两个变形金刚可以共同组成一个强大的GAN!
3个要点
✔️ 全球首款纯变压器型GAN?
✔️ 一个记忆友好的生成器和一套新的学习技术,用于训练转化的GANs。
✔️ 利用基于CNN的GAN和新的SOTA在STL-10基准上取得了具有竞争力的结果。
TransGAN: Two Transformers Can Make One Strong GAN
written by Yifan Jiang, Shiyu Chang, Zhangyang Wang
(Submitted on 14 Feb 2021 (v1), last revised 16 Feb 2021 (this version, v2))
Comments: Accepted to arXiv.
Subjects: Computer Vision and Pattern Recognition (cs.CV)
code:

首先
自诞生以来,由于训练方法、损失函数和模型骨干演化,生成式对抗网络(GANs)经历了许多改进。目前最先进的GAN模型基本上都是卷积神经网络(CNNs)骨架。CNN是图像GAN的核心,虽然自我识别也被整合到网络中,但CNN仍然是核心。另一方面,变压器已经被部署在各种任务中,包括自然语言处理、计算机视觉、语音处理和3D点云处理。因此,人们自然会问:没有CNN,基于变压器的GAN如何工作?
在本文中,我们试图找到这个问题的答案,结果非常有趣。我们来看看一个纯粹的基于变压器的GAN模型。
我们还使用了两种新的学习方法,使其性能与当前的SOTA GAN相当:a.联合多任务学习与区域性感知初始化和数据增强。
为什么是CNN而不是Transformer?
众所周知,CNN在局部像素层面工作得非常好,但在捕捉全局特征方面却很弱。因此,为了有效地捕捉全局特征,CNN被堆叠成深度网络。CNN也是空间不变的,因为它们在不同的图像中共享相同的权重。另一方面,变形金刚能够很好地捕捉全局特征。在各种任务中取得成功,变换器是潜在的通用函数估计器,可以简化计算机视觉中基于CNN的复杂管道。
纯变压器的GAN之路
我们先为生成器和鉴别器建立一个简单的模型。然后,我们会根据该模式面临的挑战对其进行适当的修改。
香草味 TransGAN
TransGAN由一个变压器编码器组成,它由多头自注意,然后是一个GELU非线性MLP。这两部分都是在层归一化之前,同时进行残差连接。在图像上使用变换器的挑战之一是,即使是32x32的低分辨率图像,也会导致长度为1024的长序列,消耗大量内存。
![]()
为了在生成器中管理如此大的序列,我们逐步提升输入序列的尺度,并逐步降低维度(上图中为32x32x3),直到达到目标分辨率。在每个步骤中,1D序列被转换为2D特征图(HxWxC),对其应用像素洗牌,将形状转换为(2Hx2WxC/4)。这意味着在每一步上采样时,宽度和高度都会增加一倍,尺寸减少1/4。然后,当达到所需形状时,将尺寸转换为C=3(H)txWtx3)转换成
在判别器中,将输入图像(HxWx3)转换为8x8等值的斑点(图中仅以9个斑点为例)。每一个8x8=64的补丁都被扁平化,形成64个(上图中为9个)嵌入维度为'C'的"字"序列。cls]令牌被预置,整个序列通过变压器编码器层。如图所示,分类头只用[cls]令牌对应的编码来预测图像是真还是假。
改进香草型跨政府采购网
为了比较TransGAN和AutoGAN(基于CNN),我们尝试了两种模型的各种判别器(D)和生成器(G)的组合。在下列情况下CIFAR-10两个模型的结果如下图所示。
![]()
变压器发生器和CNN判别器的组合效果非常好,但纯GAN仍然落后。从这个结果来看,我们可以通过数据增强,通过增加训练数据来帮助它改进。以下是在CIFAR-10上训练的TransGAN和其他SOTA模型的前后数据增强结果。
![]()
我们觉得相比基于CNN的GAN,TransGAN从数据增强中获益更多。然而,这还是不够的。让我们试着用以下技术再训练一下TransGAN。
多任务协同培训(MM-CT)。
![]()
上图展示了多任务协作学习(MM-CT),这是一个可以稳定学习GANs的自我监督任务。在这种方法中,对训练图像进行下采样,形成低分辨率图像(LR)。然后,这些LR图像被传递到网络的中间(第2)阶段,在那里训练模型以获得高分辨率图像。除了标准的GAN损失外λ ∗ LSR(LSR为均方误差损失)加(经验上λ为50)。这两个任务不相关,但有助于生成模型学习图像表示。
本地化初始化
CNN天生擅长捕捉局部图像特征,这使得它们可以通过诱导图像偏差产生更平滑的图像。变形器的学习比较灵活,挑战在于如何像CNN一样学习图像的卷积结构。可以通过修改学习程序来实现,具体如下。
![]()
为了让自学习学习低层次的图像结构,我们在初始化系统时考虑到了局部性。如上图所示,我们在开始学习时,首先要对大部分像素进行遮挡,这样只有少数未被遮挡的相邻像素相互影响。然后,随着它的不断学习,它会逐渐增加接受场,直到完全没有被遮挡的像素。这样可以使生成器更加关注局部细节,形成更精细的图像。因此,它在学习的早期阶段优先考虑局部细节,然后在学习的后期阶段优先考虑更广泛的非局部互动。
MM-CT和区域性感知初始化可以显著提高TransGAN的性能,如下表所示。
![]()
TransGAN:扩大规模和评估
最后,用上述其他技术训练出来的vanilla TransGAN就可以推广了。不同深度(每一步的编码器块数)和嵌入大小的模型结果如下图所示。
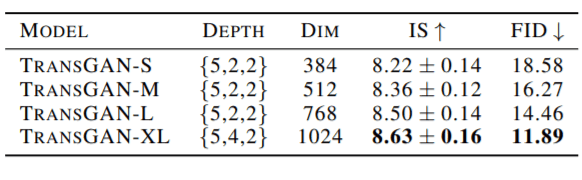
大规模TransGAN模型的结果与最先进的CNN GAN模型相当,甚至优于后者。
![]()
TranGAN也能在STL-10数据集上展示新的领域。结果如下:
![]()
如果你想知道生成的图像是什么样子的,这里有一个在三个不同数据集上训练的TransGAN样本。

结论
TransGAN的工作效果非常好,这也是传感器的简单性和普遍性的另一个例子。这项工作可能是未来几个有趣的纯跨GANs研究的开始。生成更高分辨率的图像,预训练变换器,使用更强的注意力形式,以及条件图像生成只是其中的一部分。详见论文原文。
这里推荐视频讲解。



与本文相关的类别



![[MusicLM]谷歌开发的文本到音乐生](https://aisholar.s3.ap-northeast-1.amazonaws.com/media/October2023/musiclm-520x300.png)


