Data Augmentationにおける2つの定量的なメトリクスとは?~Affinity and Diversity~
3つの要点
✔️ Data Augmentationを定量的に評価する2つのメトリクス~Affinity and Diversity~
✔️ 2つのメトリクスが共にハイスコアを取ったときモデルはAccを改善
✔️ DAによる正則化を途中でオフにすることの有効性を検証
Affinity and Diversity: Quantifying Mechanisms of Data Augmentation
written by Raphael Gontijo-Lopes, Sylvia J. Smullin, Ekin D. Cubuk, Ethan Dyer
(Submitted on 4 Jun 2020) (ver2)
Comments: 10 pages, 7 figures
Subjects: Machine Learning (cs.LG); Computer Vision and Pattern Recognition (cs.CV); Machine Learning (stat.ML)
code:
はじめに
DataAugmentation(以下DA)は,データを水増しすることで,モデルの過学習を防ぐテクニックです.DAによる正則化は,モデルの中身に触れる必要がないことから,汎化性能を向上させるためのお手軽なテクニックとして知られています.特に画像ドメインにおいては,タスクごとに応じて膨大な数のDAが研究・探索されています.なかでも最適なDAはタスクもしくはデータの性質によって,ケースバイケースで変化します.特に,画像ドメインにフォーカスすると,DAは大別して以下の2種類に分類でき,下記2種のDAを試行錯誤的に探索することで,最適なDAを見つけ出すのが一般的です.
- 画像の幾何学的な変換や光学的な処理.(Centercropやrotate等)
- 領域削除やブレンドといった処理(CutoutやCutmix等)
1.の幾何学的な変換に関しては,画像を回転させたりすることで,テストデータに近似した学習データを水増しします.例えば,植物の画像分類等では,テストデータの撮影角度は学習データと異なる可能性が考えうることから,回転がどうやら有効そうなことが分かります.光学的な変換に関しても同様に明るさ調整等の処理は有効そうな気がします.これらDAの立場としては,そもそも学習データとテストデータの分布がある程度近似しているはずだ,という暗黙的な仮定に基づいています.
ですが,2.に関してはどうでしょう.領域削除(Cutout)やブレンド(Mixup)によって作り出された画像は,もはやテストデータに近似しているでしょうか? 合体させた手法であるCutMixにおいては,恐らくテスト画像に含まれないであろうデータを作っているにも関わらず,種々の画像認識タスクにおいて有効な結果を残していることが確認できます.このように,昨今では,「学習データからある程度逸脱したAugumentを行っても有効な場合がある」という別な知見が見いだされつつあります.これも含めDAの有効性の評価については,ケースバイケースの定性的な評価(CAM画像等)が普通で,定量的なメカニズムについては良く分からないままでした.
Google Brainの研究者によって発表された”Affinity and Diversity: Quantifying Mechanisms of Data Augmentation”では,DAの定量的な評価方法,また評価結果が包括的に示されております.具体的には,Affinity(親和性), Diversity(多様性)の2つのDA評価のメトリクスが提案され,それに基づく各種DAの包括的な評価がなされております. 本記事では,この論文について解説していきます.(本記事で掲載している画像は,すべて原著論文からの引用です)
DAを評価する2つのメトリクス
原著論文では原著表題の通り,Affinity(親和性)&Diversity(多様性)の2つのメトリクスが提案されています.論文中の文章を引用すると,
1. We introduce Affinity and Diversity: interpretable, easy-to-compute metrics for parameterizing augmentation performance. Affinity quantifies how much an augmentation shifts the training data distribution from that learned by a model. Diversity quantifies the complexity of the augmented data with respect to the model and learning procedure.
Affinityは,Augmentationが学習データ分布をモデルが学習した分布からどれだけシフトするかを定量化する.Diversityは,モデルと学習した手順に関連してAugmentされたデータの複雑性を定量化する.
(”Affinity and Diversity: Quantifying Mechanisms of Data Augmentation” p2 introductionより引用)
とあります.
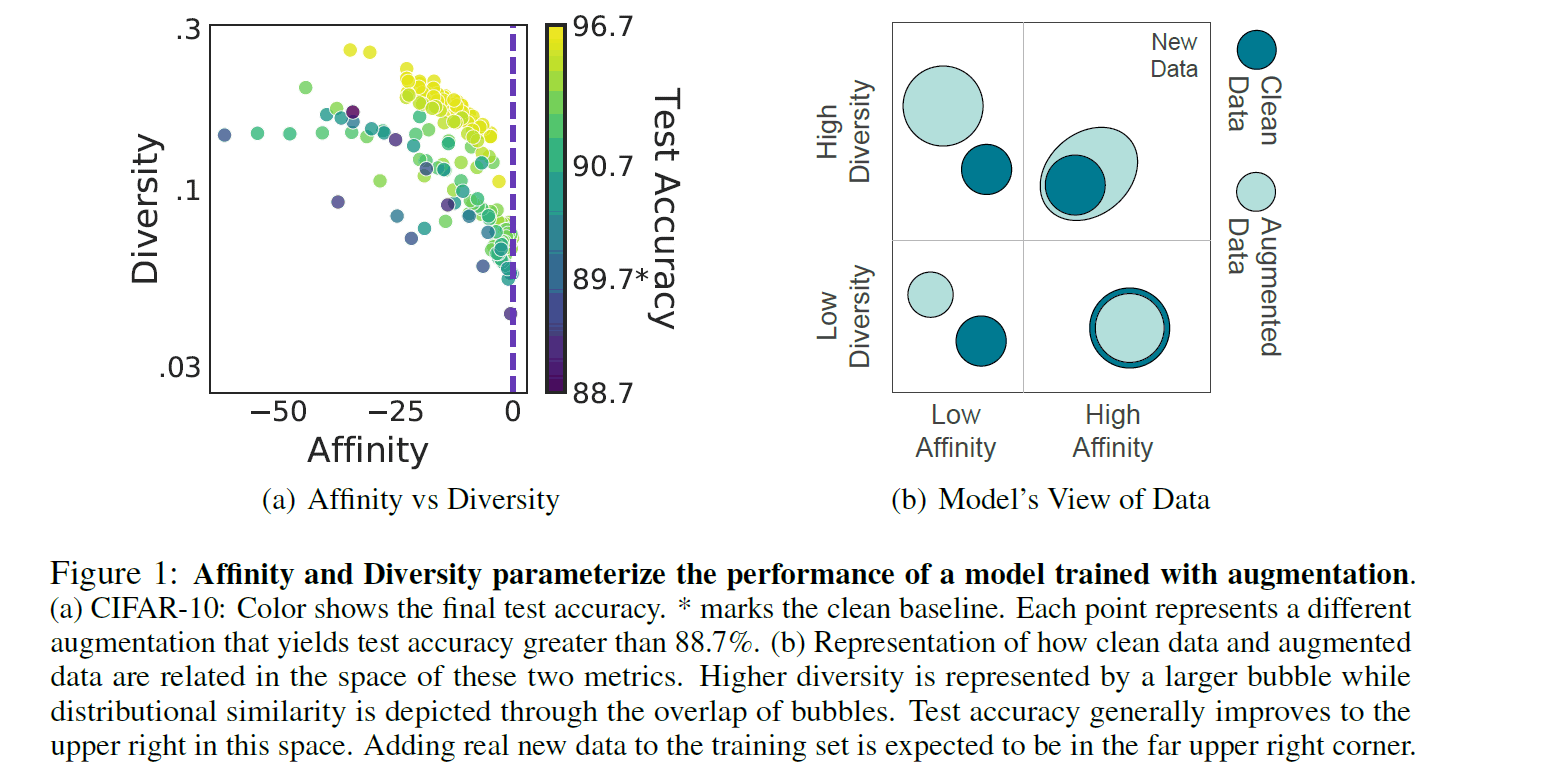
このメトリクスを直感的に解釈するために,上右図を参照してみましょう.Clean Dataは拡張されていないデータの分布,Augment DataはDAにより拡張されたデータの分布を指します.まずDiversity軸で見てみると,High Diversityの場合はAugumentデータの分布が広くなっていることが確認できます.実際的な観点では,繰り返しの確率的なDAによって異なる種類の複雑なデータが生成され,分布が多様的になったことを意味します.次に,Affinityの軸で見てみると,High Affinityの場合はAugument Dataの分布がClean Data分布に重なっていることが確認できます.同じく実際的な観点では,元のデータに比較的近いデータが生成され分布間が親和的になったことを意味します.
では,AffinityとDiversityがどうなれば良いDAと言えるのでしょうか,左図を参照してみましょう.各軸がメトリクス,それぞれのドットは個々のDAを意味しています.そして,ドットの色はCifar10のテストデータのAccを示しています.Yellowに近い色の方が,高いテスト精度だったことを意味しています.ここから確認できるのは,Yellowに近いドット(DA)は,AffinityとDiversityの両メトリクスが高いところに分布していることです.肝要なのは,片方のメトリクスだけが高くても,必ずしもテスト精度は高くないことが挙げられます.このように論文中では,両メトリクスの値が高く,一定の均衡を保つDAがテスト精度を上げたと主張されています.
Affinity
それぞれの評価値について見ていきましょう.Affinityの算出方法は下図の立式で定義されます.
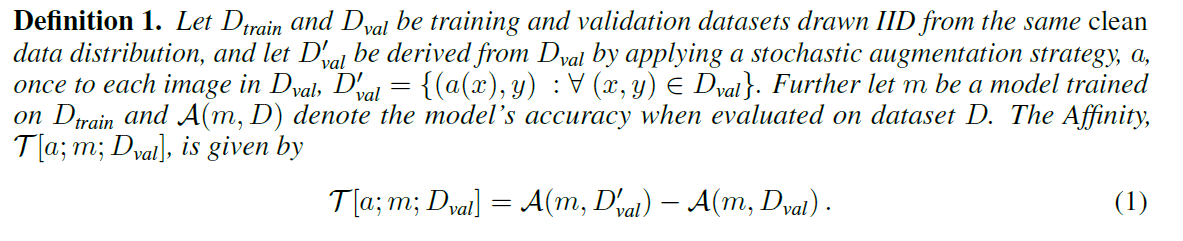
ここで,図中の文章より,
"$D_{train}$, $D_{val}$はクリーンデータ分布から引き出された学習データと検証データ.$D’_{val}$は確率的なDAによって$a$というAugmentにより, $D_{val}$の分布から引き出されたデータ.$m$はクリーン学習データ$D_{train}$にて学習したモデルで,$A(m, D)$はデータセット$D$によって検証したときのモデルのAccuracyであり,Affinityは下式で表現される."
とあります.すると,Affinityは上式のように,特定のモデルmを拡張検証データ$D’_{val}$によって検証したAcc,クリーン検証データ$D_{val}$によって検証したAccの差によって定義されます.ここでは,$D’_{train}$, $m$を両項で固定することで,拡張データ$D’_{val}$がどのように学習済みモデル$m$の精度に作用するかを数値化していることが確認できます.ただ入力データの分布を評価するのではなく,モデルのテスト精度に紐付けることで,モデルに基づいた分布シフトを測定しています.この定義から,Affinityが0に近いほど親和的,すなわち拡張データがモデルに及ぼす作用が,学習データと差がないことが確認できます.勿論,拡張されたデータ$D’_{val}$によって検証するわけなので,Affinityは正の値を取らないことが数式から確認できます.
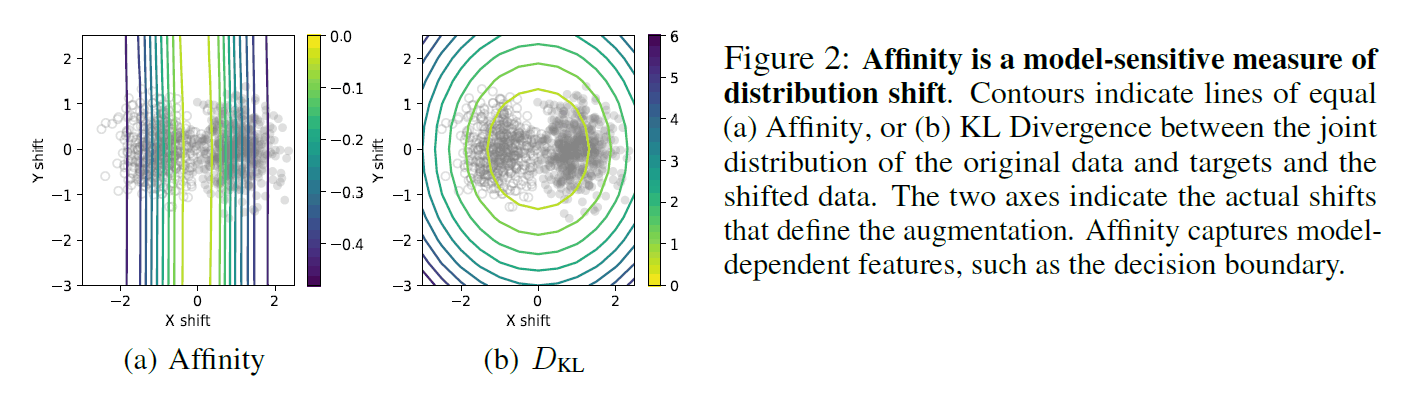
上図はAffinityを既存のKL距離と比較したものです.2つの混合ガウス分布で2値クラス分類タスクによるシミュレーションです.色のついた線はそれぞれAffinity, KL距離を意味しており,その線上で値が一致していることを意味しています.この図からは,Affinityは幾つかの縦線,$D_{kl}$は同心円状に描写されていることが確認できます.実際のガウス分布から引き出されるデータが2種のドットで示されていますが,Affinityに関しては決定境界のような線引きがなされているのに対して,$D_{kl}$に関してはXやYの分布シフトのおいて,モデルの精度とは直接関係ない方向に軌跡を描いていることが確認でき,モデルの特徴を捉えるAffinityの有効性を確認できます.
Diversity
次にDiversityは下式のように定義されます.
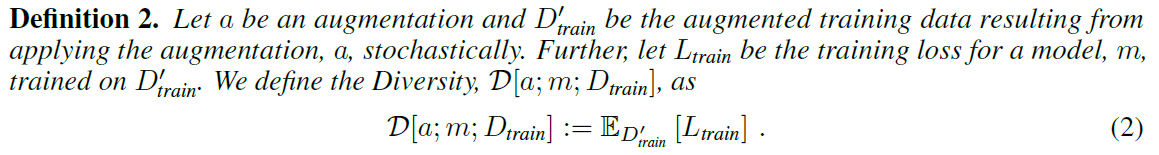
ここで図中の文章より,
$a$はaugmentであり,$D’_{train}$は確率的戦略に基づく$a$というaugmentの適用により拡張された学習データセットである.さらに$L_{train}$は$D’_{train}$によって学習されたモデル$m$の学習損失である.するとDiversityは下式で表現される.
とあります.モデルの学習損失$L_{train}$は,$D’_{train}$によって学習した結果であるため,$D’_{train}$に基づき最終的な期待値を算出することでDiversityは定義されます.以上2つの数式を見たあとに,最初のAffinityとDiversityの引用を省みると,より理解が深まると思います.
両メトリクスを用いたDAの解析結果
論文ではこの両メトリクスを駆使して,各種DAの包括的な解析に取り組まれています.具体的には下記の3つです.
- 従来DAにおける両メトリクスの定量的評価
- 途中で正則化(DA)をオフにした際の効果検証
- 静的なDAと動的なDAの比較評価
従来DAにおける両メトリクスの定量的評価
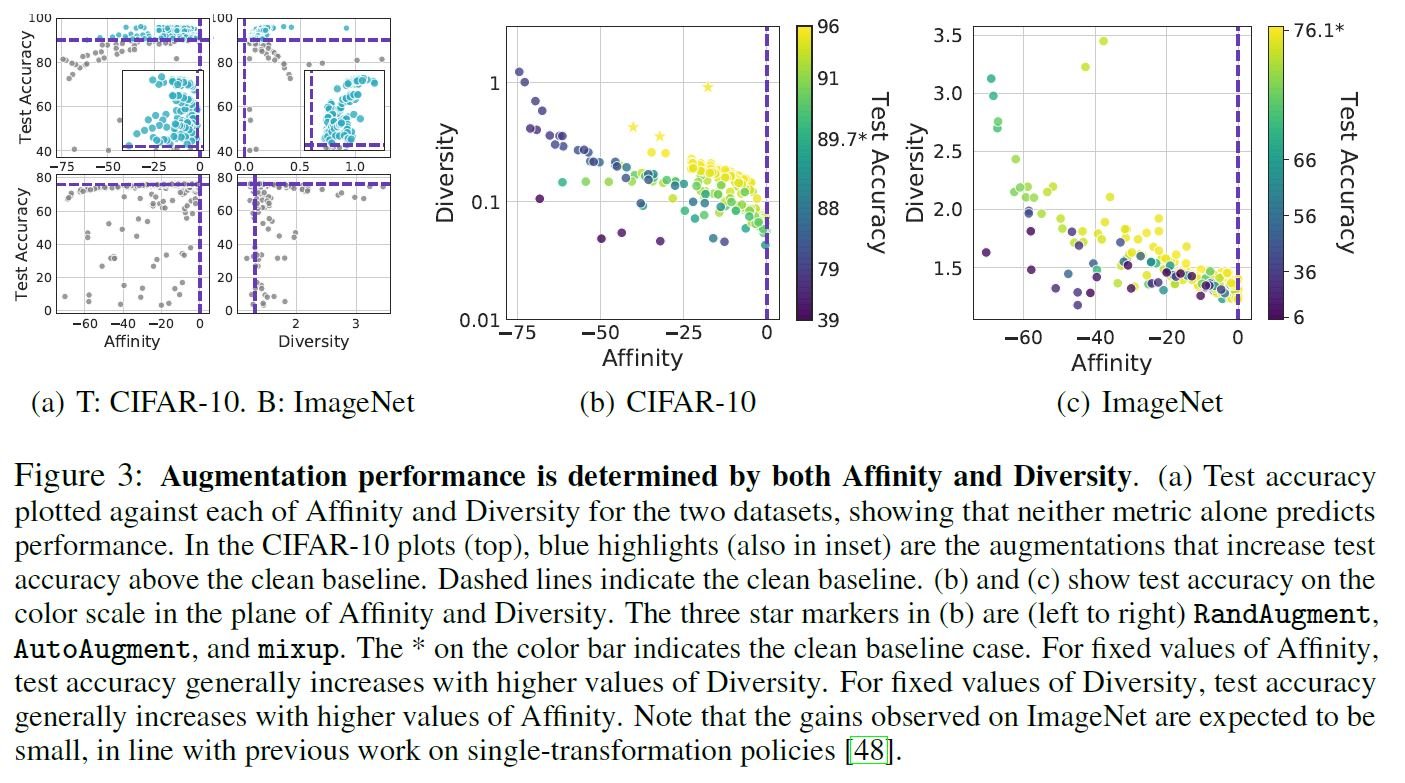
論文では,CIFAR-10とImageNetデータセットを対象に,各種DAにおけるAffinity, Diversity, Test Accが算出されています.上図(a)は各メトリクスを単独で評価した二次元平面の図です.上行(CIFAR-10)を見てみましょう.青の破線がクリーンデータのベースライン,水色ドットがベースラインを超えたDAですが,必ずしもTestAccが片方のメトリクスに連動していないことが確認できます.下行(ImageNet)のAffinityを見てみるとより顕著です.下図(b)(c)は両メトリクスを縦軸と横軸,TestAccを色軸で表現した三次元の図ですが,こちらで評価すると,AffinityとDiversityが互いの均衡を保ち,且つハイスコアのとき,TestAccが高いDAになっていることが確認できます.(親和性が同じ値のときはDiversityが高い方がTestAccは高く,逆もまた然り) 尚(b)と(c)ではAffinity, Diversityともに縮尺が異なります.
途中で正則化(DA)をオフにした際の効果検証
また,論文ではDAを途中でオフにした場合の実験結果が説明されています.昨今,正則化は特定のタイミングでオンオフを切り替える(もしくは正則化の具合を変える)ことが,モデルの改善に働くことが分かってきていますが(weight decayなどもその一種),ここではDAもその正則化の一種とみなして,途中でDAをオフにした場合の結果が示されています.詳しい背景や結果は原著をご参照ください.
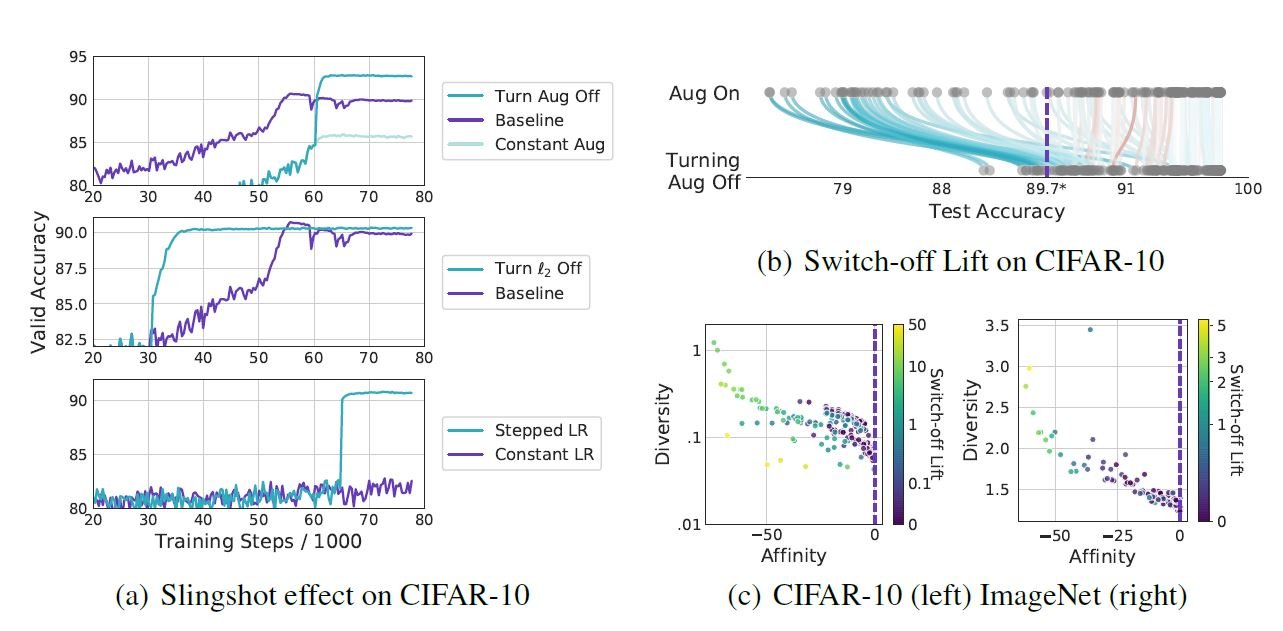
上図(a)の上行はCIFAR-10の学習にて,途中でDA(ここではrotate)を55k iterationのタイミングでオフにした場合(Turn Agg off)が示されています.すると,DAをオンにし続ける(Constant Aug)やBaselineと比べてValid Accのスコアが改善されていることが分かります.原著ではこれをSlingshot effectと呼んでいます.Constant AugがBaselineを下回っているのが目を見張ります.これはConstantに有効でないDAでも,途中でオンオフを切り替えることで,ベースラインを超える有効なDAになりうる可能性を示しています.尚,(a)の他の結果に関しては,DAとは異なる別な正則化を途中で切り替えたときの,結果が乗っています.次に,上図(b)は各種DAを途中でオフにした際の包括的な結果が乗っています.ベースラインを下回っているDAでも,概ねAug Onにし続けるより,途中でオフにしたほうがTestAccが改善されていること(青線)が確認できます.この改善を原著ではSwitchoff liftと呼んでいます.上図(c)ではSwitchoff liftの大きさはこれもAffinityとDiversityと何らかの相関があることを示唆しています.
静的なDAと動的なDAの比較評価
論文では下記文章のように,
"Unless specified otherwise, data augmentation was applied following standard practice: each time an image is drawn, the given augmentation is applied with a given probability. We call this mode dynamic augmentation. Due to whatever stochasticity is in the transform itself (such as randomly selecting the location for a crop) or in the policy (such as applying a flip only with 50% probability), the augmented image could be different each time."
(”Affinity and Diversity: Quantifying Mechanisms of Data Augmentation” p3, 3.Methodより引用)
特定の画像が確率的な戦略に基づいて変換される標準的なDAを動的なDAと呼んでいます.反面,確率的戦略を取らないものを静的なDAと呼んでいます.
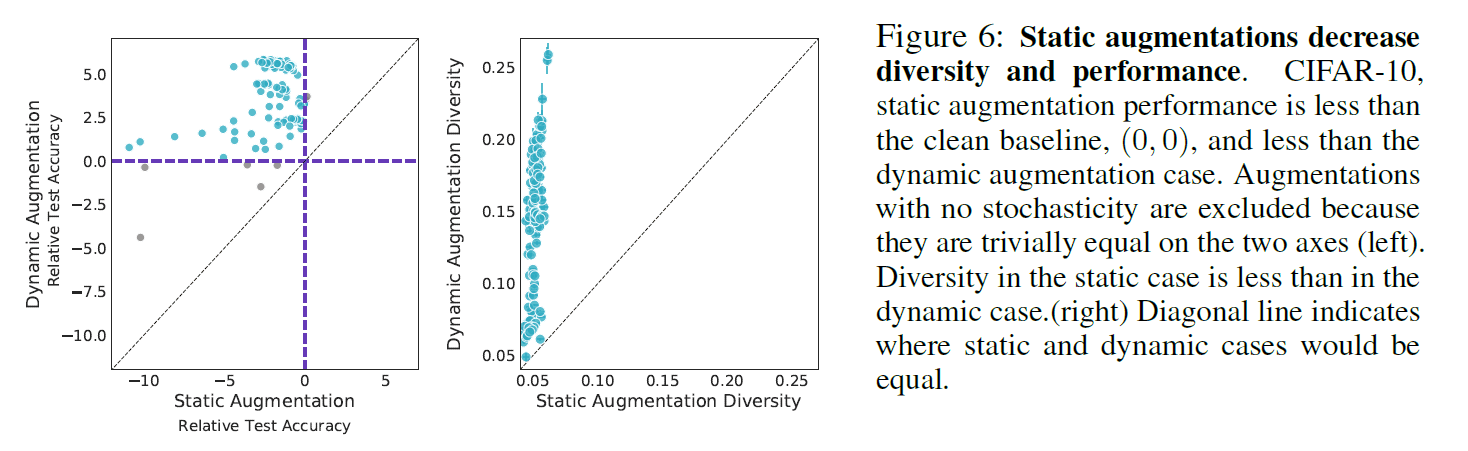
上図では,確率的戦略を取らない静的なDAが,確率的な戦略をとる動的なDAと比べて精度が悪いことを示されています.左図からは静的なDAは常に動的な場合と比べて相対的にTestAccのスコアが劣っていることが確認できます(黒の破線よりも下に来ているDAがない).これは右図のように静的DAはDiversityにおいても動的なDAと比べて低い,即ち多様性が乏しいことが原因かもしれないと示唆されています.
まとめ
本記事では,初めてDAのメカニズムを定量的に解析したGoogle Brainの研究者による”Affinity and Diversity: Quantifying Mechanisms of Data Augmentation”について解説しました.このようなDAの定量化により,DAそのもののメカニズムを解明できることや,DAのみならず正則化全体の知見の獲得に繋がることが,非常に機械学習の奥深さを体現しているように記事執筆者は思いました.定性評価に基づくDAの提案のみならず,今後はこの両メトリクスを軸に,定量的な観点で新たなDAを提案する流れも出てくるような予感がしています.





この記事に関するカテゴリー






