視覚タスクのためのTransformerハイブリットモデル:BoTNet
3 つの要点
✔️ 畳み込み層とself-attention層を用いたハイブリットアーキテクチャ
✔️ 畳み込み層飲みのネットワークと比較し、モデル性能が向上
✔️ 物体検出、インスタンスセグメンテーション、画像認識の各タスクで良好な結果を獲得
Bottleneck Transformers for Visual Recognition
written by Aravind Srinivas, Tsung-Yi Lin, Niki Parmar, Jonathon Shlens, Pieter Abbeel, Ashish Vaswani
(Submitted on 27 Jan 2021)
Comments: Technical Report, 20 pages, 13 figures, 19 tables
Subjects: Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI); Machine Learning (cs.LG)
code:
はじめに
今日の画像認識・インスタンスセグメンテーション・物体検出などのコンピュータビジョンタスクは、Deep Convolutional Neural Networks(Deep CNNs)を一般的に使って行われています。これらのネットワークは通常、3x3サイズの畳み込み層で構成されており、局所的な情報を捉えることに長けています。多くのconvnetを積み重ねることで、大域的な情報にも適応していこうとしている流れもあります。TransformersやMHSA(Multi-Head Self-Attention)ネットワークは、NLPタスクに必要な大域的な情報を捉えるのに非常に適しています。したがって、MHSAを用いて大域的な情報を取得し、CNNを用いて局所的な情報を取得することで、パフォーマンスの向上が期待できると直感的に考えることができます。
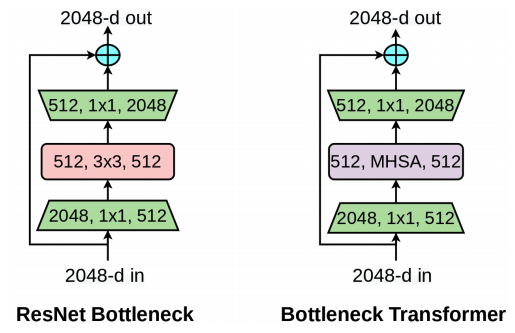 ResNet Bottleneck BlockとBottleneck Transformer(BoT) block
ResNet Bottleneck BlockとBottleneck Transformer(BoT) block
本論文では、ResNetアーキテクチャ内の畳み込み層をMHSA層で置換したハイブリッドネットワークを紹介します。これにより、ネットワークの大域的な情報の捕捉能力を向上させると同時に、 畳み込み層の持つダウンサンプリングや局所的な特徴捕捉能力を利用したハイブリッドネットワークを実現した。
The Bottleneck Transformer Network(BoTNet)

BoTNetアーキテクチャをResNet アーキテクチャと比較し、表に示しています。それぞれのアーキテクチャは、4つのステージ [c2,c3,c4,c5] で構成されており、それぞれが複数の残差ブロックで構成されています。BoTNetの唯一の違いは、最終スタックの3x3 畳み込み層がMHSA層で置き換えられていることです。
self-attentionブロックの計算量は、O(d2n)であり、nはエンティティの数,dはそれらのエンティティの次元数です。解像度1024x1024の画像の場合、かなりの計算量を必要とすることがわかります。そのため、MHSAは特徴量マップの解像度が小さくなる最後の部分にのみネットワークに組み込まれています。ResNetの最初のブロックでは、画像をダウンサンプルするためにストライド2コンボリューションを使用します。BoTブロックでダウンサンプルするために、第5スタックの第1層でストライド2average pooling層を使用しています。

ImageNetのような小さい画像サイズの場合、MHSAに達すると、5番目のスタックで特徴マップがかなり小さくなる(1024x1024の大きい画像では64x64または32x32であるのに対し、224x224の小さい画像では14x14または7x7である)。そこで、c5ブロック群の最初のブロックの2つのストライドを省いたBoTNet-S1アーキテクチャを導入します。すなわち、初期入力画像サイズが小さいものに対しては、あまりにも小さくならないような配慮を行ったモデルというわけです。
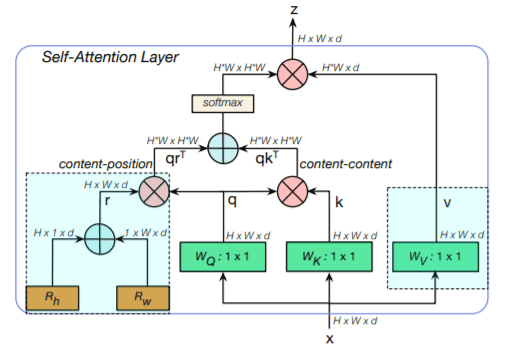 MHSA used in BoTNet
MHSA used in BoTNet
上図は、all2all attentionと呼ばれるBoTNetで使用されるMHSAを示しています。1x1は1x1 convolutions、+はelement-wise sum、Xはmatrix multiplicationを表しています。各BoTブロックは、上記の4つのアテンションヘッドで構成されています。2つの相対位置エンコーディング:高さと重みの2つのエンコーディングが、2次元特徴量マップに空間情報を追加するために利用されます。これらのエンコーディングは一緒に追加され、クエリ行列のコピーに乗算されます。self-attention操作はqrT+qkTで与えられます。ここで、k,q,r はそれぞれキー,クエリ,位置エンコーディングを表します。数学的には、このブロックは以下のように動作します。
q = conv1x1Wq(X), v= conv1x1Wv(X), k=conv1x1Wk(X)
Y = Softmax(qrT+qkT)v
評価
BoTNetアーキテクチャは実装が非常に簡単ですので、本論文の目的ではありません。本論文の目的は、畳み込み層とself-attention層を用いたハイブリットアーキテクチャがコンピュータビジョンタスクにおいて有効であることを証明することです。そのために、畳み込み層のみのネットワークであるResNet, EfficientNets, SENetsと、畳み込み層とself-attention層を持つBoTNetを用いて、ビジョンタスク(画像認識、インスタンスセグメンテーション、物体検出)の実験を行います。self-attentionブロックを組み込むことで、以下に示すように、様々なタスクにおいて性能向上を実現しています。
BoTNet vs ResNet
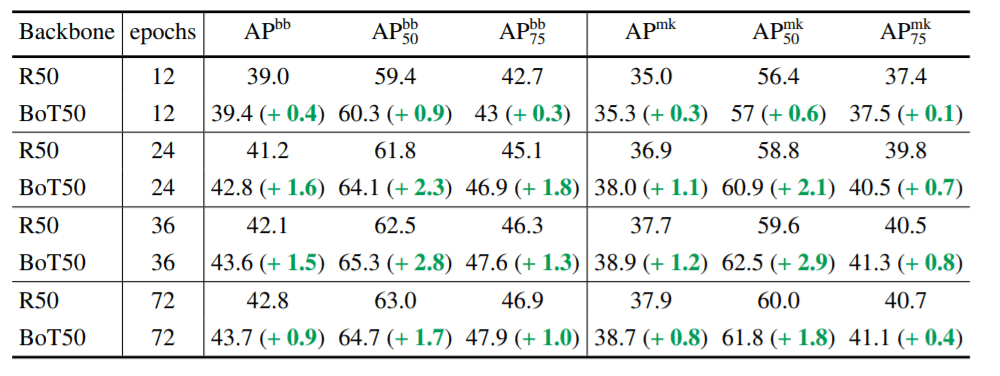 BoTNet vs ResNet on COCO
BoTNet vs ResNet on COCO

BoTNet vs ResNet on ImageNet
上の表は、COCOデータセット上で学習したResNet-50 backboneとBotNet50 backbone Mask-RCNNアーキテクチャの結果を示し、下の表はImageNet上での画像分類性能を示しています。self-attentionベースのBoTNetは、すべてのケースでResNetアーキテクチャを上回る結果となりました。また、BoTNetはResNetよりもmulti-scale jitteringなどの拡張機能の恩恵を受けていることがわかります。
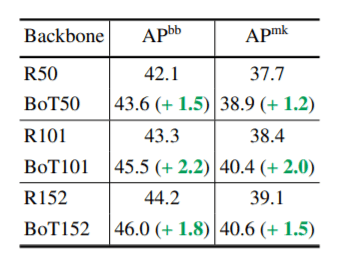
上の図は、multi-scale jitterを用いて1024x1024の解像度の画像を36エポックで学習したより大きなResNetアーキテクチャでもMHSAの性能が向上していることを示されています。
BoTNet vs EfficientNets vs SENets
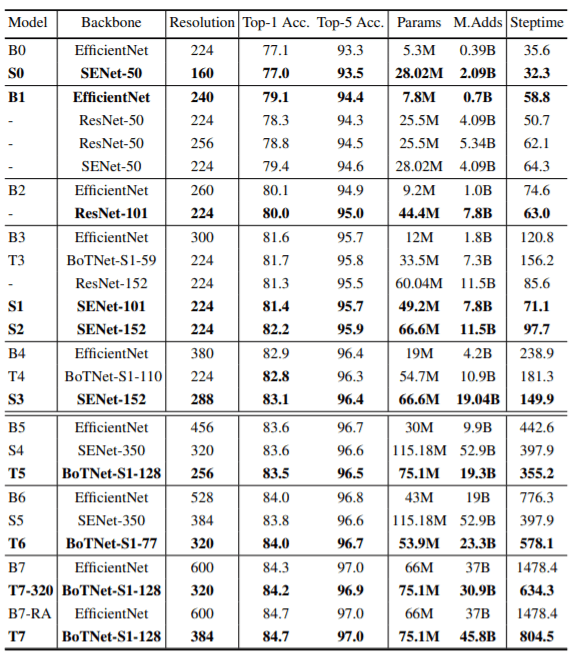
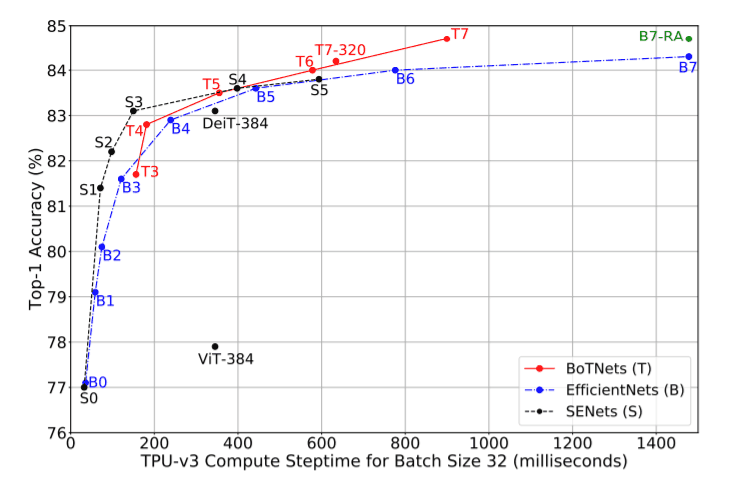
上のグラフは、BoTNetsがEfficeintNets、SENets、ViT、その他の自己注意型ネットワークと比較してどうかを示しています。高精度モデルに対しては、EfficientNetsよりもBoTNetsの方がはるかに効率的であることがわかります。EfficientNetsはパラメータ数が少ないものの、最新のTPUのパワーを活用できていないようで、ほとんどすべてのケースでResNetsやSENetsよりも遅くなっています。SENetsは低精度領域のモデルでは非常に優れた性能を発揮しますが、高精度領域のモデルでは遅れをとっています。
どの程度self-attentionは必要なのか?

上図は、異なる数の3x3畳み込み層をMHSAで置換して実施したアブレーションの結果です。[x1,x2,x3]は、3つの畳み込み層を表します。0は置換されていないことを意味し、1は置換されていることを意味します。R101、R50ともに、BoT50、BoT101の適切な構成によって打ち負かされていることがわかります。この結果から、MHSAブロックを増加させても、必ずしも性能が向上するわけではないことが示唆されます。しかし、畳み込み層を積み重ねるよりも、何らかの形のself-attentionに置換した方が優れているとも言えます。
結論
この論文での実験は、self-attentionとCNNを組み合わせることで、コンピュータビジョンの精度を向上させることができるということがわかりました。ただこれは、全て畳み込み層を構成するよりは良いアプローチであると思われます。今後の研究では、self-attentionをDETRのような他のモデルに置き換えてみたり、JFC, YFCC, Instagramのような大規模なデータセットにスケールアップする必要もあるでしょう。このようなハイブリッドネットワークが、将来の最先端モデルを開発するためにあたって、どのように適用できるかを見て行くのは興味深いことです。





この記事に関するカテゴリー






