And There It Is Again! Another (M)DETR! An Innovative Paradigm For Multimodal Inference Models.
3 main points
✔️ Propose an End-to-End text-controlled object detection model
✔️ Achieve End-to-End detection in multimodal tasks
✔️ Achieve performance even in downstream tasks
MDETR -- Modulated Detection for End-to-End Multi-Modal Understanding
written by Aishwarya Kamath, Mannat Singh, Yann LeCun, Ishan Misra, Gabriel Synnaeve, Nicolas Carion
(Submitted on 26 Apr 2021)
Comments: Accepted by ICCV2021 oral
Subjects: Computer Vision and Pattern Recognition (cs.CV); Computation and Language (cs.CL); Machine Learning (cs.LG)
code:
The images used in this article are either from the paper or created based on it.
first of all
In many current image and text fusion multimodal inference models, there is a process of extracting regions of interest from images using a pre-trained object detector. This may sound obvious, but if you think about it, it means that the model modal inference depends on the pre-trained object detectors. For example, if you enter the query "dog" and you want to detect only the dog in the image, but the pre-trained object detector has pre-trained a car, it will not be able to detect the dog no matter how much information about the dog you enter in the text query! This is a major factor currently hindering the performance of multimodal inference models.
So the paper I am going to introduce is an end-to-end modulation detector MDETR that detects objects in an image conditional on textual queries such as captions and questions. (This paper is also co-authored by Prof. Yann Lucan).
Based on the transformer structure, we fuse information from both modalities early in the model and perform joint text and image inference to detect objects in the image. From here, it gets even more awesome and eventually achieves SOTA performance on both the detection task and multiple downstream tasks. Before we move on to the explanation, let's take a look at the amazing performance of MDETR! MDETR can detect objects in free-form text and generalize them to unknown combinations of categories and attributes! So in the case of "A pink elephant", MDETR correctly detects a pink elephant, even though we didn't see a pink or blue elephant during training!

DETR
MDETR is based on the DETR model, which is an end-to-end object detection model consisting of a Backbone and a Transformer Encoder-Decoder (the structure of DETR is shown in the figure below). If you are interested in DETR, please refer to AI-SCHOLAR. → "It's finally here! A revolutionary paradigm for object detection".
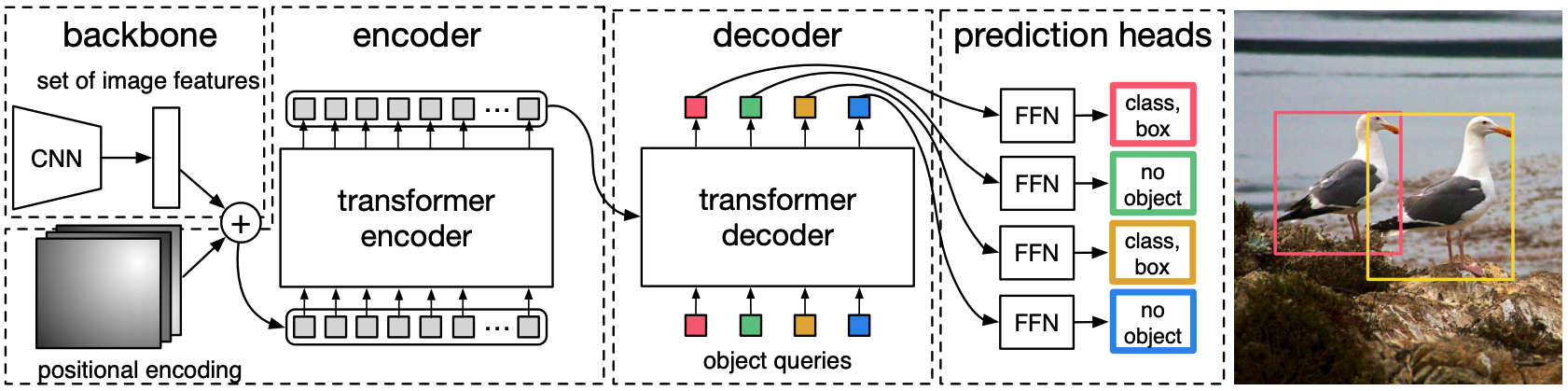
DETR first runs the image through a CNN backbone to extract visual features. The visual features are then flattened and position-encoded, and input to the Transformer Encoder. The object queries can be thought of as the slots required for the model to detect an object.
After these object queries are fed to the decoder, a cross-attention layer is used to informally interact with the encoded image features and predict the output embedding for each query. Finally, the output embeddings for each query are used to predict the box coordinates and category labels via an FFN with shared parameters.
However, since each query uses the prediction of a single box, the predefined number of queries is an upper bound on the number of objects in the image. Since the number of objects in an image is likely to be smaller than the number of queries, the authors use an additional class label corresponding to "no object".
MDETR
The structure of MDETR is shown in the figure below.
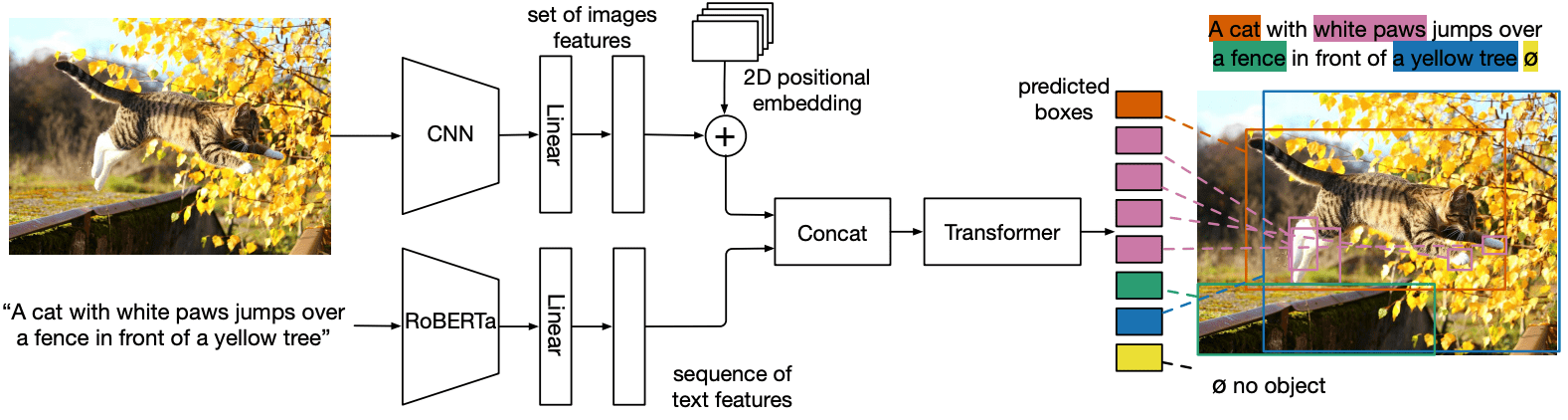
MDETR extracts visual features by passing them through a CNN backbone and then flattening the features. MDETR adds spatial information to the flattened vectors by adding 2D positional embeddings. Up to this point, it is almost the same as DETR, and the difference starts here. Next, we use a pre-trained transformed language model (RoBERTa) to generate a sequence of hidden vectors of the same size as the input for the language modal. We then apply a modality-dependent linear projection to both image and text features, projecting them into a common embedding space. These feature vectors are then concatenated in the sequence dimension to produce a single sequence of image and text features.
This set of features is first input to the cross encoder for processing. Then, as in DETR, an object query is set up to predict the target frame.
So it's like saying that the text modal part of the above diagram was merged into DETR.
Training
For training, in addition to the DETR loss function, the authors propose two additional losses for image and text alignment.
- Soft-token prediction loss, a one-parameter-free alignment loss
- Text-query contrast alignment loss, a parameterized loss function used to approximate the similarity of aligned queries and tokens
Soft token prediction
Unlike traditional object detection, which needs to respond only to objects that appear in the input sentence, we first set the maximum number of tokens to 256 and train the model to predict the distribution that corresponds to the position of all tokens for each prediction box matching GT. The figure below shows an example where the cat prediction box has been trained to predict the distribution of the first two words. As the name "soft tokens" implies, this token relationship is based on the idea that hard token prediction would not fit because text and images are many-to-many, and multiple words in the text may correspond to the same object in the image, and vice versa. I think it was devised based on the idea that hard token prediction would not fit.
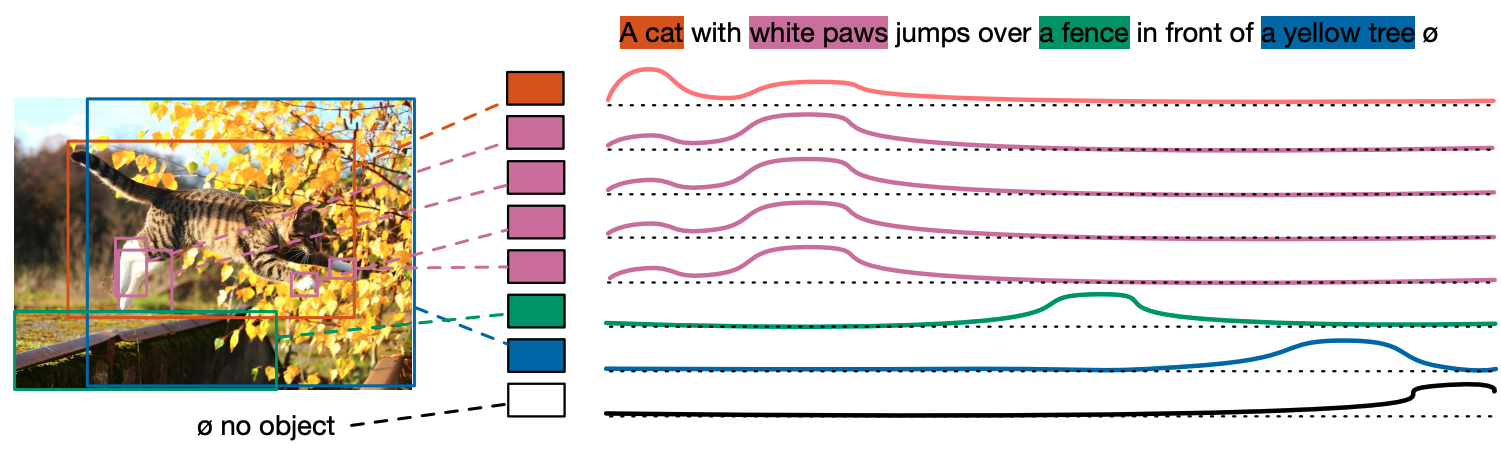
Paired Alignment
Soft-token prediction loss is used to align objects and text, and contrast alignment loss is used to enhance the alignment of visual and textual embedded feature representations, so that aligned visual and verbal feature representations are relatively close in feature space. The loss function does not act on the position, but directly on the feature level, improving the similarity between the corresponding samples. This loss function is based on InfoNCE and is represented by the following equation
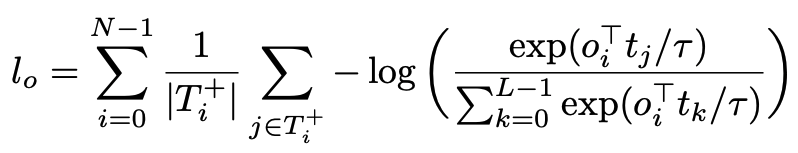
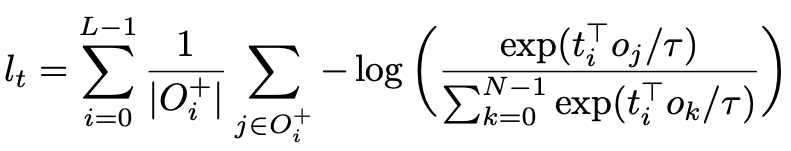
As you can see from the description so far, the basic idea is how to extend DETR to multimodal objects, since the end-to-end object detection capability of DETR can overcome the limitation of multimodality. It is quite simple and intuitive, with an architecture for this and an additional loss function for multimodal specific relationships. So, make sure you keep DETR in mind ("It's finally here! A revolutionary paradigm for object detection"). Even in the original paper, the paper is quite simple and easy to understand until the experiments. And there are quite a few experimental items, which is why it was accepted for ICCV2021 oral.
experiment
We are conducting experiments using synthetic data from the CLEVR dataset and real-world images.
CLEVR
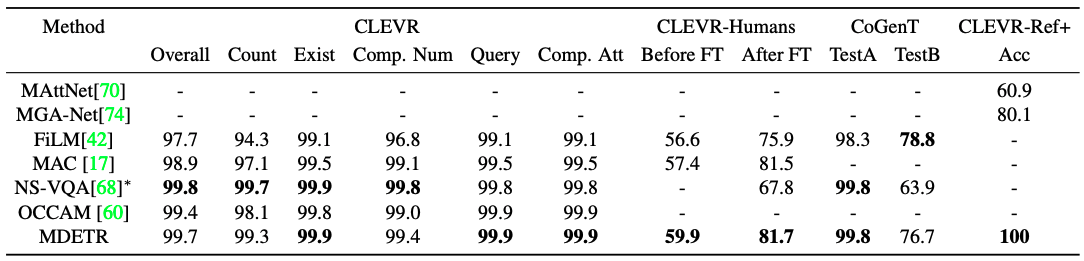
CLEVR will be a synthetic data set designed to evaluate multimodal models in a controlled environment. The main challenge is to understand questions involving up to 20 levels of inference and to match the key phrases in them to the correct objects in the image Unlike some successful approaches to CLEVR, MDETR does not incorporate any special inductive bias to deal with such complex inference tasks It is characterized by the following. Despite its relatively simple formulation, we show that MDETR is competitive with state-of-the-art models in the question-answering task. The results are presented in Table.
It shows a performance close to that of NS-VQA. It clearly outperforms the performance of methods that do not use external signals. Additionally, CLEVR-Humans is a dataset of human-generated questions on CLEVR images. This dataset tests the robustness of the model to new vocabulary, etc. CoGenT is a test of constructive generalization. The evaluation protocol consists of training on set A, where spheres can be any color, but cubes can be gray, blue, brown, or yellow, and cylinders can be red, green, purple, or cyan. Next, we perform a zero-shot evaluation on partition B, where the color and shape combinations of the cubes and cylinders are reversed. As with the other models, we see a large generalization gap. This suggests that the model has learned a strong spurious bias between shape and color.
Finally, we evaluated our model on CLEVR-REF+, a CLEVR image-based reference representation understanding dataset. We learn an additional binary head for each object query to predict whether the query corresponds to the referenced object. We evaluate accuracy on a subset of unique object representations and measure it by whether the top-ranked box has an IoU of at least 0.5. MDETR correctly ranks the valid boxes first in each example of the validation set, with an accuracy of 100%, significantly outperforming prior work This is a significant improvement over previous studies.
Real-World Images

The sentence "The person in the gray shirt with a watch on the wrist. the other person wearing a blue sweater. the third person in a gray coat and scarf" can accurately detect three persons with different attributes. The third person is in a gray coat and scarf. The accuracy is quite amazing.
downstream task
We have also evaluated MDETR on four downstream tasks (Phrase Grounding, Understanding Referential Expressions, Segmentation, and Visual Question Answering). Since we have conducted quite a few experiments, we will only list the results, so be sure to check the original publication if you are interested.
phrase grounding
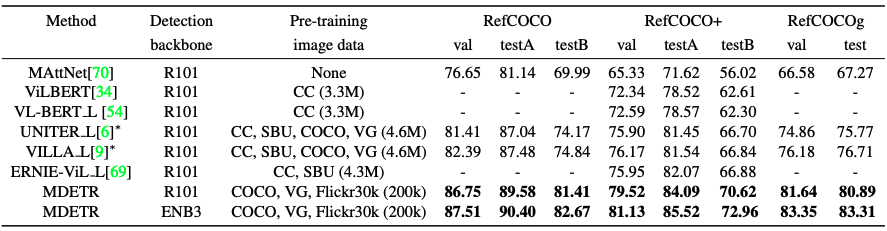
Given one or more phrases that may be interrelated, the task is to provide a set of bounding boxes for each phrase. For this task, the Flickr30k entities dataset is used to perform the train/val/test partitioning and the performance is evaluated in terms of Recall@k. For each sentence in the test set, we predict 100 bounding boxes and use soft token alignment prediction to rank the boxes according to the score given to the position of the token corresponding to the phrase. We compare our method with existing methods using two different approaches: a detection model conditioned on the text and a pre-training model for visual language using a transducer. It can be seen that the accuracy of our method is overwhelming compared to other methods.
Understanding Referential Expressions
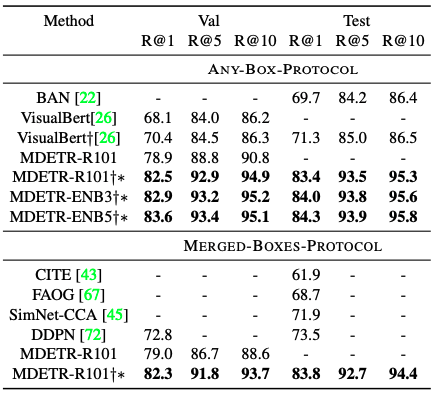
The task is to localize an object by returning the bounding boxes around the referenced object given an image and a textual representation. Basically, the approach is to rank a set of pre-extracted bounding boxes associated with an image obtained using a conventionally pre-trained object detector.
However, in this paper, we have solved a more difficult problem. What we mean is that we train the model to directly predict the bounding box when given a reference representation and associated images. For this task, we use three established datasets called RefCOCO, RefCOCO+, and RefCOCOg.
There is a slight change to MDETR. For example, given the caption "The woman wearing a blue dress standing next to the rose bush.", MDETR is trained to predict the box for all referenced objects. However, in the case of a referring expression, it needs to be trained to return only one bounding box that refers to the woman referred to in the entire expression, thus returning an excessive number of bounding boxes. Therefore, we fine-tuned the model by training it five times on a task-specific dataset. This also results in an overwhelming improvement inaccuracy.
segmentation
Similar to DETR, we show that it can be extended to perform segmentation by training on the PhraseCut dataset segmentation task. Again, we can improve the accuracy considerably.
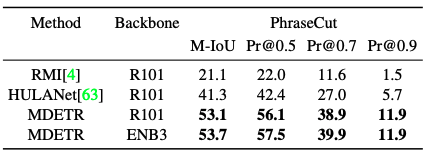
visual question and answer session
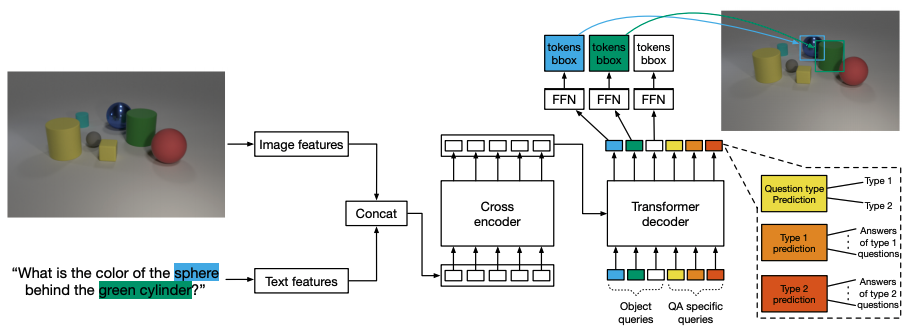
By fine-tuning the pre-trained model on the GQA dataset, we evaluate the hypothesis that modulation detection is a useful component for multimodal inference. The architecture of the model is shown in the figure below. Apart from the 100 queries used for detection, we use an additional object query specific to the type of question and one query used to predict the type of question.
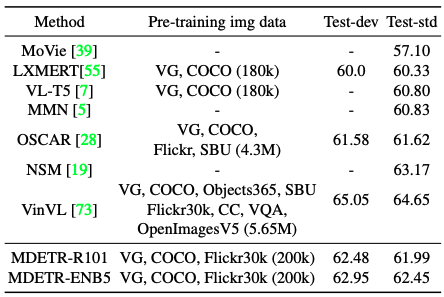
When MDETR was used on the Resnet-101 backbone, it not only outperformed LXMERT and VL-T5, which use a similar amount of data, but also OSCAR, which uses more data in its pre-training.
Few-shot transfer for long-tailed detection
Inspired by CLIP on zero-shot transfer for image classification, we experiment to construct useful detectors on a given set of labels from a pre-trained MDETR model. unlike CLIP, we do not guarantee that the pre-trained dataset contains representations of all target classes. Unlike CLIP, we do not guarantee that the pre-training dataset contains representations of all target classes. This causes the model to always predict a box for a given text. We, therefore, cannot evaluate in a true zero-shot transfer setting, and instead use a few-shot setting where we train the model on a subset of the available labeled data We experiment with the LVIS dataset, which is a detection dataset with a large vocabulary of 1.2k categories and is a challenging task because it is long-tailed and has very few training samples.
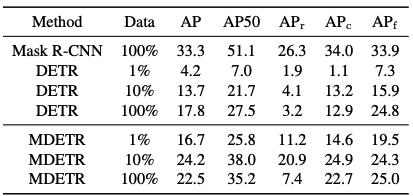
We compare it to two baselines: the first is the Mask-RCN trained only on the full LVIS training set. The second is the DETR model pre-trained on MSCO and fine-tuned on various subsets of the LVIS training set.
The results are shown in the table: even with as few as one sample per class, MDETR outperformed fine-tuned DETR even in the fewest categories, taking advantage of text pretraining. However, it is curious to note that when fine-tuning the entire training set, the small object performance drops significantly from 20.9 APs at 10% data to 7.5 APs at 100%.
![]() Summary
Summary
MDETR, an end-to-end detector of multimodal inference models, was proposed, which showed high performance in multimodal comprehension tasks with various datasets and other downstream tasks such as number shot detection and visual question answering. performance was demonstrated.
Like Aplhafold2, this paper is based on research on DETR, research around multimodal, and self-supervised learning. It's a polished paper, research included!



Categories related to this article


![[MusicLM] Text-to-Mu](https://aisholar.s3.ap-northeast-1.amazonaws.com/media/October2023/musiclm-520x300.png)


