还有更多!另一个(M)DETR!一个多模态推理模型的创新范式
三个要点
✔️ 提出一个端到端文本控制的对象检测模型
✔️ 在多模态任务中实现端到端检测
✔️ 实现下游任务的绩效
MDETR -- Modulated Detection for End-to-End Multi-Modal Understanding
written by Aishwarya Kamath, Mannat Singh, Yann LeCun, Ishan Misra, Gabriel Synnaeve, Nicolas Carion
(Submitted on 26 Apr 2021)
Comments: Accepted by ICCV2021 oral
Subjects: Computer Vision and Pattern Recognition (cs.CV); Computation and Language (cs.CL); Machine Learning (cs.LG)
code:
本文所使用的图片要么来自论文件,要么是参照论文件制作的。
简介
目前许多图像和文本融合的多模态推理模型涉及使用预先训练的物体检测器从图像中提取感兴趣的区域。这听起来很明显,但仔细想想,这意味着模型的模态推理依赖于预先训练好的物体检测器。例如,如果你输入查询 "狗",而你只想在图像中检测到狗,但你的预训练物体检测器是为汽车预训练的,无论你在文本查询中输入多少信息,它都无法检测到狗这就是我们现在使用多模态推理的原因。这是目前阻碍多模态推理模型性能的一个主要因素。
因此,我们在这里提出的论文是一个端到端的调制检测器MDETR,它以文字查询(如标题或问题)为条件检测图像中的物体。(这篇论文也是由Jan Lucan教授共同撰写的)。)
基于转化器结构,它通过在模型的早期阶段融合两种模式的信息并进行联合文本和图像推理来检测图像中的物体。 从这里开始,它变得更加厉害,最终在检测任务和多个下游任务上都达到了SOTA性能。在我们继续之前,让我们看看MDETR的惊人表现!MDETR能够检测自由格式文本中的对象,并将其归纳为未知的类别和属性组合。因此,在 "一只粉红色的大象 "的案例中,MDETR正确地检测到了一只粉红色的大象,尽管我们在训练期间没有看到粉红色或蓝色的大象!在这种情况下,MDETR就能正确地检测到粉红色的大象。

DETR
MDETR基于DETR模型,它是一个端到端的物体检测模型,由骨干网和变换器编码器-解码器组成(DETR的结构如下图所示)。在AI-SCHOLAR中,有一篇关于DETR的非常详细的文章,如果你对它感兴趣的话! "对象检测的创新模式"。
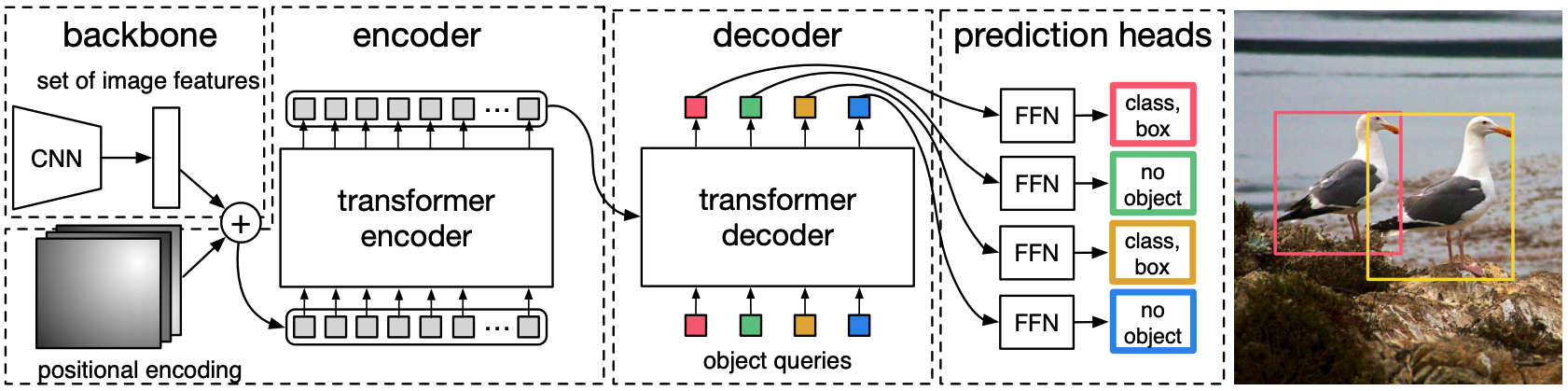
DETR首先通过CNN骨干网运行图像以提取视觉特征。 然后对视觉特征进行扁平化和位置编码,并送入变形器编码器。对象查询可以被认为是模型检测对象所需的槽。
在这些对象查询被送入解码器后,交叉注意层被用来与编码的图像特征进行非正式的互动,并预测每个查询的输出嵌入。最后,每个查询的输出嵌入被用来通过共享参数的FFN来预测盒子坐标和类别标签。
然而,由于每个查询都使用了一个盒子的预测,因此预先确定的查询数量是图像中物体数量的上限。 由于图像中物体的数量可能小于查询的数量,作者使用了一个额外的类标签,对应于 "无物体"。
医学博士
MDETR的结构如下图所示。
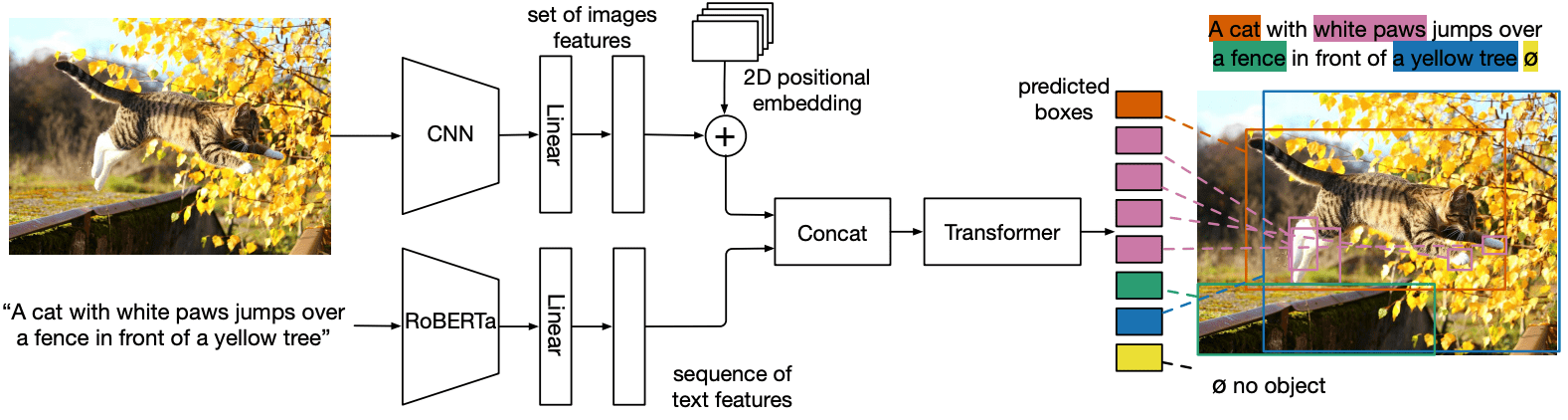
MDETR通过CNN骨干网提取视觉特征,然后将特征扁平化。 然后,它通过添加二维位置嵌入将空间信息添加到扁平化的向量中。 到此为止,它几乎与DETR相同,但这是差异的开始。 接下来,对于语言模态,我们使用预先训练好的转换语言模型(RoBERTa)来生成一串与输入相同大小的隐藏向量。 然后,通过应用与模式有关的线性投影,将图像和文本特征都投射到一个共同的嵌入空间。 然后,这些特征向量在序列维度上被串联起来,产生一个单一的图像和文本特征序列。
这组特征首先被输入到交叉编码器进行处理。然后,与DETR一样,设置一个对象查询来预测目标帧。
所以我们把上图中的文本模式部分合并到DETR中。
学习
在学习方面,除了DETR损失函数外,作者还提出了两个额外的损失,用于图像和文本对齐。
- 软令牌预测损失,一个无参数的对齐损失
- 文本-查询对比排列损失,这是一个参数化的损失函数,用于近似排列的查询和标记之间的相似度
软令牌预测
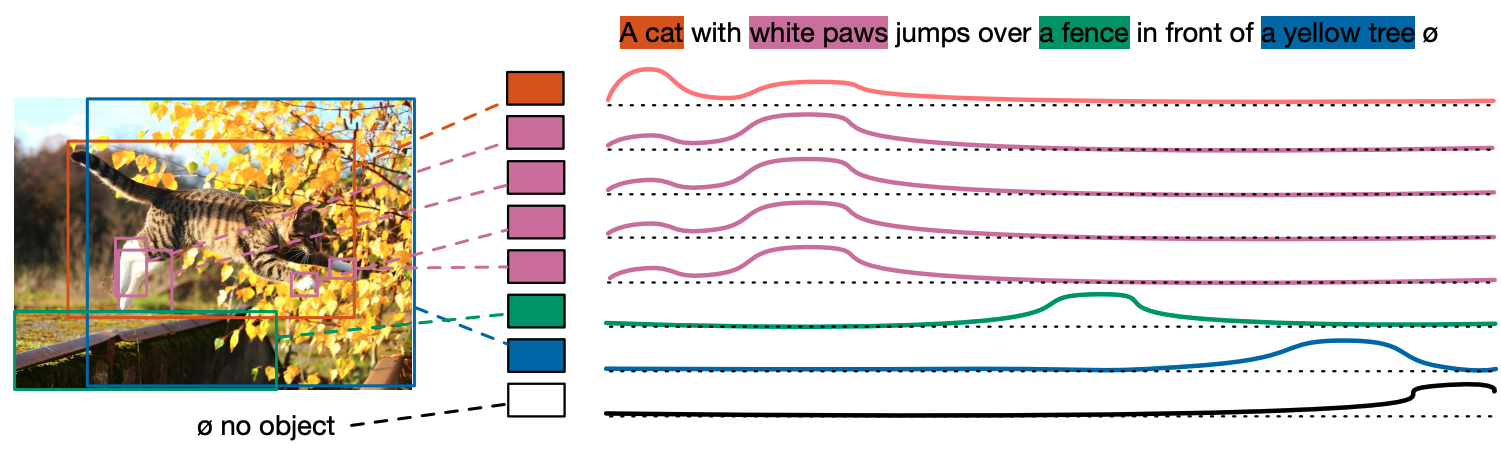
与传统的物体检测不同,它只需要响应出现在输入句子中的物体,我们首先将标记的最大数量设置为256,并训练模型预测每个预测框中每个匹配的GT的所有标记位置的分布。 下图显示了一个例子,猫咪预测框已经被训练成预测前两个词的分布。从 "软标记 "这个名字可以看出,标记之间的关系是这样的:硬标记预测不适合,因为文本和图像是多对一的,文本中的多个词可能对应于图像中的同一个物体,反之亦然。我认为它的设计理念是,硬性规定的预测不适合。
对比性对齐
软令牌预测损失用于对齐物体和文本,对比对齐损失用于加强视觉和文本嵌入特征表示的对齐,使对齐的视觉和语言特征表示在特征空间中相对接近。损失函数不作用于位置,而是直接作用于特征层面,提高相应样本之间的相似度。这个损失函数是基于InfoNCE的,用以下公式表示
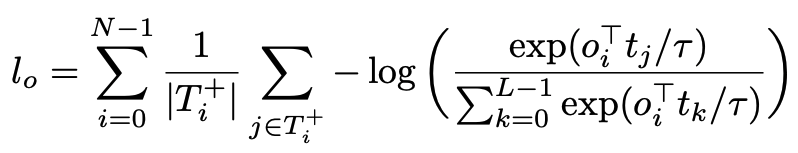
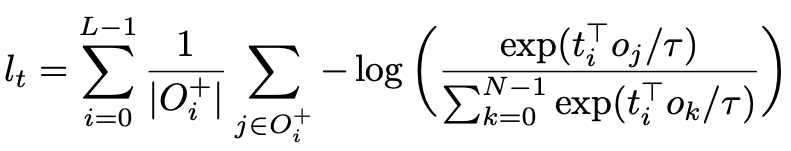
从目前的描述中可以看出,基本思路是如何将DETR扩展到多模态,因为其端到端的物体检测能力可以克服多模态的限制。架构和多模态特定关系的附加损失函数是相当简单和直观的。所以一定要记住DETR("对象检测的创新模式")即使是原来的论文,也是相当简单明了的,直到实验为止。而且有相当多的实验,这也解释了为什么它被ICCV2021口头接受。
实验
目前正在使用CLEVR数据集的合成数据和真实世界的图像进行实验。
CLEVR
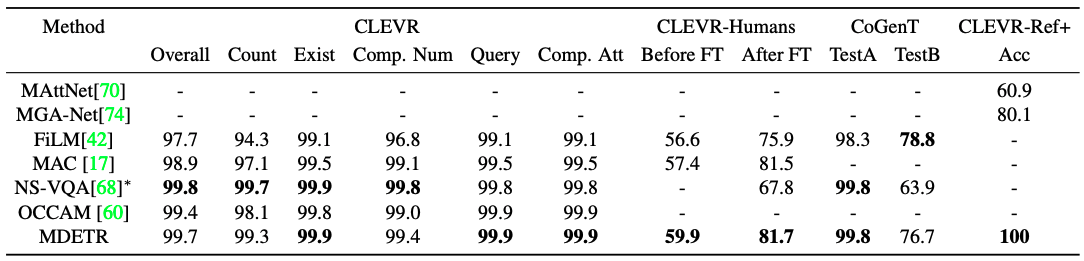
CLEVR将是一个合成数据集,旨在评估受控环境中的多模态模型。主要挑战是理解涉及多达20个推理层次的问题,并将其中的关键短语与图像中的正确对象相匹配。与一些成功的CLEVR方法不同,MDETR没有纳入任何特殊的归纳偏见来应对如此复杂的推理任务。这是该系统的一个显著特点。尽管它的表述相对简单,但我们表明,MDETR在回答问题的任务中与最先进的模型相比具有竞争力。结果显示在表中。
它显示出与NS-VQA接近的性能。它的性能明显优于不使用外部信号的方法。此外,CLEVR-Humans是一个由人类产生的关于CLEVR图像的问题数据集。CoGenT是对建设性概括的测试。评估方案包括对A组的训练,其中球体可以是任何颜色,但立方体可以是灰色、蓝色、棕色或黄色,圆柱体可以是红色、绿色、紫色或青色。接下来,对分区B进行零次评估,其中立方体和圆柱体的颜色和形状的组合是相反的。与其他模型一样,我们看到了一个巨大的概括性差距。这表明,该模型在形状和颜色之间学到了强烈的虚假偏差。
最后,我们在CLEVR-REF+上评估了我们的模型,这是一个基于CLEVR图像的参考表示理解数据集。对于每个对象查询,我们学习一个额外的二进制头来预测查询是否对应于被引用的对象。我们对独特的物体表征子集的准确性进行评估,以排名第一的盒子是否有至少0.5的IU来衡量。MDETR在验证集的每个例子中都将有效的盒子排在第一位,准确率为100%,大大超过了以前的研究。与以前的研究相比,这是一个重大的改进。
真实世界的图像

句子 "穿着灰色衬衫的人,手腕上戴着手表。另一个人穿着蓝色毛衣。第三个人穿着灰色大衣和围巾 "是一个有三个不同属性的句子的例子。第三个人穿着灰色大衣,戴着围巾。那是相当惊人的准确性。
下游任务
我们还在四个下游任务(短语接地、理解参考表达式、分割和视觉问题回答)上评估了MDETR。由于我们进行了相当多的实验,我们只列出结果,如果你有兴趣,请务必查看原始出版物。
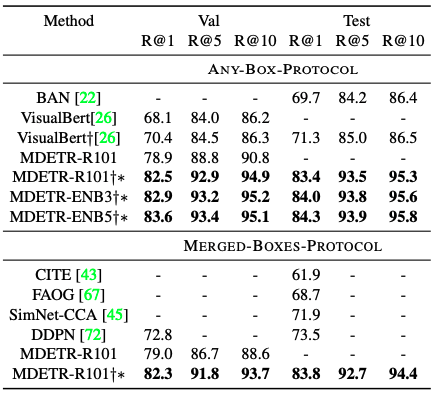
短语 接地
给定一个或多个可能相互关联的短语,任务是为每个短语提供一组边界框。对于这项任务,我们使用了Flickr30k实体数据集,并对其进行了训练/评估/测试,并以Recall@k来评估性能。对于测试集中的每个句子,预测100个边界框,并根据对短语所对应的标记位置的评分对这些框进行排序,使用软标记对齐预测。结果与现有的方法进行了比较,使用了两种不同的方法:一个以文本为条件的检测模型和一个使用传感器的视觉语言预学习模型。可以看出,准确率绝大部分都比其他方法好。
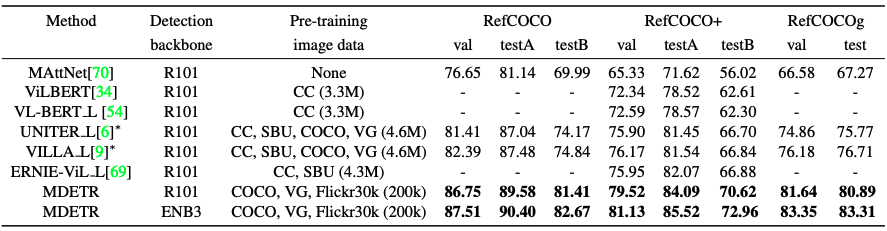
理解指代表达
任务是通过返回给定的图像和文字表述的物体周围的边界框来定位一个物体。基本上,该方法是对一组预先提取的、与使用传统预训练的物体检测器获得的图像相关的边界盒进行排序。
然而,在本文中,我们解决了一个更困难的问题。我们的意思是,给定一个参考表征和相关图像,我们训练模型来直接预测边界盒。对于这项任务,我们使用了三个成熟的数据集,称为RefCOCO、RefCOCO+和RefCOCOg。
MDETR有一个小的变化。例如,给定标题 "穿着蓝色裙子的女人站在玫瑰花丛旁边......",MDETR被训练为预测所有被引用的方框。然而,在引用表达的情况下,MDETR被训练为预测所有被引用对象的盒子。然而,在引用表达式的情况下,MDETR需要被训练成只返回一个指代整个表达式中所指的女人的边界盒,因此返回的边界盒数量过多。因此,我们通过在特定任务的数据集上训练五次来微调该模型。这也导致了准确性的压倒性提高。
分割
与DETR一样,我们表明它可以通过在PhraseCut数据集的分割任务上进行训练来扩展执行分割。同样,在准确性方面也取得了相当大的改善。
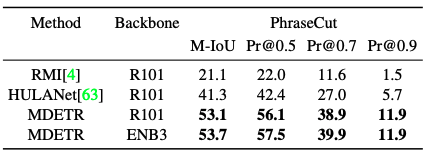
视觉问题和回答
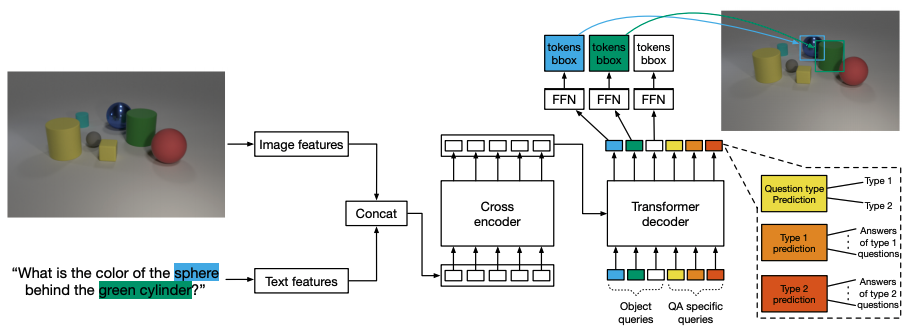
通过在GQA数据集上对预训练的模型进行微调,我们评估了调制检测是多模态推理的有用组成部分这一假设。该模型的架构如下图所示。除了用于检测的100个查询外,我们还使用了一个专门针对问题类型的额外对象查询和一个用于预测问题类型的查询。
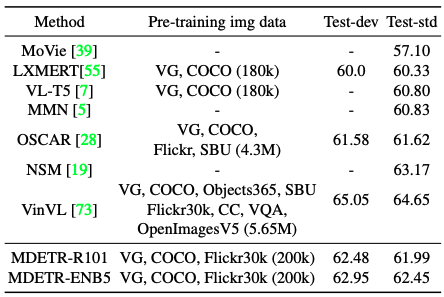
当MDETR与Resnet-101骨干网一起使用时,它不仅超过了使用类似数据量的LXMERT和VL-T5,而且还超过了在预训练中使用更多数据的OSCAR。
用于长尾检测的几张照片转移
受关于图像分类的零点转移的CLIP的启发,我们正在进行实验,目的是在预先训练好的MDETR模型的给定标签集上构建有用的检测器。与CLIP不同,我们不保证预先训练好的数据集包含所有目标类别的表示。与CLIP不同,我们不保证预训练数据集包含所有目标类别的表征。这导致该模型总是预测一个给定文本的方框。因此,我们不能在真正的零次转移设置中评估模型,而是在少数次设置中,我们在一部分可用的标记数据上训练模型。我们用LVIS数据集进行实验,这是一个具有1.2k类别的大词汇量的检测数据集。并且由于其长尾巴和非常小的训练样本,是一项具有挑战性的任务。
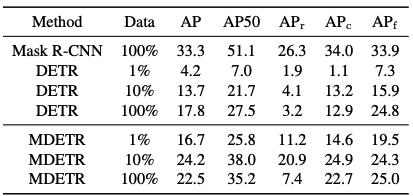
我们比较了两个基线:第一个是只在完整的LVIS训练集上训练的Mask-RCN。第二种是在MSCO上预训练的DETR模型,并在LVIS训练集的不同子集上进行微调。
结果如表所示:即使样本数量不多(每类1个样本),MDETR在少数类别中的表现优于微调的DETR,利用了文本的预学习。然而,令人好奇的是,当对整个训练集进行微调时,小物体的性能明显下降,从10%的数据的20.9个AP到100%的7.5个AP。
![]() 摘要
摘要
提出了多模态推理模型的端到端检测器MDETR,它在使用各种数据集的多模态理解任务以及其他下游任务(如数字拍摄检测和视觉问题回答)中表现良好。在其他下游任务中的表现,如数字拍摄检测和视觉问题回答。
与最近的Aplhafold2一样,本文是基于对DETR的研究,围绕多模态的研究,以及自我监督的学习(也许是Jan Lucan在这里的知识)。我觉得这篇论文有大量的研究作为支撑。



与本文相关的类别


![[MusicLM]谷歌开发的文本到音乐生](https://aisholar.s3.ap-northeast-1.amazonaws.com/media/October2023/musiclm-520x300.png)


