気まぐれAIニュース4/10~4/28(最近話題になったAI/機械学習界隈のトレンドまとめ
気まぐれAIニュースというのを始めてみました。
主に、編集部のMが独断で面白いと思ったAI界隈のニュースや、トレンドをさらっと紹介するというものです。
”Weekly(毎週)”だと正直やり切れる自信がないので、”気まぐれ”にしてみました。基本的に直近1週間~3週間くらいの間に話題になったニュースを扱っています。
1、畳めなかったエアリズム 全自動折り畳み機、事業解散へ
まずは、こちら。世界初の全自動衣類折り畳み機「ランドロイド」の事業化を目指してきたセブン・ドリーマーズ・ラボラトリーズ(東京・港)が倒産したという悲しいニュース https://business.nikkei.com
アームは様々な種類の布を持ち上げられるが、どうしてもつかめない素材があるとのことだった。それが、カジュアル衣料品店「ユニクロ」の人気商品「AIRism(エアリズム)」だった。シルクのような肌触りが特徴だが、それだけにロボットアームが扱うのが難しかった。完全な製品を世に出したいと考えるパナソニックは、この点を重く受け止め、発売に難色を示したという。
個人的に、エアリズム畳めないくらい別にいいんじゃないの・・?って感じですが、1種類だけ畳めないものがあることを理由に出資者のパナソニックがリリースを止めさせたようです。Twitterでも言われてましたが、この技術はそのまま海外に流れていきそうですね…日本独特のものづくりにおける完璧主義な精神が国際競争で足を引っ張ってる感じがします。

過去記事でも紹介しましたが、最近の画像認識の技術を使えばどこに何があるか特定することは容易になってきていますが、ロボットは依然として非剛体の扱いが不得意です。掴んだあとに変形するものを自在に扱うことは簡単ではありません。
米FoldiMateなんかは、これらのロボットが一番苦手な「服の最適な部分をつまむ」作業を人間が前処理としてに行う事で解決しています。FoldiMate – the robotic laundry folder
2、令和時代に必要なのはバイリンガル人材?
MITの学長が機械学習(Machine Learning、ML)のスキルと専門知識を兼備した人材を「未来のバイリンガル(the bilinguals of the future)」と呼んでいるという話。めちゃくちゃTwitterで話題になってました。

ディープラーニングは、特定のものを判別・識別するといった事例が多いかと思いますが、以前から、適用先のドメイン知識について「作ったAIよりも自分が詳しくなる」という現象はよく見られていました。つまり適用先の専門知識がないと精度の高いAIは作れないともいえます。 【関連】機械学習をやると、AIより人間の方が詳しくなる現象
一方コンピュータ・サイエンスの専門家が他分野に侵食しつつあるとも言われています。
たとえば、現在生まれつつある「◯◯の専門家」vs「コンピュータの専門家かつ◯◯の素人」という対立構図においては、後者が前者を駆逐していくのは明白ではないでしょうか。どっちにしろ、適用先のドメイン知識+MLの知識両方兼ね備えてる人材が最強なことには変わりなさそうです。

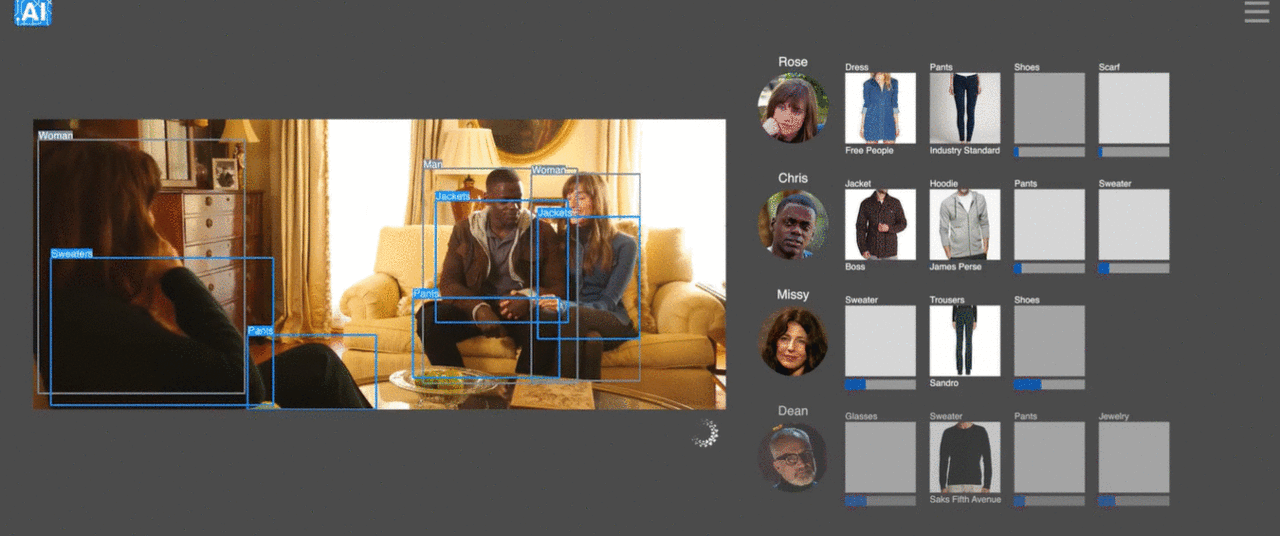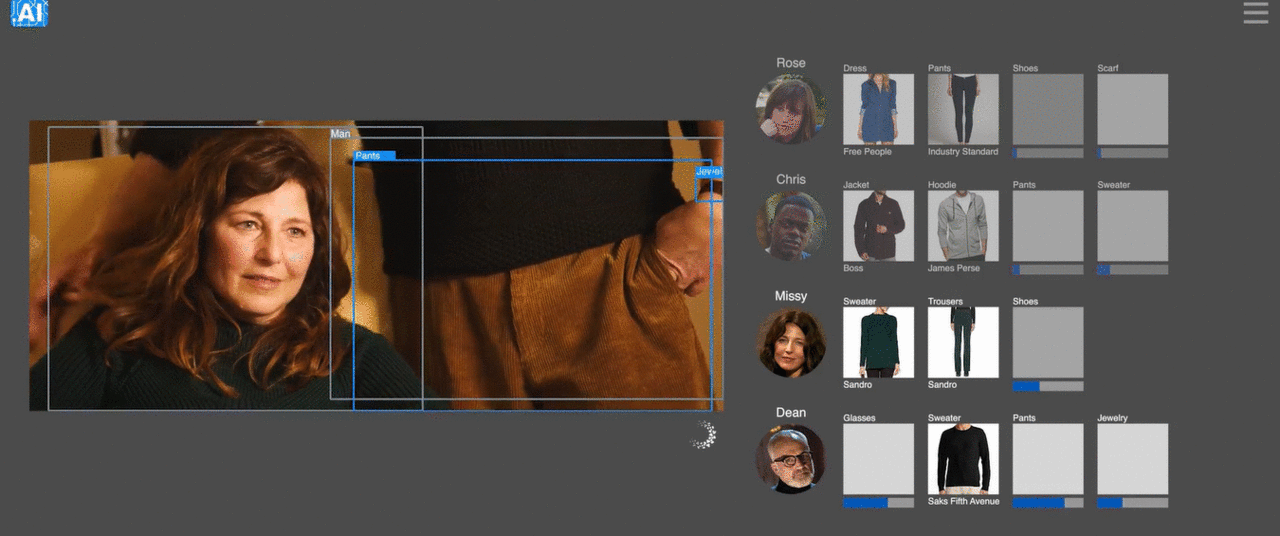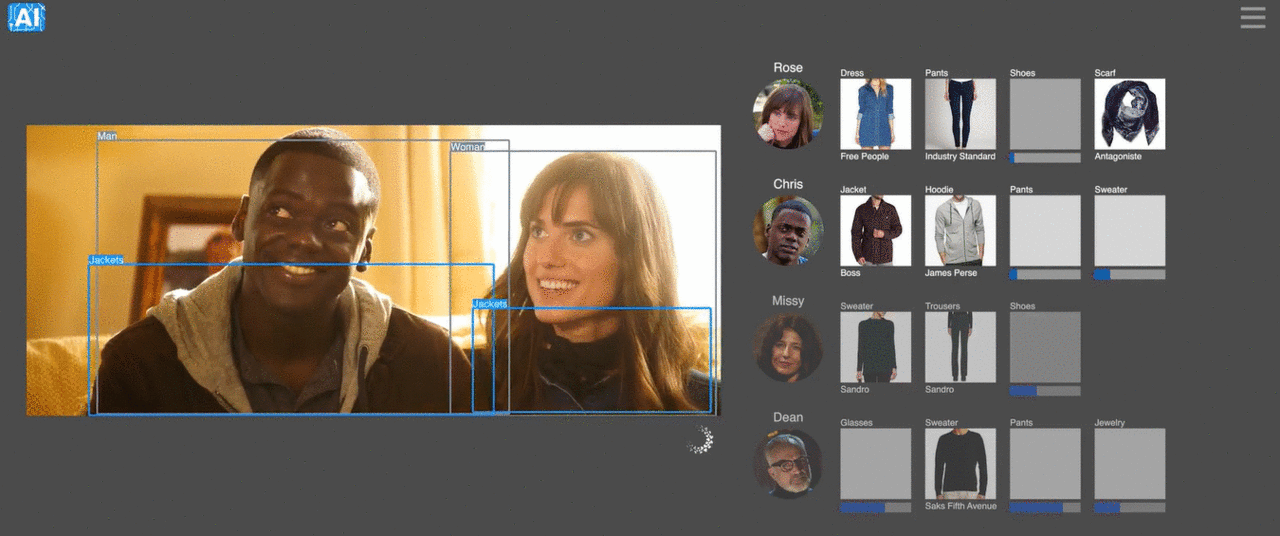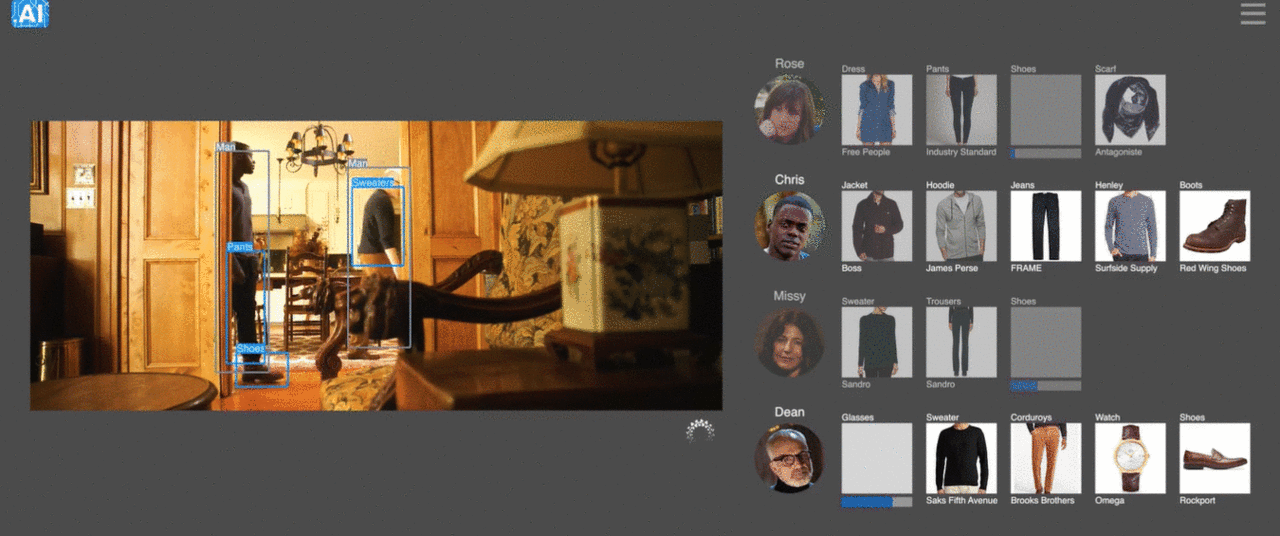
3、動画に映ってる人が身につけている服をほぼリアルタイムで特定できるサービス

ニューヨークを拠点とするTHE TAKE AIという会社が行ってる、芸能人など動画に映ってる人が身につけている服をほぼリアルタイムで特定させるというサービス。テレビや映画ショッピングだけではなく、スポーツ中継などにも応用可能で、さらにスマホアプリでも使えるそう。同社は手作業で作成した製品のデータセットでネットワークをトレーニングしており、テレビのエピソードごとに500の個別の製品、映画ごとに約2,000の製品をタグ付けしているとか。動画内で発見した服を即購入できる日も近そうです。
個人的に印象に残ったのが以下の言葉
“TheTake’s mission is simple: making media content shoppable,”(TheTakeの使命は簡単です。メディアコンテンツを出荷可能にすることです)
広告がコンテンツ化するなんて数年前から言われていますが、まさにその世界観を体現したようなサービスではないでしょうか
4、データグリッド「実在しない」人物の全身画像生成AIを開発

データグリットが実在しない人物の全身画像を自動生成するAIである「全身モデル自動生成AI」を開発したそう。
データグリッドといえば、ご存知の方も多いと思いますが、GANを用いた架空のアイドルを自動生成しまくる「アイドル生成AI」が有名でした。どこかで見たことがあるようなないような顔が生成されまくってました。

以前のアイドル自動生成AIでは顔領域のみの画像生成でした。生成された人物の表現力を高めるために、「全身生成」と「動作生成」の2つの研究開発に取り組んできたとのこと。高精度の全身生成モデルは先行事例がなく、チャレンジングな研究開発だったそうですが、高解像度(1024×1024)の全身モデル画像を安定して生成することに成功しています。
正直GANでアイドルの顔を生成する技術はあまり実用性がなさそうでしたが、今回のGANは実在しないファッションモデルを自動生成するということで、アパレル広告などに使えそうです。
個人的にファッションモデル(芸能人含め)はみんな同じに見えるので、一部架空人物に置き換わっても全く問題なさそうです。
5、意図した動作だけを検知するジェスチャーUI搭載の新しいウェアラブル・デバイス
Wearable Devicesというイスラエルのベンチャーがリストバンドのように手首に装着するジェスチャー認識デバイス「Mudra」を開発しました。
ジェスチャー認識とは、センサやデバイスを用いずにディスプレイに表示された仮想物体を直接触るようにして操作するシステムのことです。

このデバイスの裏面には複数の電極がついており、これがこのデバイスの鍵となるセンサーだそう。このセンサーが指を動かすための脳からの司令となる生体信号がそれぞれの神経を通るときの電気伝導を検知します。これにより、指を曲げたり手を動かすジェスチャーを様々なコマンドに対応させることができます。
あくまで、装着した人が指を動かそうと「意図」したときに神経に流れる信号を検知するので、他人に指を動かされても神経の中に信号は流れません。つまり、ジェスチャー認識ではありますが、「意図」という他人にハッキングされることのない信号のインタフェースです。
6、Open AI 長い文脈に強い生成モデルを発表
OpenAIがattentionメカニズムで有名になった言語モデルtransformerを改良して、テキスト、画像、音声の生成に対応したSparse transformersを発表しました。Generative Modeling with Sparse

attentionでは全ての出力要素が、全ての入力と繋がっており、それらの間の重みは, attention と呼ばれる、環境に基いて同時に計算されていました。この計算方法だと N×Nアテンション行列をすべての層とパーツにおいて作らなくてはなりませんが、これを画像やオーディオのように、多くの要素を持つデータ型に適応しようとすると、非常に多くのメモリを消費します。
一方Sparse attentionでは、各出力に置いて入力データの一部のみに重み付けを行います。選ばれた一部の入力データが全体と相関があれば、後から残りの(選ばれなかった)データを推定することができ、かつ計算量を減らすことができます。計算コストが削減されたことにより、従来より、長い文脈のものを扱えるようになりました。
7、LINEが5年ぶりに索再参入「画像検索」は新トレンドになるか
個人的に熱かったのがコレ!LINEが約5年ぶりに検索サービスに再参入するという話。「画像検索」は新トレンドになるか
LINE Pashaは検索した対象物をカメラで写すだけで、情報を検索できるアプリだ。例えば、商品写真を撮影するだけで、商品情報を調べたり、ECサイトでの販売価格を比較したりできる。画像認識技術とディープラーニングを組み合わせることで、利用者の撮った写真から瞬時に情報を提供するサービスを開発した。「世界一のビジュアルサーチを目指す」とLINE取締役CSMOの舛田淳氏は意気込む。
ハイパーテキストがそのまま画像(ビジュアル表現)になったみたいな世界観が実現すれば、かなり面白いことになりそう。「言葉に抽象化して検索する」という過程をすっ飛ばして、概念自体を調べられるようになるわけだから、人間のコミュニケーションレベルが2段階くらい上がりそうです。インスタグラムもそうですが、ますます言語から、視覚ベースのコミュニケーションが活発化していきそうな予感です。しかもディープラーニングと相性も良さそう。個人的に楽しみなサービス。
関連:ビジュアライズする世界。自動的に改善を提案する視覚ベースの検索アプリケーションが登場
8、脳活動から声道の動きをシミュレートし音声合成を生成するBCI
ネイチャーから、脳の情報を使って声道の物理的運動(喉頭、咽頭、口腔、鼻腔など)の動きをシミュレートし制御することによって合成音声を生成するというBCIの論文が発表されました。AI-SCHOLARでも紹介しましたが、面白いのは、脳からの音響特性ではなく、脳が発する信号――声道のどの部分の筋肉をどのように動かすか――を詳細に測定した情報を元に仮想声道を構築しているという点です。
END終わり⊹
読んでいただきありがとうございました。
今週は休み削りながらいっぱい記事を更新したので他の記事も読んでもらえたらMは泣いて喜びます!
最新の注目記事
AIを騙せるか?持つだけで”人間”として識別されなくなるデジタル迷彩がついに開発される
社会人に役立つ人工知能本 三冊しかない説
Google、オーディオデータを視覚的に表現するデータ増強法「SpecAugment」を発表



この記事に関するカテゴリー






