
LONGNET:一种可处理多达 10 亿 Token 文本的模型。
三个要点
✔️ 针对高效处理长序列的挑战提出了一个重要解决方案
✔️ 引入了 Dilated Attention,以降低 Transformern 的计算复杂性
✔️ LONGNET 引入了基于 Transformer 的 Dilated Attention 模型。模型。
LongNet: Scaling Transformers to 1,000,000,000 Tokens
written by Jiayu Ding, Shuming Ma, Li Dong, Xingxing Zhang, Shaohan Huang, Wenhui Wang, Nanning Zheng, Furu Wei
(Submitted on 5 Jul 2023 (v1), last revised 19 Jul 2023 (this version, v2))
Comments: Work in progress
Subjects: Computation and Language (cs.CL); Machine Learning (cs.LG)
code:

本文所使用的图片要么来自论文、介绍性幻灯片,要么是参考这些图片制作的。
概述。
LONGNET 提出了 Transformer 的变体,引入了一种名为 Dilated Attention 的新架构,该技术已成为 LONGNET 的一项创新。
由 LONGNET 提供。
- 解决了旧变压器的问题,即随着序列长度的增加,所需的处理能力也会迅速增加。
- 更好地处理长短序列
- 发现较长的上下文可提高语言模型的性能
能够处理 10 亿个代币的好处
十亿代币相当于 GPT-4 代币的约 25 万倍。从未有任何模型能够处理如此多的代币。因此,很难将整本书或整个网络输入模型。
作者提出了一种利用 LONGNET 线性扩展序列长度的方法,并提到了将来将整个网络数据集包括在内的可能性。他们还提到,LONGNET 的出现可能会改变语境学习的模式,因为它允许进行超长语境学习。
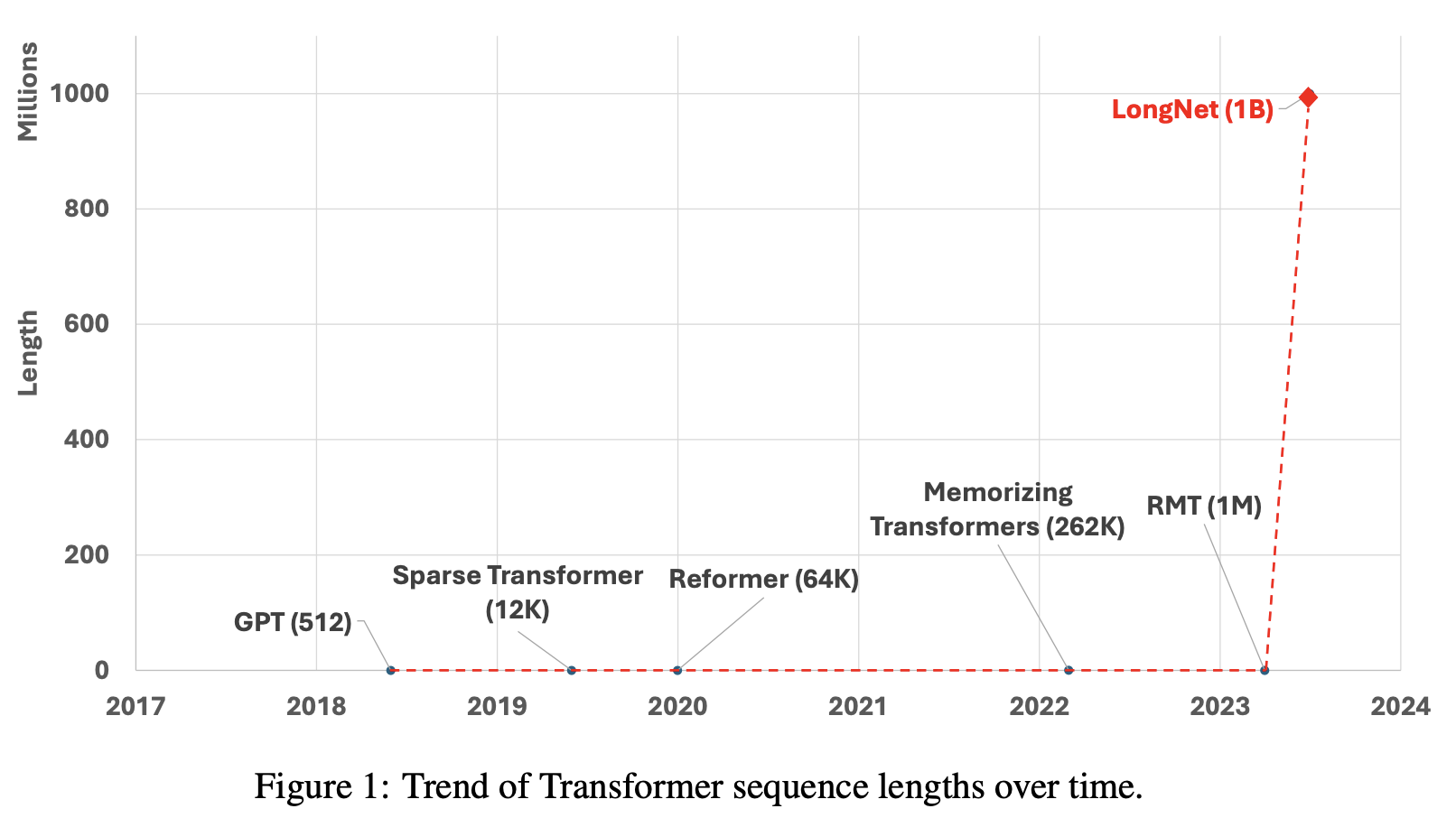
龙格网络诞生的背景
随着 LONGNET/Dilated Attention 的出现,"增加序列长度 "和 "降低变压器的计算复杂性 "这两个问题的解决方案被提出来。
尽管人们普遍知道,增加序列长度的好处是显著的,但使用 Transformer 时,计算量会变成序列长度的二次函数,所需的处理能力也会迅速增加。因此为了降低变换器的计算复杂度,LONGNET 引入了一个名为 "放大注意 "的新组件。
增加序列长度的好处
序列长度是神经网络的基本组成部分,一般认为拥有无限大的序列长度是理想的。增加序列长度还有三个好处。
- 它可以让模型接受更广泛的语境,并利用远处的信息更准确地预测当前标记。例如,这对于理解故事中间的口语或理解长篇文档非常有用。
- 它可以学习在训练数据中包含更复杂的因果关系和推理过程。(在论文中,似乎短的依赖关系通常更容易产生负面影响)。
- 它能让我们理解更长的上下文,并充分利用它们来改进语言模型的输出�
降低变压器的计算复杂度。
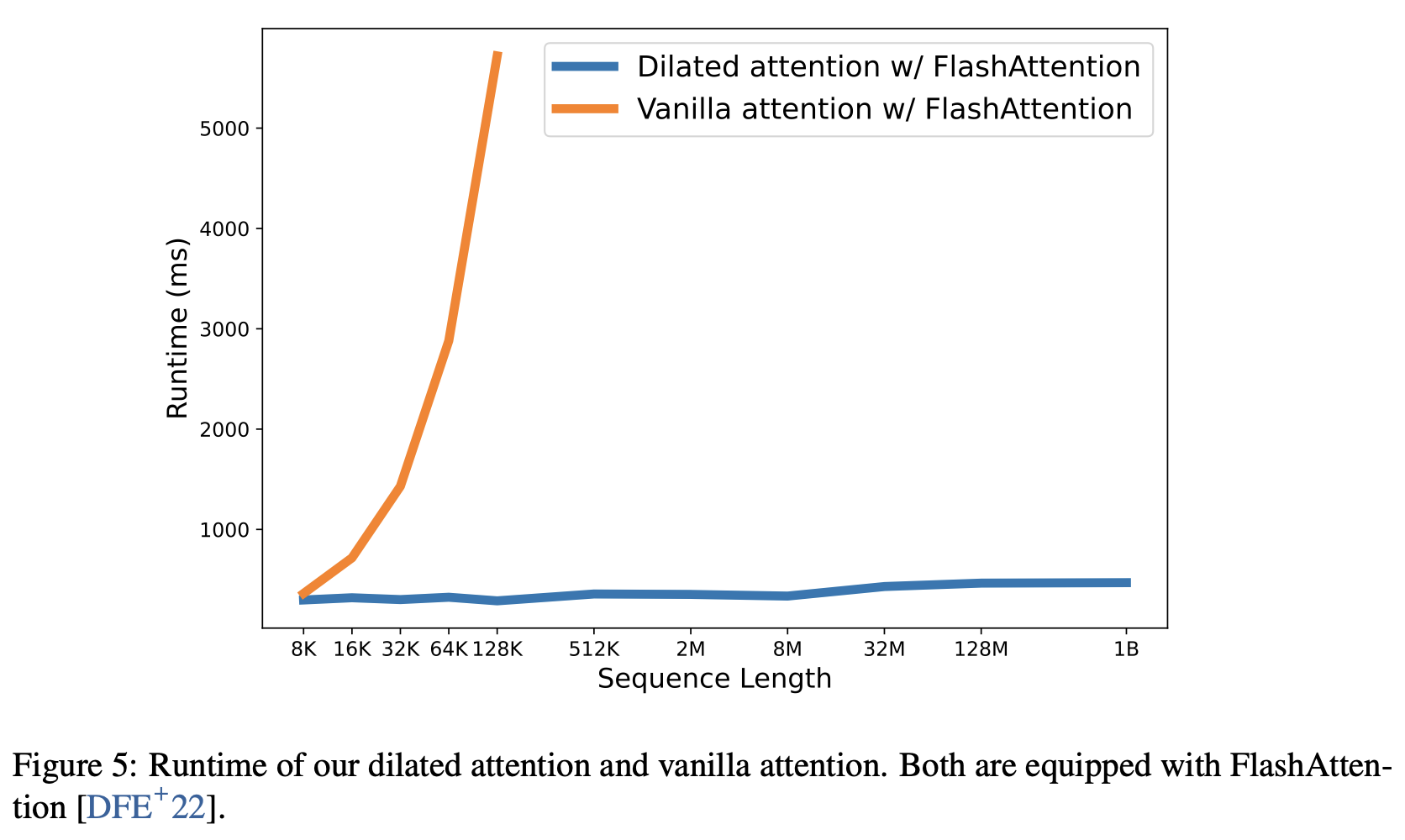
Transfomer 的计算复杂度随序列长度的增加而呈二次曲线增加。相比之下,本文提出的 Dilated Attention 的计算复杂度呈线性增长。
本文图 5 比较了 vanilla 和扩张注意力的效果。序列的长度(从 8K 到 1B)逐渐增加。在下图中,记录了每个模型在 10 种不同前向传播情况下的平均执行时间,并进行了比较。这两种模型都使用了 FlashAttention 内核,从而节省了内存并提高了速度。
从稀释的注意力可以看出,缩放序列长度的延迟几乎是恒定的。因此,可以将序列长度扩展到 10 亿 token。
另一方面,vanilla attention 的计算成本与序列长度成二次方关系,导致延迟随着序列长度的增加而迅速增加。此外,vanilla attention 没有分布式算法来克服序列长度的限制。
这一结果也显示了 LONGNET 线性复杂度和分布式算法的优越性。
与现有研究相比,计算复杂性提高了多少?
你们刚刚看到了计算复杂性的巨大进步。现在,让我们从理论角度来看看计算复杂度有了多大的提高。
计算复杂度的提高是通过采用一种名为 "稀疏注意"(Dilated Attention)的架构实现的;而降低变换器计算复杂度的典型尝试是 "稀疏注意"(Sparse Attention)。根据作者的比较,新提出的 Dilated Attention 与普通 Attention 和 Sparse Attention 相比,降低了 Attention 机制的计算复杂度,如下表所示。

在下一节中,我们将向大家展示为什么我们能以这种方式成功降低计算复杂度。
分散注意力:为什么可以提高计算复杂性?
我们将从公式中看到为什么 "稀释注意力 "降低了计算复杂度。
Dilated Attention 将输入 $(Q, K, V)$ 分割为长度为 $w$ 的片段 ${(Q, K, V)}^{frac\{N}{w}}$ 。
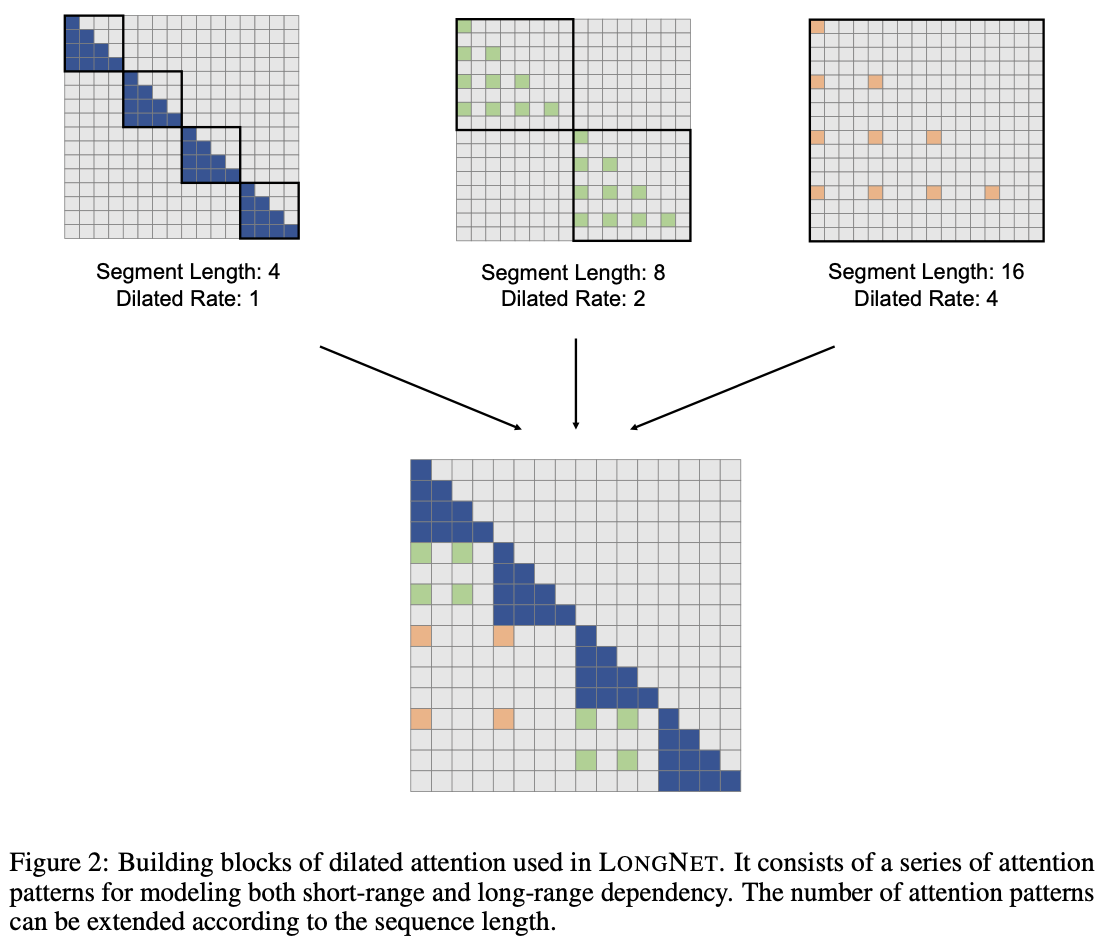
如图 2 所示,通过选取区间 $r$ 中的行,沿序列维度对每个线段进行稀疏化处理。实际公式如下。
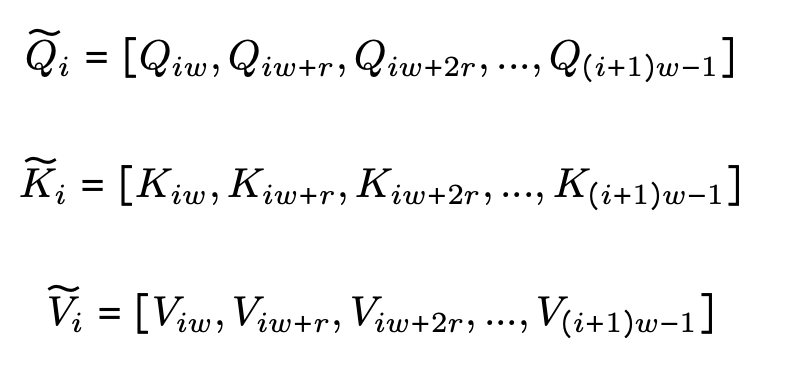 这个经过稀疏化处理的片段 ${(Q, K, V)}^{frac{N}{w}}$ 被并行送入 Attention。输入后,如果输入序列长度长于本地序列长度,它们就会被分散、计算并最终连接成输出 $O$。
这个经过稀疏化处理的片段 ${(Q, K, V)}^{frac{N}{w}}$ 被并行送入 Attention。输入后,如果输入序列长度长于本地序列长度,它们就会被分散、计算并最终连接成输出 $O$。
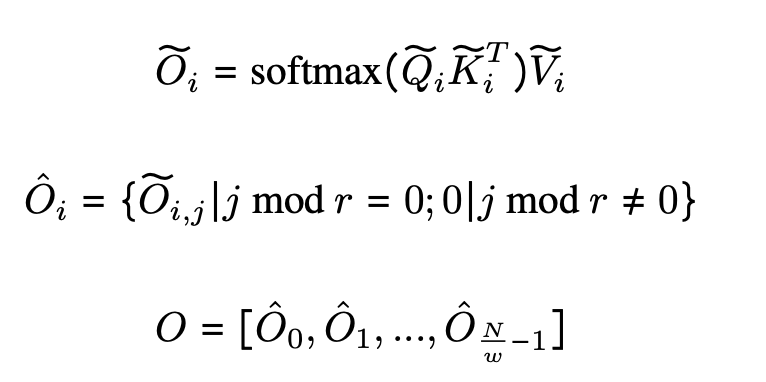
此外,在实现过程中,在对输入 $(Q,K,V)$进行收集操作和对输出 $widetilde{O_i}$ 进行操作之间,可以将 Dilated Attention 转换为 Dense Attention,这样就可以直接使用 Vanilla Attention,如 Flash Attention。Vanilla Attention 的优化,如 Flash Attention,可以直接使用。
在实践中,分段大小 $w$ 以注意力的全局性换取效率。另一方面,大小 $r$ 可通过近似 Dilated Attention 矩阵来降低计算成本。
LONGNET 分布式培训
Dilated Attention 的计算阶数已从 Vanilla Attention 的 $O(Nd)$ 大幅降低到 $O(N^2d)$。然而,由于计算资源和内存的限制,单个 GPU 无法将序列长度扩展到百万量级。因此,人们提出了用于大规模模型训练的分布式训练算法,如模型并行化、序列处理和流水线处理等。然而,传统方法对于 LONGNET 来说是不够的,尤其是在序列维数较大的情况下。因此,LONGNET 提出了一种新的分布式算法,该算法可扩展到多个设备而不失通用性。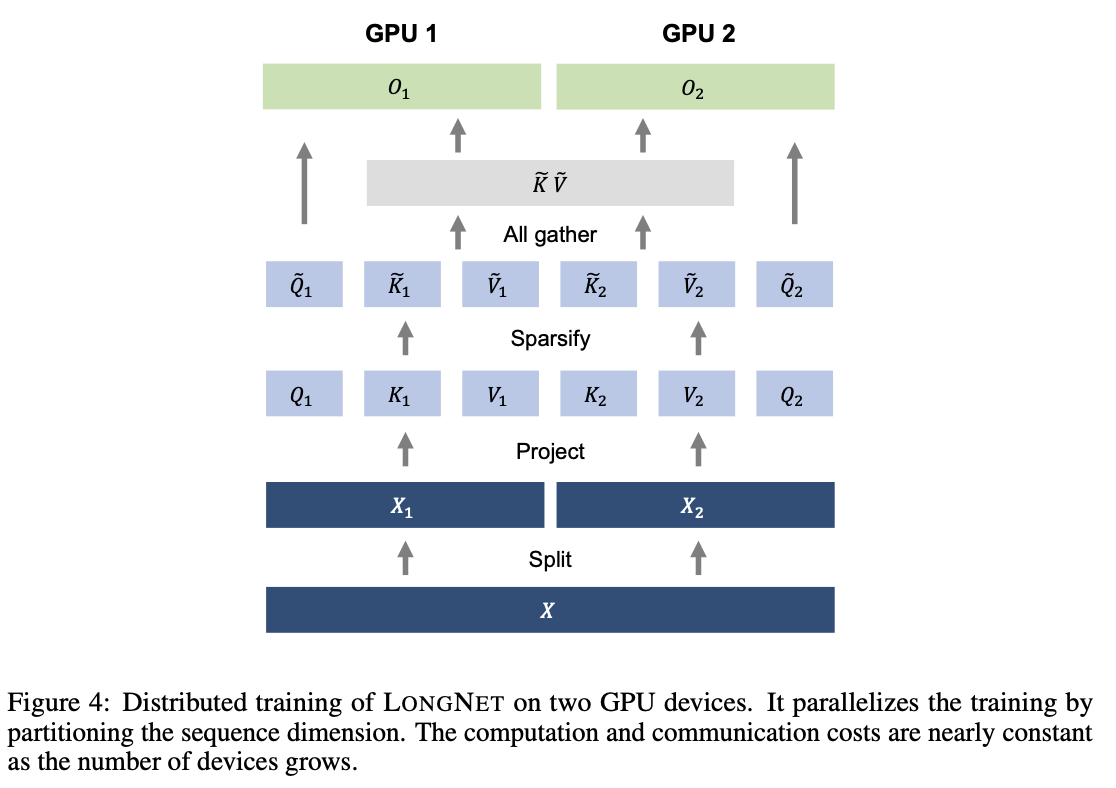
步骤 1:输入序列的分割
输入序列沿序列维度分割。每个分割后的序列被单独放置在一个设备上。
$x = [x_1 , x_2]$
两台设备上的查询、键和值也如下所示
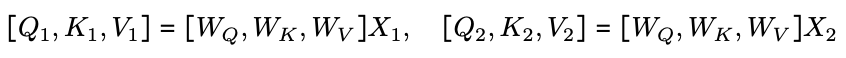
步骤 2:注意力的计算
当 $w_i \leq l$ 时,即输入段长度 ($W_i$) 短于本地设备序列长度 ($l$),则使用 Dilated Attention 中介绍的计算方法将其分解。
当 $w_i \geq l$ 时,键和值分散在设备上,因此在计算 Attention 之前,要执行一次全集操作来收集键和值。
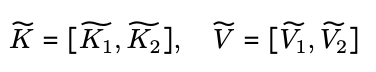
此时,与 Vanilla Attention 不同,密钥和值的大小都不取决于序列长度 $N$,因此通信成本保持不变。
步骤 3:计算交叉注意力
使用本地查询和全局键与值计算 Cross Attention。
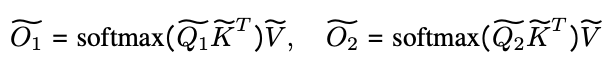
第 4 步:最终输出
最终的 "注意力 "输出是不同设备 Kanes 输出的合并结果,如下式所示。
语言建模实验
本文对语言模型进行了实际实施,采用的架构是 MAGNETO [WMH+22],使用 XPOS [SDP+22] 的相对位置编码。不过,它似乎用 Dilated Attention 取代了标准的 Attention。
LONGNET 与 Vanilla 变换器和 Sparse 变换器进行了比较。在将这些模型的序列长度从 2K 增加到 32K 的过程中,似乎对批次大小进行了调整,以保持每个批次的标记数不变。此外,由于作者计算环境的限制,他们只对最多 32K 的标记进行了实验。以下是每个语言模型的易错性结果。
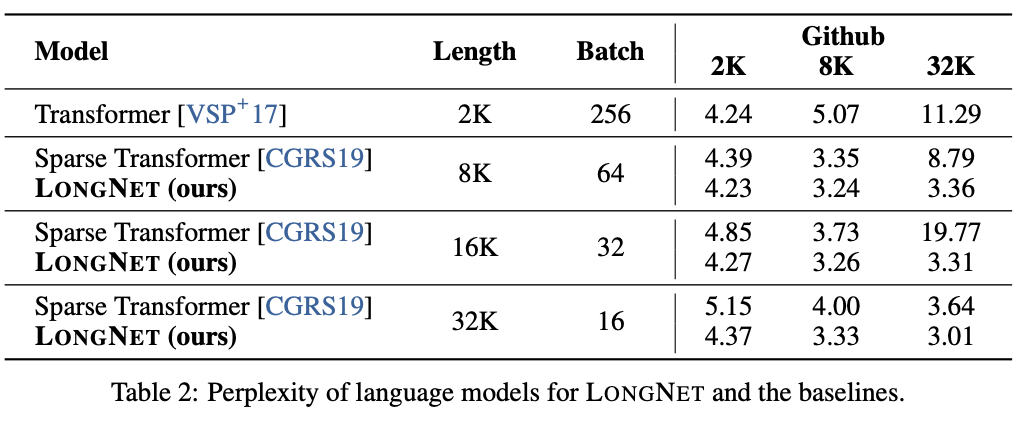
主要结果证明,在训练过程中增加序列长度可以获得良好的语言模型;在所有情况下,LONGNGET 的表现都优于其他模型,并显示出其有效性。
下图 6 绘制了 Vanilla Transformers 和 LONGNET 的序列长度缩放曲线。可以看出,LONGNET 符合缩放规律。从这些结果可以看出,LONGNET 可以更有效地扩展上下文长度,并在 Vanilla 变换器和 LONGNET 之间以更少的计算量显示出更高的性能。
摘要
作者计划扩展 LONGNET 的范围,以涵盖多模态大规模语言建模、BEiT 预训练和基因组数据建模等任务。预计这将使 LONGNET 能够处理更广泛的任务,并提供卓越的性能。
这也表明,如果能够接受较长的提示,就可以获得更复杂的输出,而不需要额外的学习,例如在提示中提供大量或大量的示例。



与本文相关的类别


![[MusicLM]谷歌开发的文本到音乐生](https://aisholar.s3.ap-northeast-1.amazonaws.com/media/October2023/musiclm-520x300.png)


