定义在Voelker等人(2019)中给出。使用Legendre多项式作为基础,平滑函数可以被准确地逼近,如以下定理所示。
定理1。
如果f(x)是L-Lipschitz、
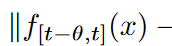
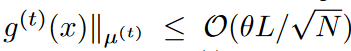
由此可见,f(x)是一个k阶的有界导数。此外,如果f(x)有k阶的有界导数、
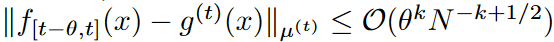
这将是一种情况。
根据定理1,自然地,Legendre多项式的基数越多,近似精度越高,不幸的是,这可能导致历史中的噪声信号过拟合。如上所述,将上述特征原封不动地反馈给MLP、RNN和vanilla attention等深度学习模块并不能提供最先进的性能,主要是由于历史中的噪声信号。因此,我们接下来引入一个带有傅里叶变换的频率增强层来进行特征选择。
定理2。
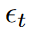 让A为单元矩阵和双次高斯随机噪声。
让A为单元矩阵和双次高斯随机噪声。
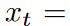
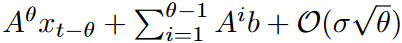
以下是一个例子。
傅里叶变换
由于白噪声具有完全平坦的功率谱,时间序列数据一般被认为享有特定的频谱偏向,一般不会在频谱上随机分布。由于随机的过渡环境,预测任务的实际输出轨迹含有很大的波动性,人们通常只预测其平均路径。因此,相对平滑的解决方案是首选。
根据方程(1),近似函数g(t)(x)可以通过对系数cn(t)进行t和n的平滑而得到稳定。这一观察有助于设计有效的数据驱动方法来调整系数cn(t),因为对n的平滑可以很容易地通过每个通道乘以一个可学习的标量来实现,我们将主要讨论通过傅里叶变换对t平滑cn(t)。
频谱偏差意味着cn(t)的频谱主要位于低频区,而高频区的信号强度很弱。为了简化分析,我们将假设cn(t)的傅里叶系数为an(t)。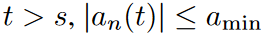 对于频谱偏差,我们假设存在s,amin >0,这样对所有n都满足。对系数进行抽样的一个想法是保留前k个维度,对其余维度进行随机抽样,而不是采用完全随机的抽样策略。作者通过以下定理描述了近似质量的特点:
对于频谱偏差,我们假设存在s,amin >0,这样对所有n都满足。对系数进行抽样的一个想法是保留前k个维度,对其余维度进行随机抽样,而不是采用完全随机的抽样策略。作者通过以下定理描述了近似质量的特点:
定理3。
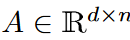
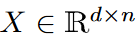 让Ω(k/n)为输入矩阵的傅里叶系数矩阵,μ(A)为矩阵A的一致性度量。假设存在s和正amin,使得A的最后d-s列的元素小于amin。如果我们保留第一个s列,并从其余的列中随机选择一个O(k2/ε2 -s)列,那么高概率地
让Ω(k/n)为输入矩阵的傅里叶系数矩阵,μ(A)为矩阵A的一致性度量。假设存在s和正amin,使得A的最后d-s列的元素小于amin。如果我们保留第一个s列,并从其余的列中随机选择一个O(k2/ε2 -s)列,那么高概率地
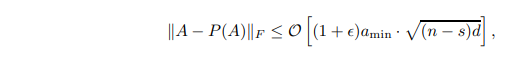
其中P(A)表示将A投射到列选择的列空间的矩阵。
定理3意味着,当阿明足够小时,所选择的空间可以被视为与原始空间几乎相同。
模型结构
FiLM:频率改进的Legendre记忆模型。
FiLM的整体结构如图3所示。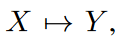 FiLM通过利用两个主要的子层来映射序列。
FiLM通过利用两个主要的子层来映射序列。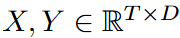 这里 .换句话说,它主要利用两个子层:LPU(Legendre投影单元)层和FEL(Fourier增强层)层。为了捕捉不同尺度的历史信息,LPU层是由不同尺度的专家混合实现的。为了进一步提高模型的稳健性,引入了可选的附加数据规范化层,RevIN Kim等人(2021);FiLM是一个简单的模型,只有一个LPU和一个FEL层。
这里 .换句话说,它主要利用两个子层:LPU(Legendre投影单元)层和FEL(Fourier增强层)层。为了捕捉不同尺度的历史信息,LPU层是由不同尺度的专家混合实现的。为了进一步提高模型的稳健性,引入了可选的附加数据规范化层,RevIN Kim等人(2021);FiLM是一个简单的模型,只有一个LPU和一个FEL层。
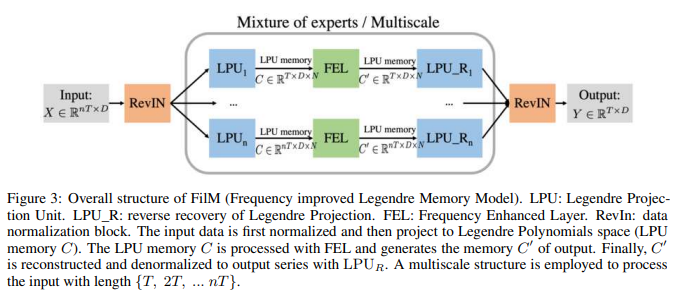
LPU: Legendre投影单元
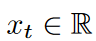
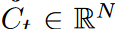 LPU是一个状态空间模型:Ct = ACt-1 + Bxt,其中是输入信号,是存储单元,N是Legend多项式的数量。 LPU包含两个不可训练的预矩阵A和B,定义如下:
LPU是一个状态空间模型:Ct = ACt-1 + Bxt,其中是输入信号,是存储单元,N是Legend多项式的数量。 LPU包含两个不可训练的预矩阵A和B,定义如下:
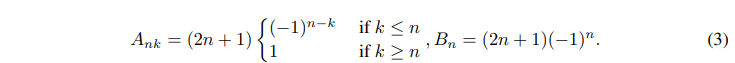
LPU有两个阶段:投射和重建。前一阶段将原始信号投影到存储单元:C = LPU(X)。后一阶段从存储单元重构信号:Xre = LPU_R(C)。图4显示了输入信号被投射/重构到存储器C的整个过程。
FEL: 频率增强层
最低的近似值
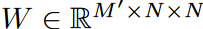 FEL有一个单一的可训练权重矩阵(),需要从数据中学习。
FEL有一个单一的可训练权重矩阵(),需要从数据中学习。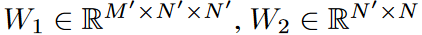
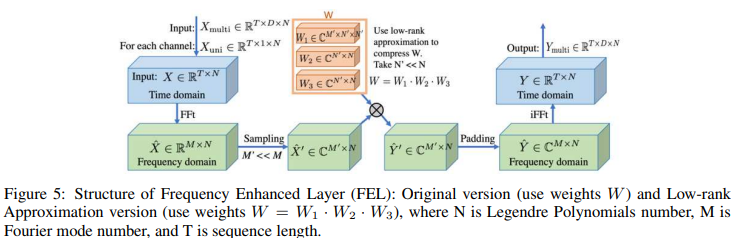
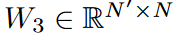 然而,这个权重可能很大;W可以被分解成三个矩阵 ,进行低秩近似(N'<N)。使用Legend多项式数N=256作为默认值,该模型的可训练权重在N'=4时明显减少到0.4%,而准确性几乎没有下降。计算方案如图5所示。
然而,这个权重可能很大;W可以被分解成三个矩阵 ,进行低秩近似(N'<N)。使用Legend多项式数N=256作为默认值,该模型的可训练权重在N'=4时明显减少到0.4%,而准确性几乎没有下降。计算方案如图5所示。
模式选择
为了减少噪音和提高训练速度,在傅里叶变换后选择一个频率模式的子集。默认的选择策略是选择最低的M模式。实验中考虑了各种选择策略。结果表明,对于某些数据集,通过增加随机的高频模式可以实现进一步的改进(由定理3的理论研究支持)。
多尺度专家的混合机制。
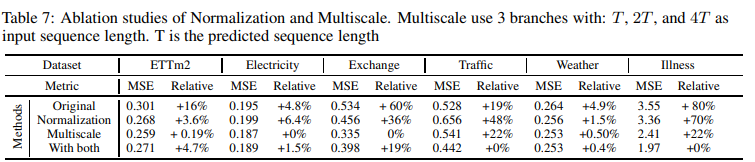
多尺度现象是时间序列预测所固有的一个重要数据偏差。由于作者统一强调了历史序列点的重要性,本文的模型可能缺乏这样的先验分布。该模型如图3所示,其中各种时间跨度{T, 2T, ... nT},并实现了一个简单的混合专家策略,使用时间跨度为T的输入序列来预测跨度为T的预测,并在一个线性层中合并每个专家预测。如表7所示,这种机制在所有数据集上都持续改善了模型的性能。
数据规范化
正如Wu等人(2021);Zhou等人(2022)所指出的,时间序列的季节性趋势分解是长期时间序列预测中重要的数据归一化设计。作者发现,这种LMU投影基本上可以在大多数数据集中起到归一化的作用,但由于缺乏明确的归一化设计,在某些情况下可能会影响到性能的稳健性。简单的可逆实例归一化(RevIN)Kim等人(2021)被改编为作为一个附加的解释性数据归一化块。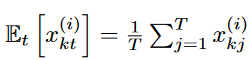
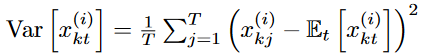
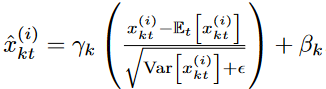
 所有实例的均值和标准差被计算出来,.x(i)与输入数据的所有实例一样。
所有实例的均值和标准差被计算出来,.x(i)与输入数据的所有实例一样。
然后,规范化的输入数据被发送到模型进行预测。最后,通过应用初始归一化的倒数对模型输出进行归一化。
RevIN将学习过程放慢了2-5倍,但应用RevIn也没有在所有数据集上观察到一致的改进。因此,RevIn可以被看作是模型学习中的一个可选的稳定器。表7中的截断研究显示了它的详细性能。
实验
为了评估FiLM,在六个现实世界中流行的长期预测基准数据集上进行了大规模实验,包括交通、能源、经济、天气和疾病。作者主要使用了五个最先进的(SOTA)基于变换器的模型,即FEDformer、Autoformer Wu等人(2021)、Informer Zhou等人(2021)、LogTrans Li等人(2019)、Reformer Kitaev等人(2020),以及最近的状态空间模型S4 Gu等人(2020)。2020),以及最近带有递归记忆的状态空间模型S4 Gu等人(2021a)进行比较;FEDformer被选为主要基线,因为它在大多数情况下取得了SOTA的结果。
主要结果
为了更好地进行比较,按照Informer Zhou等人(2021)的实验设置,将训练和评估的预测长度分别固定为96、192、336和720,调整输入长度以获得最佳预测性能。
多变量。
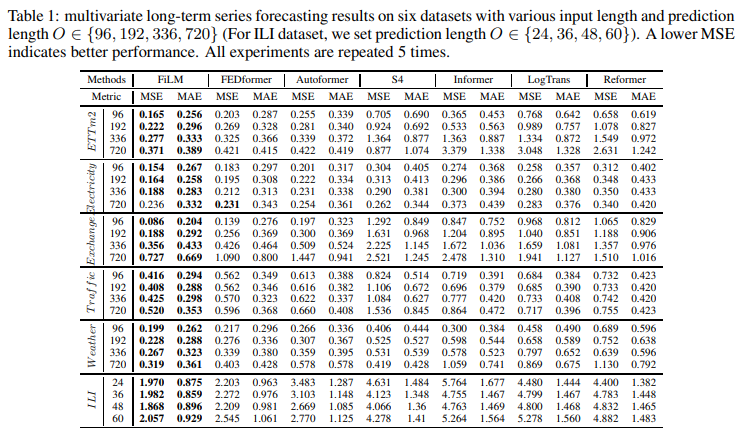
在多变量预测任务中,FiLM在所有六个基准数据集的所有范围内都取得了最好的性能,如表1所示 与SOTA工作(FEDformer)相比,拟议的FiLM能够将总体相对MSE降低20.3%。结果是总体上相对MSE降低了20.3%。值得注意的是,对于一些数据集,如Exchange,观察到更大的改进(>30%)。在Exchange数据集上,FiLM仍然取得了卓越的性能,尽管没有明显的周期性。轴一致,显示了FiLM在长期预测中的优势。
单变量。
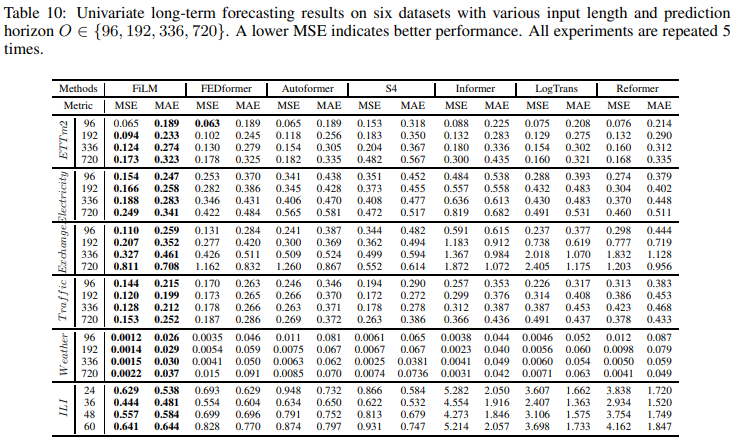
表10总结了单变量时间序列预测的基准结果:与SOTA工作(FEDformer)相比,FiLM实现了22.6%的总体相对MSE降低。在一些数据集上,如天气和电力需求,它也能够达到40%以上的改进。这再一次证明了FiLM在长期预测中的有效性。
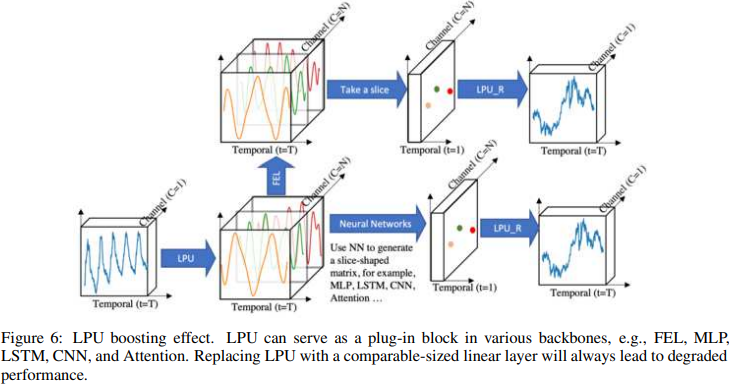
LPU提升的结果。
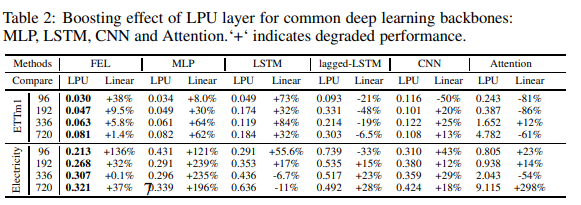
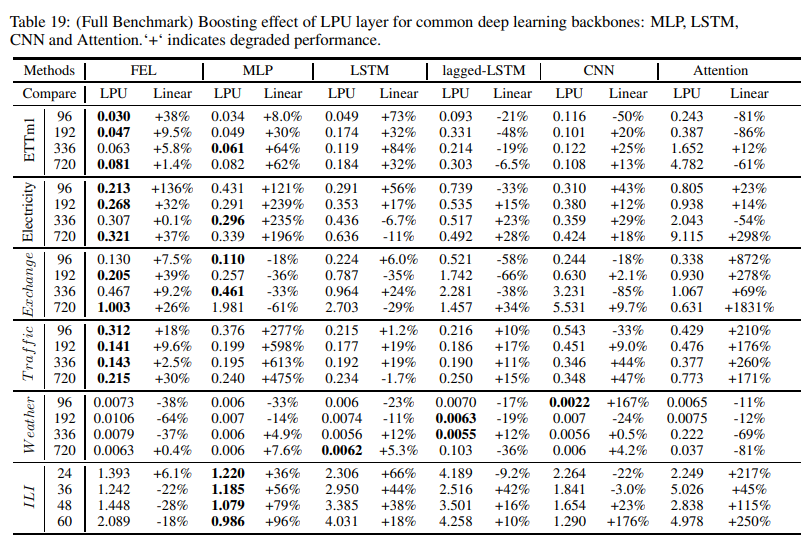
如图6所示,我们进行了一系列的实验来衡量LPU与各种流行的深度学习模块(MLP、LSTM、CNN和Attention)相结合的提升效果。实验将LPU与相同规模的线性层进行了比较;值得注意的是,LPU不包含任何可训练参数。结果见表19。对于所有的模块,LPU显著提高了长期预测的平均性能:MLP:119.4%,LSTM:97.0%,Cnn:13.8%,Attention:8.2%。的性能,值得进一步探讨。
FEL的最低近似值
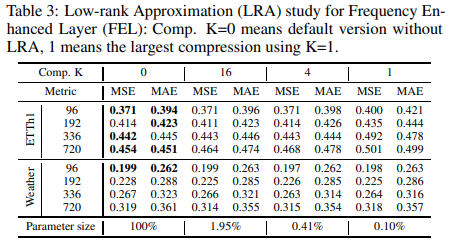
在频率扩展层中,对可训练矩阵的低秩近似可以将参数大小大大减少到0.1%⇠0.4%,但准确度略有下降。实验详情见表3:与基于Transformer的基线相比,FiLM可以将可学习参数减少80%,内存用量减少50%。
FEL模式选择政策
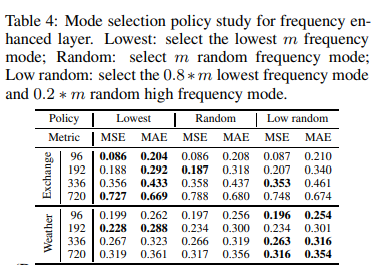
表4中考虑了频率模式选择策略:最低模式选择方法显示了最稳健的性能;低随机列的结果显示,正如定理3中的理论工作所支持的那样,随机添加一些高频信号在一些数据集上产生了特殊改进低随机列显示,低随机列是最稳健的。
分步分析
本节介绍了所采用的两个主要模块(FEL和LPU)、隔离研究、多尺度机制和数据规范化(RevIN)。
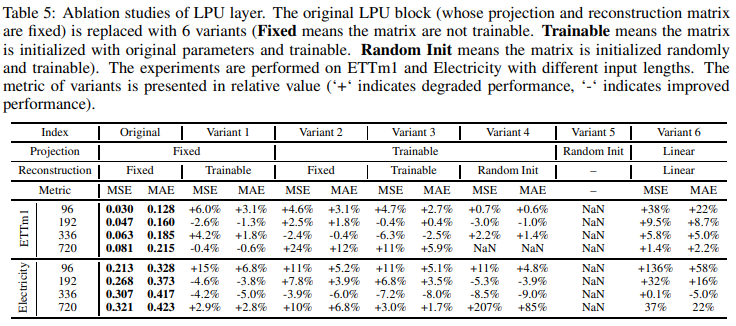
隔离LPU
为了证明LPU层的有效性,表5比较了原始LPU层和六个变体:LPU层由两组矩阵(投影矩阵和重建矩阵)组成。每个都有三个变体:固定的、可训练的和随机初始的。
变体6使用一个同等大小的线性层来代替LPU层。变体6导致了32.5%的平均退化,证实了Legendre投影的有效性:LPU投影矩阵被递归调用N次(其中N是输入的长度)。因此,如果投影矩阵是随机初始化的(变体5),输出就会面临指数爆炸的问题。如果投影矩阵是可学习的(变体2、3和4),该模型也会受到指数爆炸的影响,需要一个小的学习率、缓慢的学习速度和许多次的收敛过程。因此,考虑到速度和性能之间的权衡,不推荐使用可学习投影版本。带有可学习重建矩阵的变体(变体1)具有可比的性能,而且收敛难度较小。
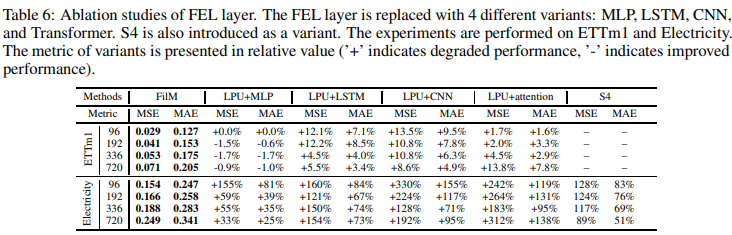
隔离FELs
为了证明FEL的有效性,它已经被几个变种(MLP、LSTM、CNN和Transformer)所取代。S4也作为一个变体被引入,因为有一个带有Legendre投影存储器的S4版本。实验结果总结在表6中:与LSTN、CNN和Attention相比,FEL取得了最好的性能;MLP在输入长度为192、336和720时取得了相当的性能。然而,MLP的内存使用量为N 2L(FEL为N 2),这是不能容忍的;S4取得了与LPU+MLP类似的结果。LPU+CNN也产生了最差的结果。
将多尺度与数据规范化分开 (RevIN)。
多尺度模块在所有数据集上都有明显的改进。然而,在数据归一化方面观察到了混合性能,"交通 "和 "疾病 "的性能得到了改善,但对其余的数据只有微小的改善。 表7显示了一项采用RevIN数据归一化和多尺度专家混合方法的消融研究。表7.
摘要
在长期预测中,保留历史信息和去除噪声之间的权衡是准确和稳健预测的一个关键挑战。为了应对这一挑战,作者提出了频率改进的Legendre记忆模型(FiLM),该模型准确地保留了历史信息并消除了噪音信号。此外,该模型中采用的Legendre和Fourier投影的有效性得到了理论和经验上的证明。
广泛的实验表明,所提出的模型在六个基准数据集上显著提高了SOTA的准确性。特别重要的是,所提出的框架是相当通用的,可以作为未来研究中长期预测的构建模块。它也可以针对不同的情况进行修改。例如,Legendre投影单元可以被其他正交函数取代,如傅里叶、小波、拉格尔多项式和切比雪夫多项式。
基于噪声特性,傅里叶增强层被证明是这个框架的最佳候选者之一。作者计划在未来考虑这个框架的进一步变体。



与本文相关的类别






