モーダル依存のないトランスフォーマー:Perceiver Model
3つの要点
✔️ 複数のタスクで優れた性能を発揮するクロスモーダルなトランスフォーマーベース
✔️ 100,000入力以上のシーケンスを処理する能力を有する
✔️ ImageNet、AudioSet、ModelNet-40のSOTAモデルと同等以上の性能を発揮
Perceiver: General Perception with Iterative Attention
written by Andrew Jaegle, Felix Gimeno, Andrew Brock, Andrew Zisserman, Oriol Vinyals, Joao Carreira
(Submitted on 4 Mar 2021)
Comments: Published on arxiv.
Subjects: Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI); Machine Learning (cs.LG); Sound (cs.SD); Audio and Speech Processing (eess.AS)
code:
はじめに
人間や他の動物は、周囲の環境を認識するために、視覚、音声、触覚などの高次元のマルチモーダル情報を処理しています。一方、ニューラルネットワークは、学習された特定のタスクを実行するのにしか適していません。CNNは、画像に対する強い帰納的バイアスを持つため、コンピュータビジョンに革命をもたらしました。しかし、マルチモーダル・データセットのサイズが大きくなっていることを考えると、このようなバイアスがモデルの能力を制限しているのではないかと疑問を持つのは自然なことです。
この論文では、同じトランスフォーマーベースのアーキテクチャを使用して、任意の構成の異なるモダリティを扱うPerceiverモデルを紹介します。トランスフォーマーを選んだのは、誘導バイアスがほとんどなく、拡張性に優れているからです。現在のビジョントランスフォーマーは、ピクセルグリッド構造や積極的なサブサンプリング技術を用いて、self-attentionネットワークの計算コストを削減しています。そこで50000ピクセルを直接かつ柔軟に扱うことを可能にする新しいメカニズムを導入します。
Perceiverの性能は、ImageNetのResNet-50のような強力なビジョンモデルや、AudioSetのサウンドイベント分類ベンチマークにおける最先端の性能、ModelNet-40の点群分類における強力な性能に匹敵しています。
The Perceiver
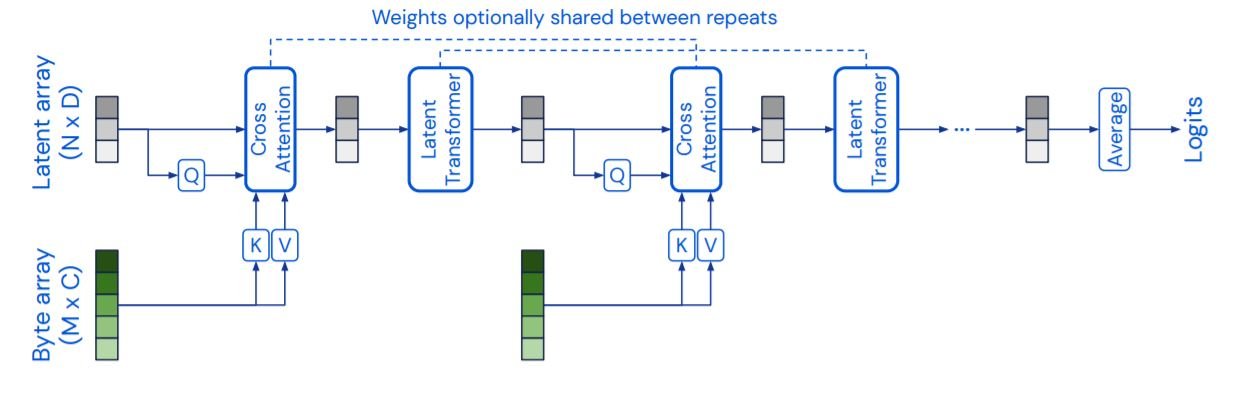
Perceiverは、cross attentionと潜在的なトランスフォーマーの2つの主要コンポーネントで構成されています。cross attention・トランスフォーマーは、潜在的な配列とバイト配列をマッピングします。潜在トランスフォーマーは、潜在配列を潜在配列にマッピングするトランスフォーマータワーです。バイト配列のサイズは入力タイプによって異なり、224x224の画像の場合は約50176です。潜在配列のサイズはもっと小さく、ImageNetの場合は約1024です。cross attention層と潜在的なトランスフォーマー層は、次々と交互に行われます。高次元のバイト配列は、低次元の注意のボトルネックを通って連続的に投影され、その後トランスフォーマーで処理されます。重みは反復する層の間で共有されているので、我々のモデルはRNNとして解釈することができます。また、attention層ではマスクを使用していないことにも注目してください。
Self-attentionの複雑性の改善
クエリ(Q)-キー(K)-値(V)のself-attention-softmax[(QKT)V]の複雑さはO(M2)であり、Mはシーケンス長である。このため、50176ピクセルの画像に対して、より大きなシーケンス長を処理することは現実的ではありません。そこでこの問題を解決するために、cross attentionを利用します。クエリ(Q)は、バイト入力配列(MxC)の代わりに、潜在的な配列(NxD)から得られます。ここで、Nは通常Mよりはるかに小さいハイパーパラメータです。これにより複雑さが(MN)に減少し、Mをはるかに大きな値にスケーリングすることができます。
またcross-attentionモジュールの出力は、Qネットワークの入力にのみ依存することに注意してください。このcross-attention層がボトルネックとなり、潜在的な変換器の複雑さをわずかO(N2)に抑えます。これにより、潜在トランスフォーマーをより深くすることができ、QKVアテンションの近似値を使用せずに、視覚トランスフォーマーではアクセスできない深さのネットワークを学習することができます。潜在トランスフォーマーは GPT-2 モデルであり,N<=1024 を用いて潜在配列は学習された位置エンコーディングを用います。
Iterative Attention
ボトルネックは、複雑さを軽減する一方で、入力信号からの情報の流れを制限します。モデルが必要な詳細を見逃さず、冗長な信号に悩まされることがないように、Perceiverは複数のバイトアテンション層を使用しています。このバイトアテンション層は、各cross-attention層の前に入力シーケンスから情報を反復的に抽出し、必要に応じて潜在配列に保持します。モデルの効率性をさらに高めるために、cross-attention層および/または潜在的なトランスフォーマーモジュールのパラメータは、反復の間で共有されます。ImageNetの実験では、パラメータの共有により,パラメータ数を10倍に減らすことができます。
Positional Encodings
self-attentionの操作は順列不変であるため、PerceiverモデルはCNNのように入力データの空間的関係を利用する能力がありません。そこで、パラメータ化されたフーリエ特徴の位置エンコーディングを入力シーケンスに利用します。このエンコーディングは、[sin(fk.pi.xd), cos(fk.pi.xd)]という値を取ることができます。ここで、周波数fkは、1からµ/2の間で対数線形に配置された周波数バンクのk番目のバンドです。xdは、d番目の次元に沿った入力位置の値です(例えば、画像の場合はd=2、ビデオの場合はd=3)。位置エンベッディングを画像特徴量に加える代わりに、それらを連結することで性能が向上することがわかった。これは、NLPモデルの入力特徴量の次元が今回使用したモダリティ(画像・動画・音声)よりも大きいことに起因しています。
これらの特徴ベースの位置エンコーディングにより、モデルは位置依存性をどのように利用するかを学習することができます。これらは、入力の次元数が比較的小さく既知である限り、様々なドメインに容易に適応することができます。さらに、マルチモーダルな環境でも使用することができる。各モードは、その次元性に基づいて別々の位置エンコーディングを使用することができ、ドメインを区別するためにカテゴリー別の位置エンコーディングを使用することができます。
実験と評価
いくつかの実験を行い、PerceiverとResNet-50、ViT-B、Transformerのスタックなどのモデルを、視覚、音と音声、点群という3つの異なるドメインで比較します。
Images: ImageNet
まず、ImageNetの分類タスクでPerceiverをテストします。位置エンコードは、224x224の入力クロップの(x,y)位置を使って生成されます。位置の特徴を生成する前に、(x,y)座標はクロップの各次元ごとに[-1,1]の範囲に標準化されます。クロップの座標ではなく、画像の座標を用いると、オーバーフィッティングが発生することがわかりました。クロップは位置とアスペクト比の増大をもたらし、モデルがRGB値と位置特徴の間の関連付けを行うのを止めます。
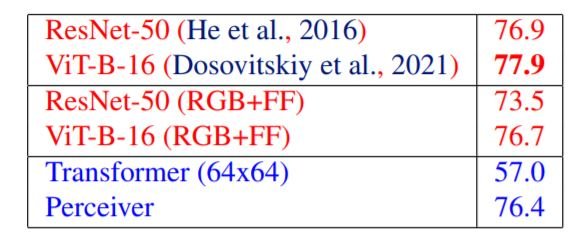
上の表に示すように、ImageNetにおいて、我々のモデルはSOTAモデルと同等の性能を示しています。ベースラインモデルを位置フーリエ特徴量(RGB+FF)で学習した場合、性能は若干悪くなりました。変換器は224x224の長いシーケンスを扱うことができないため、テストの前に画像を64x64にダウンサンプリングする必要がありました。
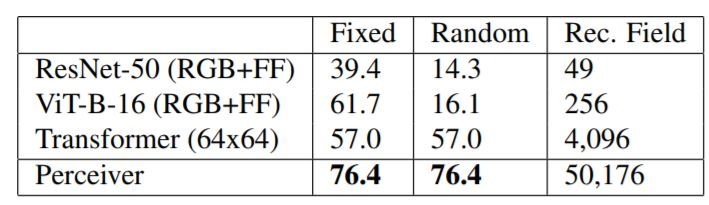
次に、ImageNetの順列バージョンを用いてモデルを評価します。まず、すべての画像に単一の順列を用い(Fixed)、次にすべてのピクセルをランダムに順列させます(Random)。変形器と知覚器はこの影響を受けませんが、グリッド構造を使用しているResNet-50とViT-Bは壊滅的な打撃を受けます。2次元のグリッド構造が与えられているにもかかわらず、なぜそれを使わないのかと思われるかもしれません。この実験は、CNNやViTを特定のモダリティやクロスモダリティで使用する際の課題を示しています。例:点群を2Dグリッドに変換するのは複雑だし、オーディオとビデオの組み合わせをどのようにしてグリッドとして表現するのか?
Sound and Audio: AudioSet
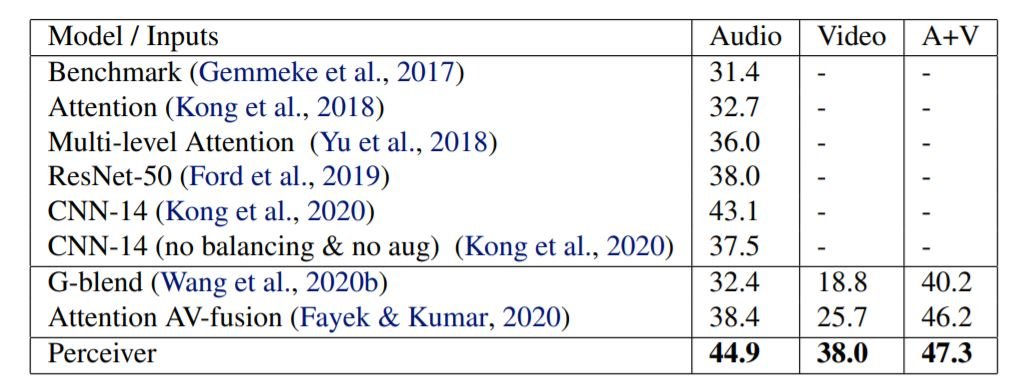
Perceiverは、AudioSetデータセットでもテストを行いました。このデータセットは、10秒の長さの1.7Mのト学習ビデオと527のクラスからなる大規模なデータセットです。上の図に示すように、Perceiverは、オーディオ、ビデオ、A+Vの分類タスクにおいて、他のSOTAモデルを圧倒しました。 オーディオは48 kHzでサンプリングされ、1.28sのビデオに61,400の入力があります。フーリエ特徴は、時間軸だけでなく、音声の振幅軸でも使用されています。
動画では、2x4x4形状のバウンディングボックスを使用して、32フレームのクリップを256x256ピクセルにダウンサンプリングし、合計65,536個の入力となります。ダウンサンプリングを行わなかった場合、入力シーケンスは32x256x256、つまり約200万個の入力となりますが、このモデルは低速ながらも機能しています。
オーディオ+ビデオ(A+V)の場合、これらのシーケンスを連結します。オーディオ入力の次元をビデオ入力の次元と同じにするために、モダリティ特有の学習済み埋め込みを追加で連結します
Point Clouds: ModelNet40
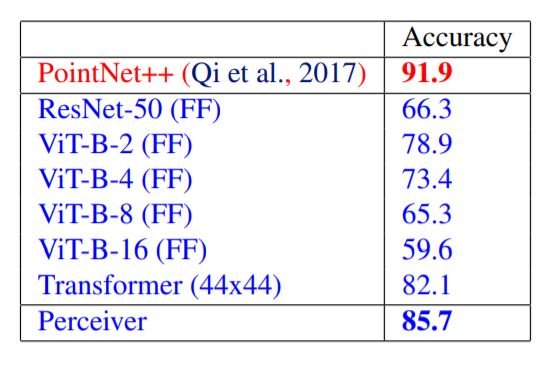
ModelNet40は、3次元の三角メッシュから得られた点群のデータセットで、3次元空間の2000点の座標が与えられると、モデルは40の人工的なカテゴリーから予測を行います。ここでは、各点群を2次元のグリッドにランダムに配置し、モデルに入力しています。Perceiverは、ViTやResNetを上回る性能を発揮しますが、ドメイン固有のPointNet++には勝てません。しかし、PointNet++では、高度なデータ補強と特徴エンジニアリングの手法が用いられていることに留意する必要があります。
まとめ
Perceiverアーキテクチャは、10万個以上のベクトルを持つ入力シーケンスを扱うことができます。これにより、同じPerceiverモデルを異なるモダリティ間で使用しても、わずかな再構成で済むようになりました。とはいえ、このモデルは、ドメイン固有の位置エンコーディング入力とデータ補強を使用しているため、任意の入力を柔軟に処理することはできません。このようなドメイン固有の前提条件を取り除くことができるかどうかは、今後の研究課題となります。




この記事に関するカテゴリー






