数据增强中的两个量化指标是什么?~亲和力和多样性~
3个要点
✔️有两个指标可以定量评估数据增强~亲和力和多样性~
✔️当这两个指标得分都很高时,模型就会提高Acc。
✔️测试中途用DA关闭正则化的效果。
Affinity and Diversity: Quantifying Mechanisms of Data Augmentation
written by Raphael Gontijo-Lopes, Sylvia J. Smullin, Ekin D. Cubuk, Ethan Dyer
(Submitted on 4 Jun 2020) (ver2)
Comments: 10 pages, 7 figures
Subjects: Machine Learning (cs.LG); Computer Vision and Pattern Recognition (cs.CV); Machine Learning (stat.ML)
code:
首先
数据增强(DataAugmentation,DA)是一种通过增强数据来防止模型过度训练的技术,通过DA进行正则化,由于不需要触及模型的内容,因此被称为是一种提高泛化性能的简单技术。特别是在图像领域,已经有大量的DAs被研究和探索,为每个任务。其中,最佳的DA根据任务或数据性质的不同而逐一变化。特别是集中在图像领域,DAs可以粗略地分为以下两种类型。通常通过试错搜索以下两种类型的DA来寻找最佳DA。
- 图像的几何变换和光学处理。中耕、轮作等)。
- 区域删除和混合(Cutout、Cutmix等)等过程。
至于1.中的几何变换,通过旋转图像,我们可以增加训练数据来近似测试数据。例如,在植物图像分类的情况下,测试数据的拍摄角度可能与训练数据的拍摄角度不同,因此旋转可能是有效的。同样,对于光学转换,亮度调整似乎也很有效。这些DA的立场是基于隐含的假设,即训练数据和测试数据的分布应该在一定程度上相似。
但第二个呢?Cutout和Mixup创建的图像是否与测试数据相似? 在CutMix这个组合方法中,我们可以确认它在各种图像识别任务中是有效的,尽管它产生的数据可能不包括在测试图像中。这样一来,我们最近又发现,Augument在一定程度上偏离了训练数据,在某些情况下是有效的。包括DA的效果,通常是根据个案(CAM图像等)进行定性评价,定量的机制还不是很清楚。
谷歌大脑的研究人员发表的《亲和力与多样性:数据增强机制的量化》,全面介绍了定量DA评估方法和。并全面介绍了结果。具体来说,提出了亲和力和多样性两个DA评价的指标,并在此基础上对各种DA进行综合评价。 在这,我们对本文进行了讲解。(本文所有图片均来自于原文)。
评估DA的两个指标
在原论文的标题中,提出了Affinity(亲和力)和Diversity(多样性)两个指标。引用文件中的文字
1.Affinity和Diversity:可解释、易计算的指标,用于为增强性能提供参数。Affinity量化了增强数据对模型学习的训练数据分布的偏移程度。多样性量化了增强数据相对于模型和学习过程的复杂性。
Affinity(亲和力)量化了Augmentation将训练数据分布从模型学习的分布中转移出来的程度;Diversity(多样性)量化了Augmented数据相对于模型和学习程序的复杂性。
("Affinity and Diversity:("Affinity and Diversity: Quantifying Mechanisms of Data Augmentation"自从第2页引言)
有一个
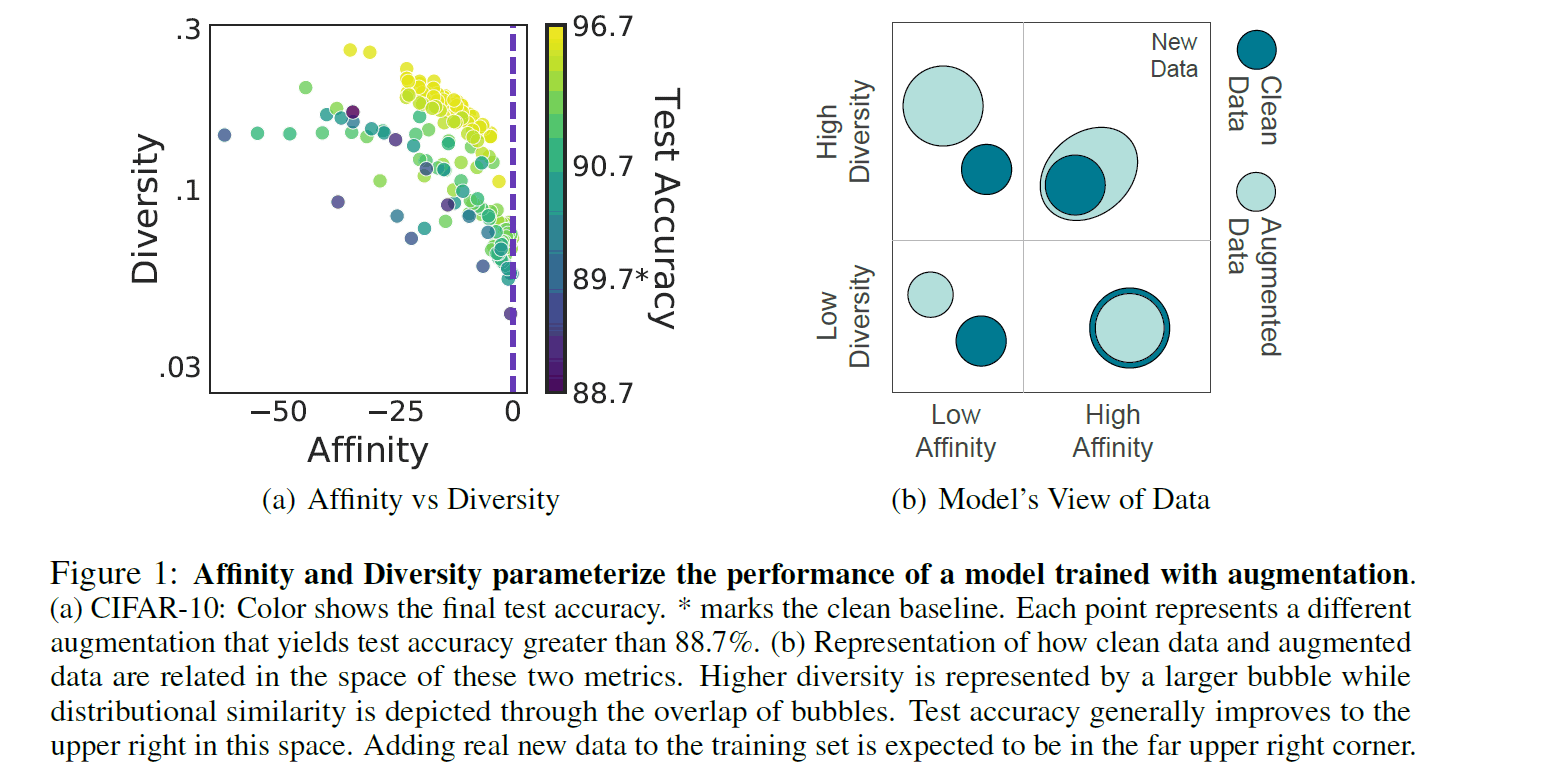
为了直观地解释这个指标,我们参考上图右图,Clean Data指的是未增强数据的分布,Augment Data指的是被DA增强的数据分布。如果我们从多样性轴上看,可以看到在高多样性的情况下,Augment数据的分布更广。从实际情况来看,这意味着不同种类的复杂数据已经通过重复随机DA产生,分布也变得更加多样化。接下来,如果看一下亲和力轴,我们可以看到Augument Data分布与高亲和力情况下的Clean Data分布重叠。从同样的实际情况来看,这意味着生成了与原始数据相对接近的数据,分布变得相互亲和。
让我们看看左图,看看亲和力和多样性如何才能算是好的DA。每个轴是一个指标,每个点代表一个独立的DA。点的颜色表示Cifar10测试数据的Acc,颜色越接近黄色表示测试精度越高。可以看到的是,接近黄色(DA)的点分布在亲和力和多样性指标都比较高的地方。需要注意的是,即使只有一个指标高,测试精度也不一定高。因此,本文称,在两个指标数值较高且平衡度不变的情况下,DA可以提高测试精度。
亲和力
我们来看看每个评价值。亲和力的计算由以下公式定义:
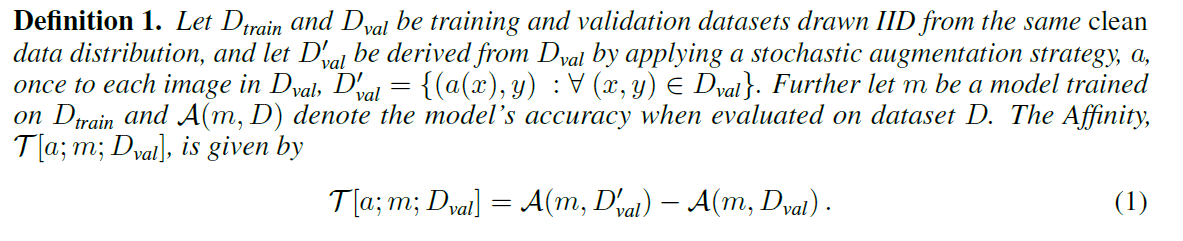
这里,从图中的文字来看
"$D_{train}$、$D_{val}$为从清洁数据分布中提取的训练和验证数据。$D'_{val}$是由Augment,$a$从$D_{val}$的分布中抽取的数据,概率为DA。$m$是在干净的训练数据$D_{train}$上训练出来的模型,$A(m,D)$是模型被数据集$D$验证时的准确度,Affinity用下式表示。"
与$D'_{val}$。那么Affinity的定义是由扩展验证数据$D'_{val}$验证的特定模型m的Acc与清洁验证数据$D_{val}$验证的Acc之间的差值,如上式。这里我们可以看到,通过固定$D'_{train}$,$m$这两个词,他们量化了扩展数据$D'_{val}$是如何影响训练模型$m$的准确性的。他们不只是评估输入数据的分布,而是通过将其与模型的测试精度挂钩来衡量基于模型的分布转变。从这个定义中,可以确认Affinity越接近0,就越有亲和力,即增强数据对模型的影响与训练数据相同。当然,该公式证实了Affinity不取正值,因为它是由增强数据$D'_{val}$验证的。
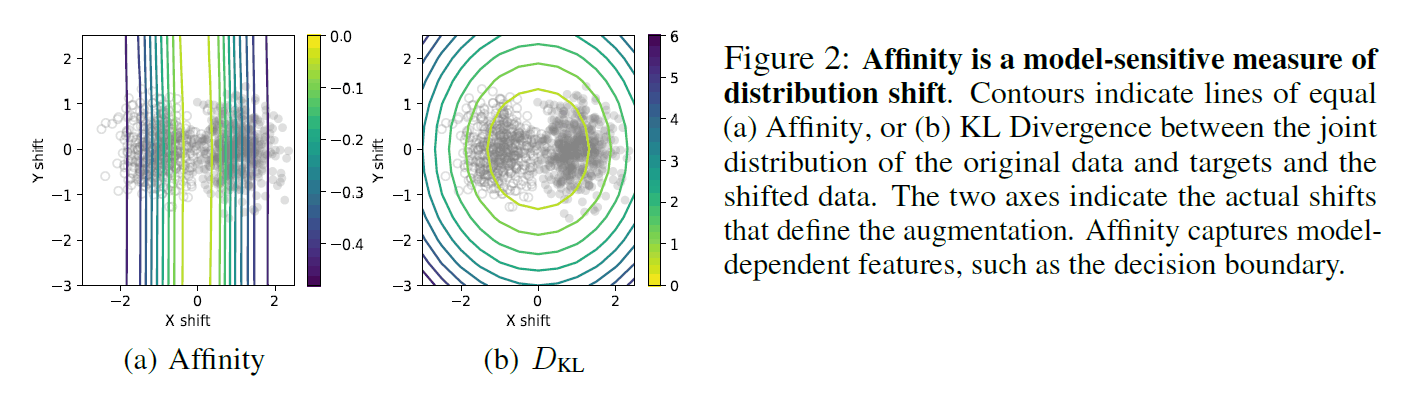
上图通过两个混合高斯分布的二元分类任务模拟,将Affinity与现有的KL距离进行了比较。彩线分别代表Affinity和KL的距离,意味着线上的数值是一致的。从这个图中可以看出,Affinity被描绘成几条垂直线,$D_{kl}$被描绘成同心圆。从实际的高斯分布中抽取的数据由两种圆点显示,可以确认Affinity是像决策边界一样抽取的,而$D_{kl}$抽取的方向与模型的准确性没有直接关系,以X和Y分布的偏移为例。这证实了Affinity在捕捉模型特征方面的有效性。
多元化
多样性则定义为以下公式:
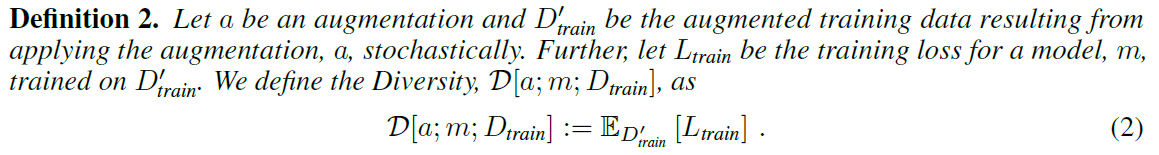
这里,从图中的文字来看
$a$是增量,$D'_{train}$是基于随机策略应用增量$a$扩展的训练数据集。此外,$L_{train}$是由$D'_{train}$训练的模型$m$的学习损失。那么多样性用以下公式表示。
在模型中。由于模型的学习损失$L_{train}$是由$D'_{train}$学习的结果,所以Diversity是通过计算基于$D'_{train}$的最终期望值来定义的。看完以上两个公式,如果省略第一条亲和力和多样性的引用,你可能会更明白。
使用两种指标对DA的分析结果。
在本文中,他们使用这两个指标对各种DA进行综合分析。具体来说,采用以下三个指标。
- 在传统DA中对这两个指标进行定量评估。
- 验证中途关闭正则化(DA)的效果。
- 静态和动态DA的比较评价
在传统DA中对这两个指标进行定量评估。
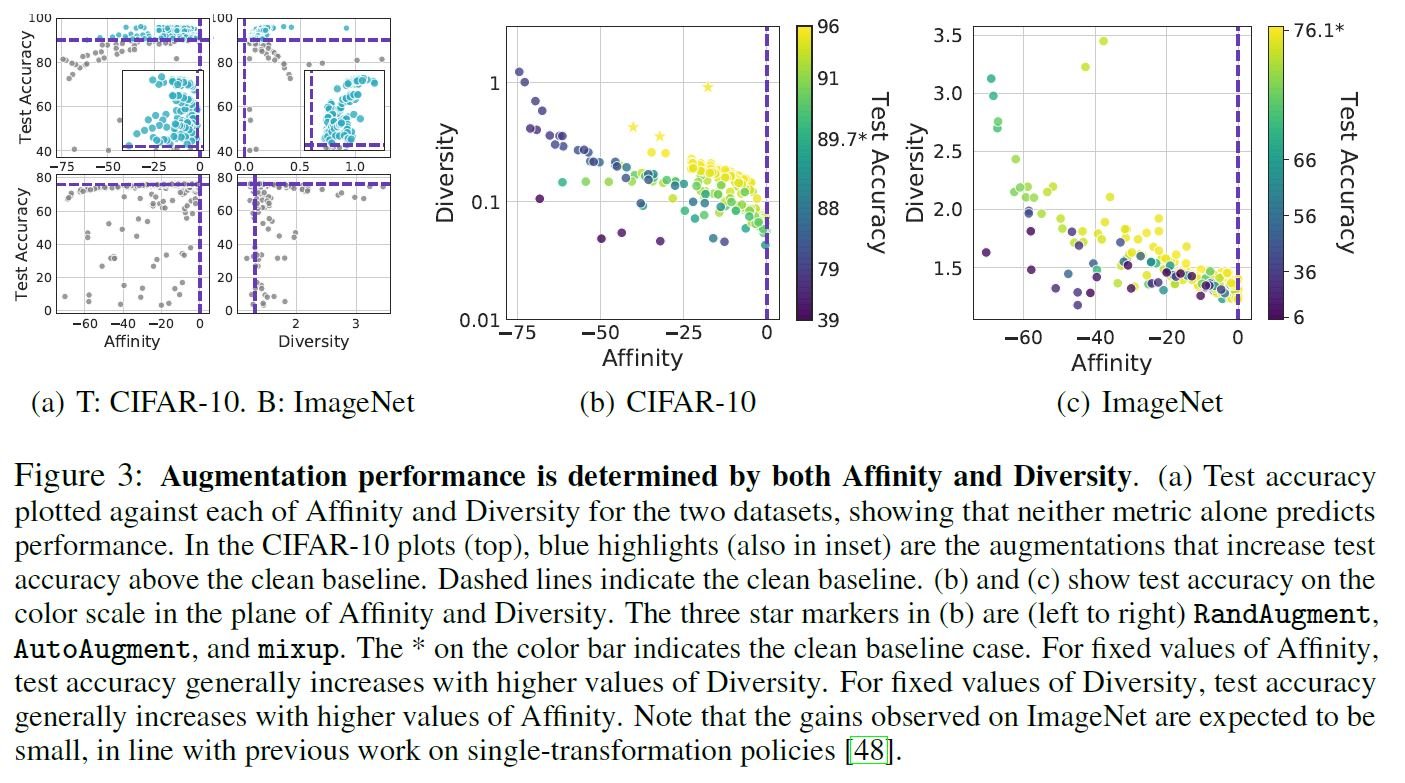
本文计算了CIFAR-10和ImageNet数据集的亲和力、多样性和各种DA中的测试Acc。上图(a)是一个二维平面,每个度量都是独立评价的。我们来看最上面一行(CIFAR-10)。蓝色虚线是清洁数据的基线,浅蓝色圆点是基线之外的DA,但可以确认TestAcc与其中一个指标没有必然联系。我们看下线(ImageNet)的Affinity就比较明显。下图(b)和(c)是一个三维图,两个指标都在纵轴和横轴上表示,TestAcc在色轴上表示。(当亲和力数值相同时,当Diversity越高时,TestAcc越高,反之亦然。
验证中途关闭正则化(DA)的效果。
论文还解释了中间关闭DA时的实验结果。最近,人们已经清楚地认识到,在特定时间开启和关闭正则化(或改变正则化程度)可以改善模型(权重衰减是正则化的一种)。在本文中,DA被认为是一种正则化。详细的背景和结果请参考原论文。
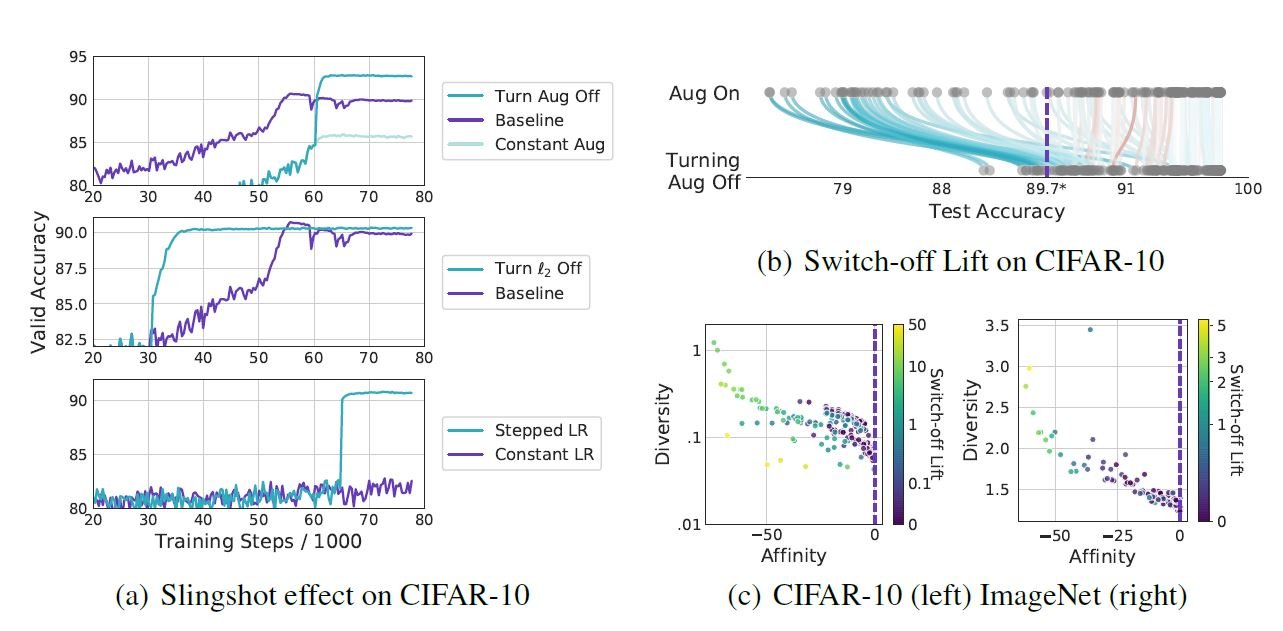
上图(a)上一行显示了在CIFAR-10的训练过程中,在55k迭代时关闭DA(在本例中,旋转)的情况(Turn Agg off)。可以看出,与Constant Aug和Baseline相比,Valid Acc的得分有所提高。这在原论文中称为弹弓效应。这说明即使是对Constant无效的DA,也可以通过中间的开关变得有效,超越基线。此外,(a)中的其他结果显示了在中间切换另一个不同于DA的正则化得到的结果。接下来,(b)显示了中间关闭各种DA时的综合结果。可以看出,当测试中间关闭DA时(蓝线),而不是继续打开Aug On,即使DA在基线以下,TestAcc也会普遍提高。这种改进在原文件中被称为"关机升降"。在上图(c)中,关机提升的幅度也与亲和力和多样性相关。
静态和动态DA的比较评价
在本文中,如以下句子
"除非另有规定,数据增强是按照标准做法应用的:每次绘制图像时,给定的增强都以给定的概率应用。我们称这种模式为动态增强。由于变换本身(如随机选择裁剪的位置)或策略(如仅以50%的概率应用翻转)中的任何随机性,每次的增强图像都可能不同。"
("Affinity and Diversity:("Affinity and Diversity: Quantifying Mechanisms of Data Augmentation"第3页,3.Methodより引用)
标准DA,即根据概率策略对某一图像进行变换,称为动态DA。另一方面,不采取任何概率策略的称为静态DA。
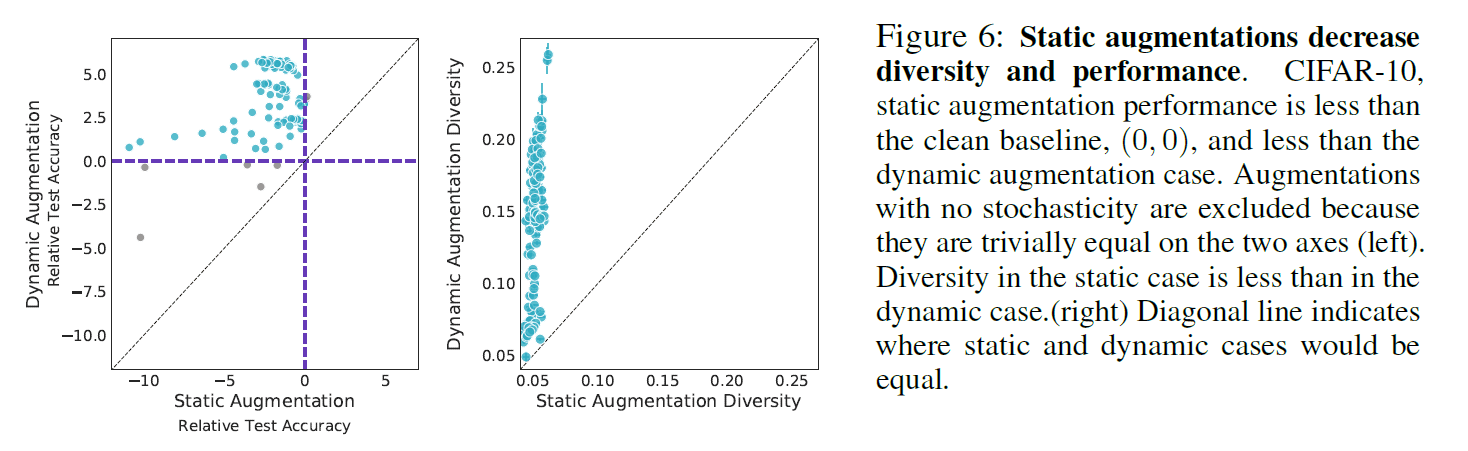
在上图中可以看出,不采用概率策略的静态DA比采用概率策略的动态DA准确率低。从左图中,我们可以看到,与动态情况相比,静态的DA总是有相对较差的TestAcc分数(没有DA低于黑色虚线)。有人认为,这可能是由于静态DA的Diversity也低于动态DA,即其多样性较低,如右图所示。
摘要
在本文中,我们讨论了谷歌大脑研究人员的"亲和力和多样性:量化数据增强机制",他们是第一个量化分析DA机制的人。这是对DA的第一次定量分析。笔者以为,这种对DA的量化可以明确DA本身的机理,从而不仅获得关于DA的知识,而且获得关于整个正则化的知识,这体现了机器学习的深度。除了基于定性评价提出DA,我感觉未来会有一个趋势,就是基于这两个指标,从定量角度提出新的DA。



与本文相关的类别






