Achieving SoTA In Path Prediction With Transformer! MmTransformer For Multimodal And Diverse Path Prediction.
3 main points
✔️ Predicting vehicle paths with Transformer-based models
✔️ Enables multimodal and diverse prediction
✔️ Achieve SoTA in the path prediction task
Multimodal Motion Prediction with Stacked Transformers
Written by Yicheng Liu, JinghuaiZhang, Liangji Fang, Qinhong Jiang, Bolei Zhou
( Submitted on 22 Mar 2021 (v1), last revised 24 Mar 2021 (this version, v2))
Comments: Accepted to CVPR2021.
Subjects: Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI)
code:.
first of all
We assume that a safe society in the automated driving society will come by predicting the future paths of surrounding vehicles including ourselves. Conventional methods generate multiple candidate predictions by varying features and probabilistically modeling the uncertainty of the route using latent variables. However, the latent features concentrate on the modes (types of cars) that frequently appear in the data, and the method relies on prior knowledge to generate and select candidate proposals. In other words, it was necessary to set up a prior distribution and to design a loss function that works well. Another approach, the suggestion-based approach, predicts the path by suggesting possible paths in advance and then reducing or identifying the correct path. However, since it is not a heuristic approach for unknown paths, the designer's prior knowledge is required, and multimodal prediction cannot be guaranteed with only one correct answer data.
Therefore, in this paper, we propose a MultiModal Transformer (mmTransformer) that uses transformer to perform end-to-end behavior prediction in multiple modes. To achieve multimodality at the feature level of each of the independent path proposals, we randomly initialize the proposals and propose a stacked transformer-based model (past paths, road information, social interactions) with multi-channel context information as input The proposed model is based on a stacked transformer. A region-based learning strategy is used to inherit the multimodality generated by the proposal (reducing complexity in behavior prediction), and experiments are conducted on the Argoverse dataset, a behavior prediction dataset, to achieve SoTA. We have succeeded in diversifying the proposed paths and improving the accuracy.
Proposed method: mmTransformer
The mmTransformer has two features to improve unimodality.
- Proposed a route suggestion mechanism for behavior prediction
- A region-based training strategy (RTS) to ensure multimodality
The path proposal mechanism asynchronously collects multi-channel context information from the mmTransformer encoder and passes it to a query in the decoder as a proposed path. This proposal has independent and therefore customized features, which gives the route diversity and multimodality.
In RTS, on the other hand, the surrounding space is divided into several regions and the proposed regions are grouped as different sets, and only the set of proposed paths is applied to the regions that may have correct data. In this way, each proposal can learn only a specific mode without considering the latent features from the proposals of other modes.
The overall diagram is shown above. mmTransformer uses a stacked transformer as a backbone and learns the context information from the proposed path. The decoder (Proposed Feature Decoder) decodes the features of the proposed path and outputs the corresponding probabilities using a trajectory generator and a trajectory selector. The structure of the trajectory generator and the trajectory selector used here is the same as that of the feed-forward network used in the transformer.
Stacked Transformer
The transformer is known for its high performance on continuous data, and in order to adapt it to the task of route prediction, it needed to deal with contextual information. An intuitive solution would have been to concatenate all types of inputs, such as past routes and lane information, and encode the contiguous contests into the transformer. However, since the transformer needs to be given a fixed size input, this method would require enormous computational power. Furthermore, since different types of information are concatenated and input to the attention layer, the nature of the latent features becomes important.
We solve this problem by treating the QUERY in the decoder of the TRANSFORMER as pathfinding. The strength of this approach is that parallel path proposals can integrate information from encoders independently, and retain the features of each path as disentangle modality information. The structure of the stack is such that multiple inputs can be provided to multiple feature extractors, and different context information can be integrated hierarchically. In particular, here, it consists of three transformer units: motion extractor, map aggregator, and social constructor.
The motion extractor encodes the past routes of the target car, the map aggregator learns geographical and semantic information such as the shape of the road from the map and represents the features of the input proposed route, and the social constructor represents the features of all cars to learn the interaction. and represents the features of all cars in order to learn The motion extractor, the map aggregator, and the social constructor are organized in the order of motion extractor, map aggregator, and social constructor by ablation studies and logical decisions.
decoder
The feature decoder of the proposed path is formed from a path generator and a path selector, and the predictive path is generated using a three-layer multilayer perceptron for K target proposals.
Region-based Training Strategy
In order to guarantee the multimodality of the model, this research proposes RTS to prevent the proposed path from falling into the mode average problem. mode average problem is a problem that outputs results ignoring each mode, which means that pedestrians walk on the road and cars drive on the sidewalk as well. pedestrians walking on the road or cars driving on the sidewalk. A reasonable solution to this problem is to calculate regression loss and classification loss using only the minimum final displacement error and the proposed path. We consider this as a baseline.
In this baseline, the problem exists that the modality collapses as the number of proposed paths to ensure diversity increases. Therefore, we propose a region-based learning strategy (RTS) that groups the proposed paths as several spatial clusters. As shown in the figure, the scene is rotated by a certain angle in each scenario to divide the region, and the center of the axis is the position of the car in the previous path. The center of the axis is the position of the car of the previous route. After dividing the scene without duplication, K routes are proposed and assigned to each region, resulting in N proposals for each region. Under training, we use regression loss and classification loss, and unlike the baseline, we calculate the loss for all proposed paths in each region. This outputs results that ensure the multimodality of the predicted paths.
objective function
The regression loss for partitioning into correct regions described above uses Huber loss in each step, and the classification loss uses cross-entropy loss, which speeds up the convergence of mmTransformer + RTS learning. the convergence of mmTransformer + RTS. The Confidence score of each prediction path is calculated using the maximum value of the entropy model, and the distance between the correct answer and the prediction path is calculated using the L2 distance, and the Kullback-Leibler Divergence is used as the loss function. By using Kullback-Leibler Divergence as a loss function, the closer this distance is, the better the score is designed to be.
During inference, overlapping (near overlapping) paths are removed using the non-maximum suppression algorithm (an algorithm often used to remove proposal regions in object detection).
Experimental setup and results
To investigate the performance of mmTransformer, we used the Argoverse behavior prediction benchmark with 340,000 images containing 5-second paths and context information as the dataset. The goal is to predict the next 3 seconds of behavior using the past 2 seconds of path and context as input. In each scenario, the centerline-based continuous lines in the HD map are represented as information in the local map, as shown in the figure. In addition, to model car-to-car interaction, past paths and locations of neighboring cars and own cars are represented.
The evaluation method of the model is Average Displacement Error (ADE) and Final Displacement Error (FDE). To evaluate the multimodality, the miss rate (MR) of the top K (K=6) routes is compared with the minimum value of ADE and FDE The results are compared.


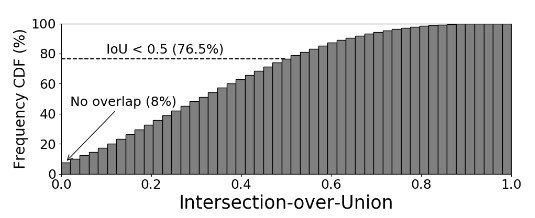
The experiments are conducted on the test set of the Argoverse dataset. First, we compare the proposed method, mmTransformer, with mmTransformer + RTS. table 2 shows that mmTransformer has the best accuracy for minADE and minFDE, and the MR is lower when RTS is added (i.e., it predicts correctly). The number of proposed routes and the accuracy of each route is shown below. Next, we compared the number of proposed paths and each proposed module in the ablation study. 6 proposed mmTransformer without RTS has higher accuracy in both minADE and minFDE than 36 proposed mmTransformer without RTS. In other words, if we fix the output to a small number of proposals, we will discard the diversity choices in advance, and the MR will decrease although the accuracy will increase. Furthermore, we found that the accuracy of minADE and minFDE decreases when the number of selected proposals in the correct answer region becomes small. In this study, we believe that accuracy and diversity are trade-offs.

Next, we evaluate the partitioning of the space in RTS, where the surrounding region was divided into several spaces. We have experimented with K-means and manual segmentation as a segmentation method. In the manual segmentation, the region is segmented as shown in Figure 3. The training samples are divided evenly according to the balance of the data. Compared with K-means, manual segmentation can correctly segment ambiguous samples, and the learning accuracy is higher because there are fewer false segments. In this study, we only split the samples evenly, and we do not yet know the important splitting method for learning.

In the figure, we visualize the RTS (36 partitions). According to the MR matrix in the upper right corner, the cell $(i, j)$ represents the MR of the proposal that predicts the cases included in the region $j$ in the region $i$. We can see that each proposal generates a path that belongs to a pre-assigned region. In other words, it shows that mmTransformer is able to learn different modalities by region-based learning.
summary
SoTA is achieved by using a Transformer in an automotive route prediction task. However, a single transformer cannot handle different levels of input and is insufficient for route prediction using context information. However, the transformer alone cannot handle different levels of input and is insufficient for path prediction using contextual information. In this research, we use different transformers depending on the information to handle multiple channels of input and divide the proposed path into separate regions to achieve path prediction including multimodality, which has been a problem in the past. Since the future path is unknown, diversity is required, but it is a trade-off with prediction accuracy, and further improvement is required along with improvement of prediction time.



Categories related to this article



![[MusicLM] Text-to-Mu](https://aisholar.s3.ap-northeast-1.amazonaws.com/media/October2023/musiclm-520x300.png)


