Transformers As Universal Computation Engines: Language-pretrained Transformers Help On Non-linguistic Tasks!
3 main points
✔️ Finetuning a language model to perform tasks in vision, protein fold prediction, and other domains.
✔️ Competitive or better performance than fully training the transformer on task-specific datasets.
✔️ More efficient, faster to train, and better performance than random weight initialization across various domains.
Pretrained Transformers as Universal Computation Engines
written by Kevin Lu, Aditya Grover, Pieter Abbeel, Igor Mordatch
(Submitted on 9 Mar 2021)
Comments: Accepted to arXiv.
Subjects: Machine Learning (cs.LG); Artificial Intelligence (cs.AI)
code:
first of all
The transformer architecture has pushed the state of the art across several domains. Transformers have been used for a wide variety of tasks in vision(object detection, instance segmentation), NLP(sentiment analysis, language modeling), vision + NLP( visual entailment, visual question answering), and more. Recently, a single unified transformer(UniT) model has been shown to perform as well as fine-tuned task-specific models.
The general trend is to train a large model on a large dataset and then finetune the model to task-specific smaller datasets. For example, a GPT model pre-trained on a huge corpus of text data can be finetuned on a sentiment analysis dataset. It would be really interesting to see if a model pre-trained on a large text dataset and finetuned using a dataset in a different domain(e.g. vision) would work equally well.
We hypothesize that transformers, specifically the self-attention layers of the transformer can be pre-trained on a data-rich domain like NLP, where there is an abundance of unsupervised training data, and then fine-tuned to work very well in a different domain like vision. In this paper, we show that a transformer language model is able to perform very well in numerical computation, image classification, and protein fold prediction tasks without any expensive fine-tuning. Specifically, we take a pre-trained GPT-2 model and only fine-tune 0.1% of the model(Frozen Pretrained Transformer), and yet it has comparable performance to a fully fine-tuned transformer or LSTM.
model

We use a GPT-2 model with embedding size/hidden dimension ndim, the number of layers as nlayers, input dimension as din, output dimension as dout, and the maximum sequence length as l. The self-attention parameters are frozen and only the following parameters are fine-tuned based on the task on hand:
1)Output Layer: The output dimension is a simple linear layer and we keep it minimal to ensure that the frozen self-attention layers are performing the most tasks. For a classification task, the output dimension is equal to the number of classes. Ex: 10 in the case of CIFAR-10 where the weight matrix of the linear layer has dimension 768x10.
2)Input Layer: The dimension of the input data varies depending on the dataset and therefore needs to be finetuned too. Again, a simple linear layer is used to ensure that the frozen self-attention layers are more involved. The dimension of the weight matrix of the linear layer is ninxndim i.e. 16x768 in the case of CIFAR-10.
3)Layer Norm Parameters: As in standard practice, we finetune the scale and bias parameters of the layer norm layers. There are two layer norms per block for GPT-2 which is a total of 4 × ndim × nlayers parameters = 4x768x12 = 36684.
4)Positional Embeddings: Experimentally, we found that positional embeddings are surprisingly similar across modalities. However, finetuning them is beneficial. The positional embeddings have dimension lxndim, for the base model on CIFAR: 64x768 =49512 parameters.
For the base CIFAR-10 model, these parameters account for only 0.086% of the total GPT-2 model, and 0.029% of the GPT-2 XL model.
Evaluations
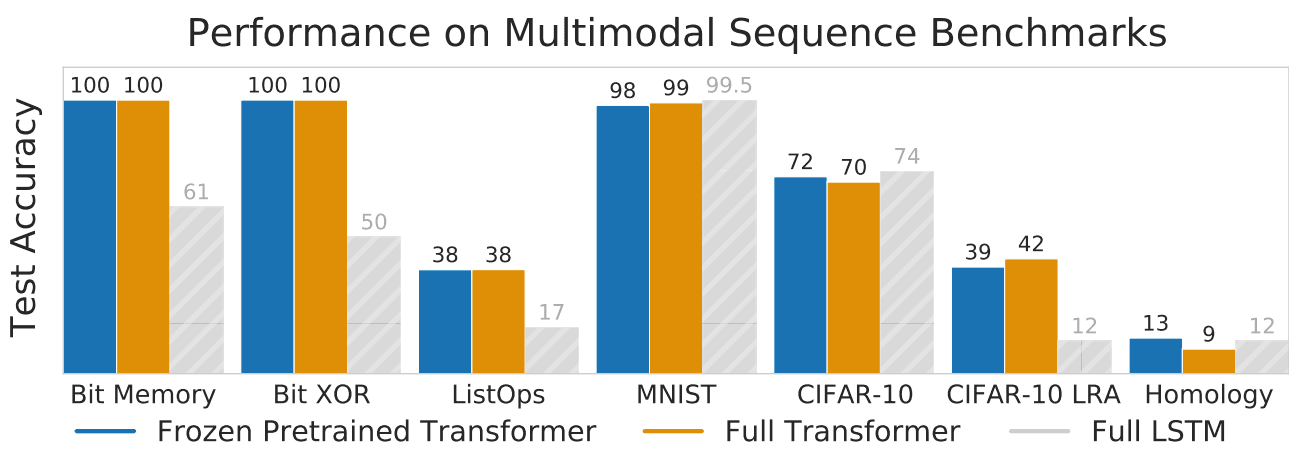
We evaluate the model on tasks across different domains: Bit memory(task to remember 1000 bit long bit sequences), Bit XOR, ListOps(Predicting the result of list operations), MNIST, CIFAR-10, CIFAR-10 LRA(Modified version of CIFAR-10 taken from long-range arena benchmark with longer input sequence), Remote Homology Detection(protein fold prediction).

The model finetuned with frozen self-attention parameters is called the frozen pre-trained transformer(FPT). In addition to this, we train an LSTM model for the task along with a separate fully trained transformer model(Full). The results in all tasks are shown in the table above. Across all tasks, FPT attains better or comparable performance than the Full transformer and LSTM.
For the Bit XOR and Bit Memory tasks, FPT attains 100% accuracy for sequence length of 5 i.e. it is able to fully recover the sequences. We found that it can recover the exact algorithm even for larger sequence lengths of 256. This shows that in contrast to LSTM, FPT has a fairly larger memory.
It was found that fully training a 12-layer transformer model can be difficult in the case of a smaller dataset because of instability in training/ease of overfitting. For CIFAR-10 model, a 3-layer model was found appropriate. This adds the additional trouble of tuning the model size in the case of the full transformer. In contrast, the performance of FPT was found to improve with the increase in model size.
The Importance of Prior Learning Modalities
Here, we look at how varying the modality of prior learning (verbal, visual, random, memory) affects FPT performance across tasks.

The model self-attention parameter of the ViT transformer pre-trained on the 1) ImageNet dataset. self-attention parameter of the ViT transformer pre-trained with 1) the ImageNet dataset, 2) random initialization, and 3) the Bit Memory Task pre-trained model's self-attention parameters. The results in the table above show the effectiveness of language pre-training: FPT outperforms ViT on the MNIST(vision) dataset, and surprisingly on the random dataset it significantly outperforms on all tasks. On the other hand, ViT almost beats random initialization only on the vision task and is the worst on homology.
Improving computational efficiency by pre-learning the language

As can be seen in the table above, FPT converges faster than random initialization and saves computational resources.
Prevent overfitting by pre-learning the language

It was observed that FPT is less prone to overfitting and generalizes well to the validation data whereas the other two transformers(Vanilla Transformer and Linformer) overfit due to fewer instances in the dataset(50k for CIFAR-10 LRA in the above table). Also, FPT models tend to underfit the data which is why increasing model capacity improves performance.

Should the feed-forward and attention layers be finetuned?
When we tried to also finetune the feedforward layer, performance improvements were seen on the CIFAR-10, Homology, and MNIST dataset, but prior works have shown that this could lead to divergence during training. Fine-tuning the attention layers, or both the attention and feedforward layers was detrimental.

Summary
The extensive experiments show that finetuning language models that have been pre-trained on large corpus of text data can help improve model performance across a wide variety of tasks. It is clear that language training allows the self-attention layers to learn representations that are useful in arbitrary data sequences. This frees us from the need for expensive and time-consuming fine-tuning of the entire network. As larger datasets (like the recent Wikipedia Image Text-WIT Dataset) are developed, future works could also investigate other data-rich modalities (larger vision datasets, vision-text datasets-WIT).



Categories related to this article



![[MusicLM] Text-to-Mu](https://aisholar.s3.ap-northeast-1.amazonaws.com/media/October2023/musiclm-520x300.png)


