Transformer Hybrid Model For Visual Tasks: BoTNet
3 main points
✔️ A hybrid architecture that makes use of conv layers and self-attention layers.
✔️ Significant improvement in model performance compared to networks that just use conv layers.
✔️ Impressive results on object detection, instance segmentation, and image recognition tasks.
Bottleneck Transformers for Visual Recognition
written by Aravind Srinivas, Tsung-Yi Lin, Niki Parmar, Jonathon Shlens, Pieter Abbeel, Ashish Vaswani
(Submitted on 27 Jan 2021)
Comments: Technical Report, 20 pages, 13 figures, 19 tables
Subjects: Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI); Machine Learning (cs.LG)code:

Introduction
Today computer vision tasks like Image recognition, instance segmentation, and object detection are done using Deep Convolutional Neural Networks(Deep CNNs). These networks are usually composed of 3x3 sized conv layers that are really good at capturing local information. When stacked together, a deep network of many convnets is able to capture global information. Transformers or Multi-Head Self-Attention (MHSA) networks are really good at capturing such global information which is necessary in NLP tasks. Therefore it is intuitive to think that using MHSA to capture global information along with CNNs to capture local information could yield performance improvements.
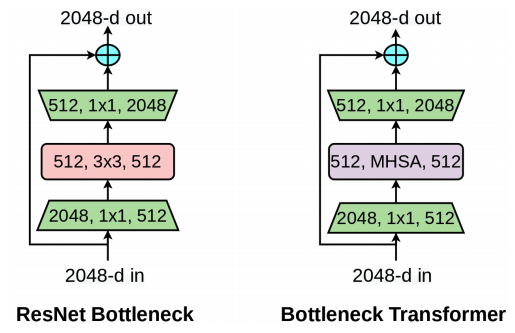 ResNet Bottleneck Block and Bottleneck Transformer (BoT) block.
ResNet Bottleneck Block and Bottleneck Transformer (BoT) block.
In this paper, we introduce a hybrid network made by substituting conv layers within ResNet architectures by MHSA layers. In doing so, we improve the global information capturing capabilities of the networks, and at the same time take advantage of the downsampling and local-feature capturing abilities of conv layers.
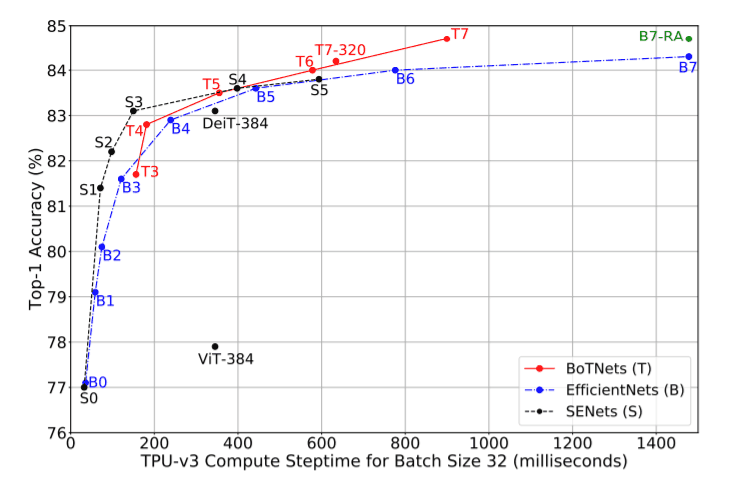
The Bottleneck Transformer Network (BoTNet)

The BotNet architecture is shown in the above table along with the ResNet architecture. A ResNet architecture is formed by 4 stages [c2,c3,c4,c5] each consisting of several residual blocks Ex. [3,4,6,3] in case of ResNet-50. The only difference in BotNet is that the 3x3 conv layers in the final stack are each replaced by an MHSA layer.
The computational complexity of a self-attention block is O(d2n) where n is the number of entities, and d is the dimension of those entities. For an image of resolution 1024x1024, this demands a lot of computation. For this reason, MHSA is only incorporated into the network in the final part where the feature map resolution is smaller. The first block in ResNet uses stride 2 convolutions to downsample the image. To downsample in the BoT block, we use a stride 2 average pooling layer in the first layer of the fifth stack.

In the case of smaller image sizes like ImageNet, the feature map becomes quite small in the fifth stack when it reaches the MHSA (14x14 or 7x7 for smaller 224x224 images as compared to 64x64 or 32x32 for larger 1024x1024 images). So, we introduce BotNet-S1 architecture, which leaves out the 2 strides in the first block of c5 block group.
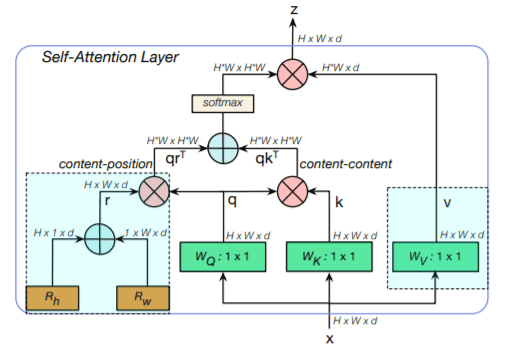 MHSA used in BoTNet
MHSA used in BoTNet
The above diagram shows the MHSA used in BoTNet called all2all attention. 1x1 represents 1x1 convolutions, + represents element-wise sum and X represents matrix multiplication. Each BoT block consists of 4 of the above attention heads. Two relative-position encodings: one for height and one for weight are used to add spatial information to the 2D feature maps. These encodings are added together and multiplied to a copy of the query matrix. The self-attention operation is given by qrT+qkT. Here, k,q, and r represent the key, query, and position encodings respectively. Mathematically, the block operates as follows:
q = conv1x1Wq (X), v= conv1x1Wv (X) , k=conv1x1Wk (X)
Y = Softmax( qrT+qkT )v
Evaluation of BoTNet
The BoTNet architecture is fairly simple to implement and is not the primary contribution of the paper. Instead, the paper aims to vindicate that self-attention networks are effective in computer vision tasks. To do that, we conduct experiments on vision tasks (image recognition, instance segmentation, and object detection) using (ResNet, EfficientNets, SENets), which are convlayers-only networks vs BoTNet, which is a slightly modified ResNet with conv+self-attention layers. The incorporation of the self-attention block provides significant performance improvement on a variety of tasks as shown below.
BoTNet vs ResNet
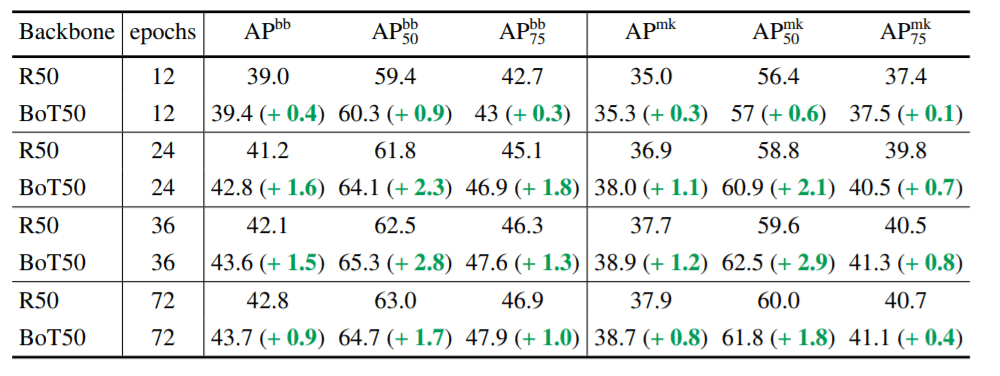 BoTNet vs ResNet on COCO
BoTNet vs ResNet on COCO

BoTNet vs ResNet on ImageNet
The top table shows the results of a ResNet-50 backbone vs BotNet50 backbone mask r-CNN architecture trained on the COCO dataset and the lower table shows image classification performances on ImageNet. The self-attention based BoTNet outperforms the ResNet architecture in all cases. In addition, it was also found that BoTNet benefits more from augmentations like multi-scale jittering than ResNet.
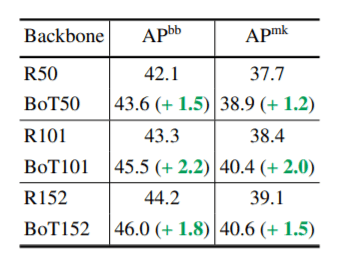
The above diagram shows that MHSA improves the performance even for larger ResNet architectures all of which were trained on 1024x1024 resolution images with multi-scale jitter for 36 epochs.
BoTNet vs EfficientNets vs SENets
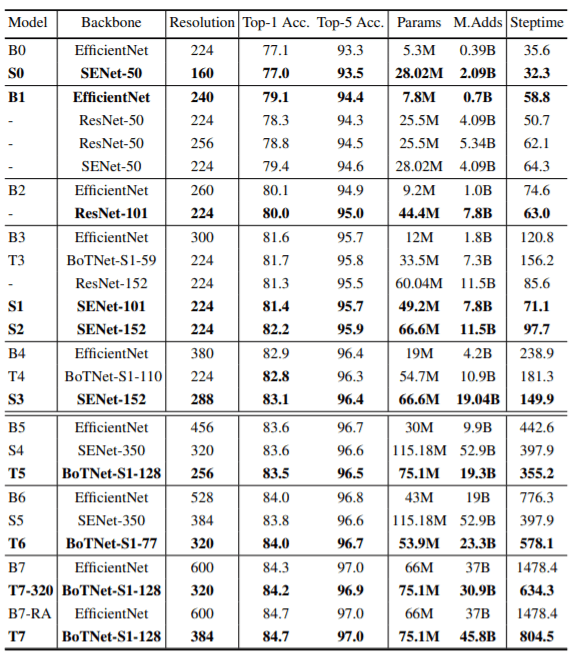
The above graph shows how BoTNets compare to EfficeintNets, SENets, ViT, and other self-attention-based networks. We can see that BoTNets are much more efficient than EfficientNets for higher-accuracy models. Although EfficientNets have fewer parameters, they seem to not be able to leverage the power of the latest TPUs and are slower than ResNets and SENets in almost all cases. Although SENets perform very well for models in the lower-accuracy region, they are behind in the higher-accuracy-models regions.
How much self-attention is needed?

The above diagram shows the results of the ablation studies conducted by replacing different numbers of 3x3 conv layers with MHSA. [x1,x2,x3] represents the three conv layers with 0 meaning not replaced and 1 meaning replaced. Both the R101 and R50 are beaten by proper configurations of BoT50 and BoT101. The results suggest that increasing MHSA blocks does not necessarily increase performance. However, we can say that some form of self-attention replacement is better than just stacking conv layers.
Conclusion
The experiments in this paper provide evidence that combining self-attention with CNNs can push forward works in computer vision. This seems like a better approach than replacing convolutional layers completely. Future works might try substituting self-attention into other models like DETR or even scale to larger datasets such as JFC, YFCC, and Instagram. It would be interesting to see how such hybrid networks can be applied to develop state-of-the-art smashing models in future works.



Categories related to this article



![[MusicLM] Text-to-Mu](https://aisholar.s3.ap-northeast-1.amazonaws.com/media/October2023/musiclm-520x300.png)


