Modal-independent Transformer: Perceiver Model
3 main points
✔️ A cross-modal transformer-based model that performs well in several tasks.
✔️ Ability to process sequences longer than 100,000 inputs.
✔️ Comparable or better performance than SOTA models in ImageNet, AudioSet, and ModelNet-40.
Perceiver: General Perception with Iterative Attention
Written by Andrew Jaegle, FelixGimeno, Andrew Brock,Andrew Zisserman,Oriol Vinyals, JoaoCarreira
(Submitted on 4 Mar 2021)
Comments: Published on arxiv.
Subjects: Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI); Machine Learning (cs.LG); Sound (cs.SD); Audio and Speech Processing (ess.AS) Processing (eess.AS)
code:.
first of all
Humans and other animals process high-dimensional multi-modal information like vision, speech, touch in order to perceive their surroundings. On the contrary, artificial neural networks are only good at performing specific tasks for which they have been trained. CNNs have revolutionized computer vision due to their strong inductive biases to images. However, given the increasing sizes of multi-modal datasets, it is wise to question whether such biases limit the capabilities of the models. Are we not better off letting the data speak for itself?
In this paper, we introduce the Perceiver model that deals with different modalities with arbitrary configurations using the same transformer-based architecture. We chose transformers because they have very few inductive biases and are highly scalable. Current vision transformers use pixel grid structure or aggressive subsampling techniques to reduce the computation cost of the self-attention network. We introduce a new mechanism that makes it possible to directly and flexibly deal with 50000 pixels.
Perceiver's performance is comparable to strong vision models like ResNet-50 on ImageNet, state-of-the-art performance on the AudioSet sound event classification benchmark, and strong performance on ModelNet-40 point cloud classification.
The Perceiver
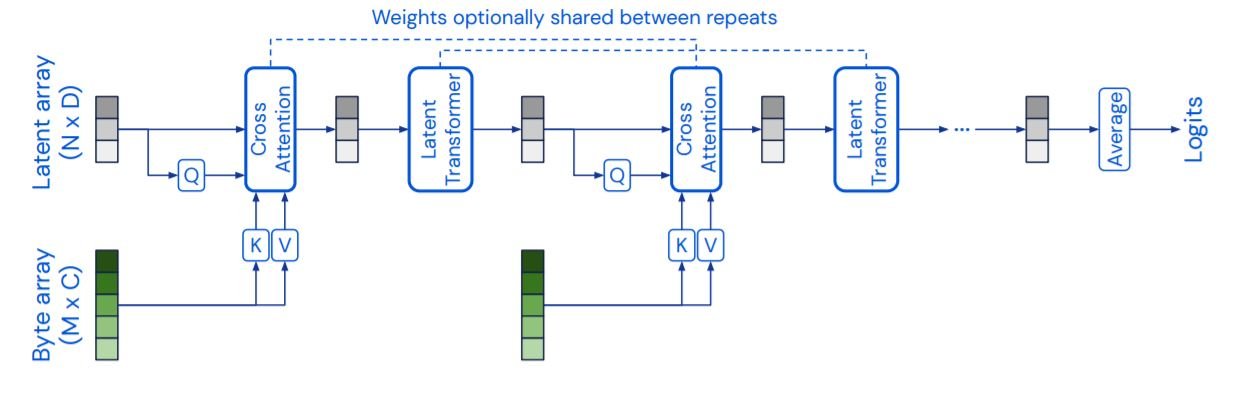
The Perceiver consists of two main components: the cross attention and the latent transformer. The cross attention transformer maps a latent array and a byte array to a latent array. The latent transformer is a transformer tower that maps a latent array to a latent array. The size of the byte array depends on the input type and is about 50176 for a 224x224 image. The latent array is much smaller with a size of about 1024 for ImageNet. The cross attention and latent transformer layers are alternated one after another. The higher-dimensional byte array is continuously projected through a lower-dimensional attentional bottleneck, before processing with a transformer. Since the weights are shared among recurring layers, our model can be interpreted as an RNN. Also, it is to be noted that no masks are used in the attention layers.
Improving the complexity of Self-attention
The complexity of the query(Q)-key(K)-value(V) self-attention – softmax[(QKT)V] is O(M2), where M is the sequence length. This makes it impractical to process larger sequence lengths for an image with 50176 pixels. Therefore, we make use of cross-attention to tackle this problem. The query(Q) is derived from a latent array (NxD), instead of the byte input array(MxC). Here, N is a hyperparameter that is usually much smaller than M. This reduces the complexity to (MN), allowing us to scale M too much larger values.
Also, note that the output of the cross-attention module depends only on the input to the Q network. This cross-attention layer induces a bottleneck which reduces the complexity for the latent transformer to just O(N2). This enables us to make the latent transformer much deeper and train networks with depths inaccessible to vision transformers without using an approximation of QKV attention. The latent transformer is a GPT-2 model that uses N<=1024 and the latent arrays use learned positional encodings.
Iterative Attention
The bottleneck reduces the complexity but also restricts information flow from the input signals. In order to ensure that the model does not miss necessary details and is not stuck with redundant signals, the Perceiver uses multiple byte-attend layers that iteratively extract information from the input sequence before each cross-attention layer, and hold it in the latent array as required. To further improve model efficiency, the parameters of the cross-attention layer and/or latent transformer module are shared across the iterations. In the ImageNet experiments, parameter-sharing reduces the number of parameters by 10 times.
Positional Encodings
Since the self-attention operation is permutation invariant, the Perceiver model lacks the ability to exploit spatial relationships in input data like CNNs can. Therefore, we make use of parameterized Fourier feature positional encodings in the input sequence. The encodings can take values [sin(fk.pi.xd), cos(fk.pi.xd)], where the frequencies fk is the k-th band of a bank of frequencies spaced log-linearly between 1 and µ/2. xd is the value of the input position along the d-th dimension (e.g. for images d = 2 and for video d = 3). Instead of adding the positional embeddings to image features, we found that concatenating them improved performance. This can be attributed to the fact that the input feature dimension in NLP models is larger than the modalities used here(image, videos, audio).
These feature-based positional encodings allow the model to learn how to exploit the positional dependencies. They can easily be adapted to various domains as long as the input dimensionality is relatively small and known. Moreover, they can be used in a multi-modal setting: each mode can use separate positional encoding based on its dimensionality and categorical positional encodings can be used to distinguish domains.
Experiment and Evaluation
We conduct several experiments and compare the Perceiver to models like ResNet-50, ViT-B, and the stack of transformers across three different domains: vision, sound and audio, and point clouds.
Images: ImageNet
We first test the Perceiver on the ImageNet classification task. The positional encodings are generated by using the (x,y) positions of the 224x224 input crop. The (x,y) coordinates are standardized into [-1,1] range for each dimension of the crop before generating the positional features. We found that using image coordinates instead of crop coordinates causes overfitting. Crops introduce augmentation in position and aspect ratio and stop the model from making associations between RGB values and positional features.
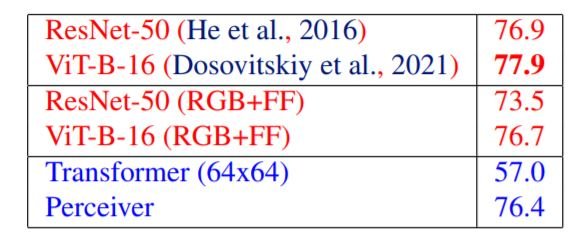
As shown in the above table, our model shows comparable performance to SOTA models on ImageNet. When the baseline models were trained with positional Fourier Features(RGB+FF), the performance became slightly worse. Since transformers cannot handle the 224x224 long sequence, the image had to be downsampled to 64x64 before testing.
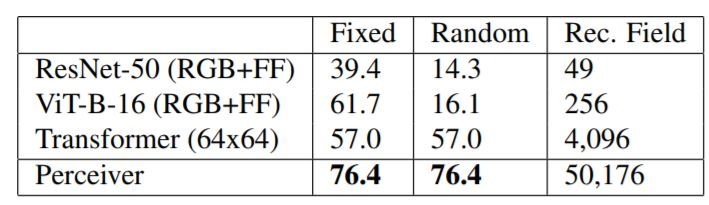
Next, we evaluate the models on the permuted versions of ImageNet. First, we use a single permutation on all images(Fixed), and then we randomly permute all the pixels(Random). The transformer and perceiver are unaffected by this while the ResNet-50 and ViT-B, which use grid structure are devastated. Now one might think why we wouldn't use the 2D grid structure although it is given. This experiment shows the challenges involved in using CNNs and ViT with certain modalities or cross-modalities. Eg: converting point clouds to 2D grids is complicated and how would one represent a combination of audio and video as a grid?
Sound and Audio: AudioSet
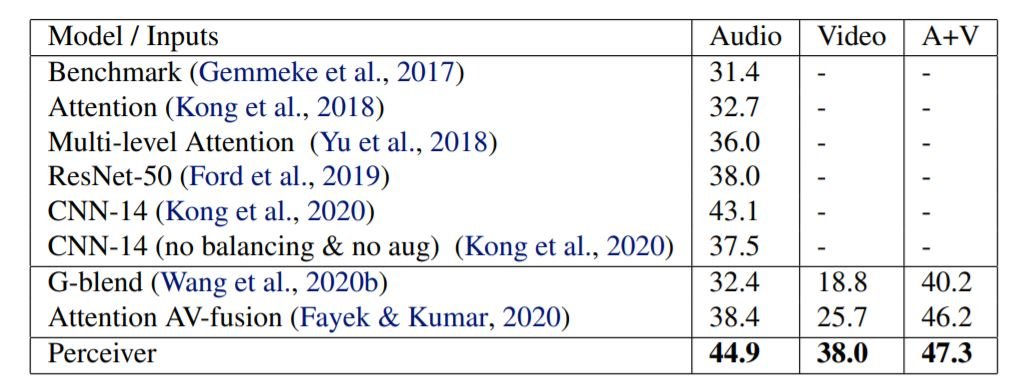
We also tested the Perceiver on the AudioSet dataset: a large dataset with 10 second long 1.7M training videos and 527 classes. As shown above, the Perceiver beats all other SOTA models across audio, video, and A+V classification tasks. The audio was sampled at 48 kHz with 61,400 inputs over 1.28s of video. We used Fourier features not just on time dimension but also on audio amplitude dimension.
For the videos, a 2x4x4 shaped bounding box was used to downsample the 32 frame clip at 256x256 pixels giving a total of 65,536 inputs. Without the downsampling, the input sequence would have 32x256x256 i.e. about 2 million inputs, the model would still work! although slow.
For audio+video (A+V), these sequences are concatenated together. We make the dimension of the audio input equal to the video input by concatenating extra modality-specific learned embedding to it.
Point Clouds: ModelNet40
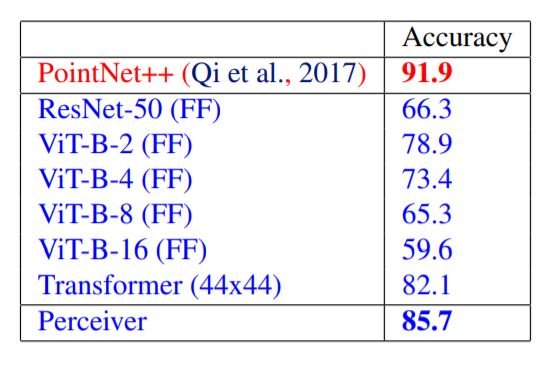
ModelNet40 is a dataset of point clouds derived from 3D triangular meshes and given the coordinates of 2000 points in 3D space, the model makes predictions from 40 man-made categories. Here, each point cloud is arranged into a 2D grid randomly and fed to the model. Perceiver outperforms ViT and ResNet but is unable to beat the domain-specific PointNet++. However, it is necessary to note that PointNet++ uses sophisticated data augmentation and feature engineering methods.
Summary
The Perceiver architecture can handle input sequences longer than a hundred thousand vectors. This makes it possible to use the same Perceiver model across different modalities with minor or almost no reconfigurations. Nevertheless, the model still makes use of domain-specific positional encoding inputs and data augmentations which limits it from flexibly processing arbitrary inputs. Being able to strip away these domain-specific prerequisites is an area of research for future works.



Categories related to this article



![[MusicLM] Text-to-Mu](https://aisholar.s3.ap-northeast-1.amazonaws.com/media/October2023/musiclm-520x300.png)


