同时使用合集和数据增强是否存在陷阱?
三个要点
✔️ 发现当结合集合数据增强时,校准可能会降低
✔️ 对上述问题进行了调查,找出了校准性能不佳的原因
✔️ 为避免上述问题,提出了一种新的数据增强方法"CAMixup"
Combining Ensembles and Data Augmentation can Harm your Calibration
written by Yeming Wen, Ghassen Jerfel, Rafael Muller, Michael W. Dusenberry, Jasper Snoek, Balaji Lakshminarayanan, Dustin Tran
(Submitted on 19 Oct 2020)
Comments: Accepted to ICLR 2021.
Subjects: Machine Learning (cs.LG); Machine Learning (stat.ML)
code:
首先
Ensemble方法是利用多个模型的预测平均值,Data Augmentation则是增加训练所用的数据量,常用来提高模型的校准和鲁棒性。
但是,在本文介绍的论文中,表明这两种方法的结合会对模型的校准产生负面影响。此外,研究了这种标定退化的现象,并提出了一种避免这种现象的方法CAMixup。
初步准备(校准、合集、数据增强)
在解释结合合集数据增强的负面效应之前,先介绍一些初步的知识。
校准
校准误差对评价模型预测的可靠性很有用。在本文介绍的论文中,我们使用下面解释的ECE作为评价模型可靠性的措施。
ECE(预期校准误差)
分类器的类预测和置信度(表示模型的预测概率)用$(\hat{Y},\hat{P})$表示。那么,ECE就是置信度与期望准确度之差的近似值$E_{\hat{P}}[|P(\hat{Y}=Y|]\hat{P}=p)-p|]$)。
这是通过将[0,1]的预测值分选成$M$等值区间(量化过程,将一定区间(bin)内的值用特定的值代替,比如中心值,就像在直方图中做的那样),然后找到每个bin的准确度/置信度差异的加权平均值。
设$B_m$是$m$-th个仓的集合,其预测置信度落在$(\frac{m-1}{M},\frac{m}{M}]$区间内,则$B_m$仓的准确度和置信度可以用下式表示
$Acc(B_m)=/frac{1}{|B_m|}/sum_{x_i\in B_m} I(hat{y_i}=y_i)$。
$Conf(B_m)=/frac{1}{|B_m|}/sum_{x_i \in B_m} hat{p_i}$。
$hat{y_i},y_i$分别表示预测标签和真实标签,$/hat{p_i}$表示$x_i$的置信水平。给定$n$的例子,ECE为$/sum^M_{m=1}/frac{|B_m|}{n}|Acc(B_m)-Conf(B_m)|$。
集合法
集合法是将多个模型的预测结果汇总的方法。在实验中,我们重点研究BatchEnsemble、MC-Dropout和Deep Ensembles三种合集方法与数据增强方法的交互作用。
数据增强方法
数据增强是一种通过对输入数据集进行各种变换(如图像剪裁)来提高泛化性能的方法。在实验中,我们研究了以下两种方法。
Mixup
给定一个例子$(x_i,y_i)$,Mixup用以下公式表示。
$\tilde{x}_i=\lambda x_i+(1-\lambda)x_j$
$\tilde{y}_i=\lambda y_i+(1-\lambda)y_j$
其中$x_j$是来自TRAIN集的样本(从一个迷你批次中获得),$\lambda \in [0,1]$是从beta分布$beta(a,a)$中取样的($a$是一个超参数)。
AugMix
让$O$是一组数据增强操作,$k$是AugMix的迭代次数。在这种情况下,增强操作$op_1,...。,op_k$和它们的权重$w_1,...。,w_k$(Dirichlet分布(a,...),a)),用augmix的增量用下式表示。
$\tilde{x}_{augmix}=mx_{orig}+(1-m)x_{aug}$.
$x_aug=\sum^k_{i=1}w_iop_i(x_{orig})$
实验
在下面的实验中,我们研究了结合数据增强的合集校准。首先,在CIFAR-10/100上应用Mixup的结果如下。
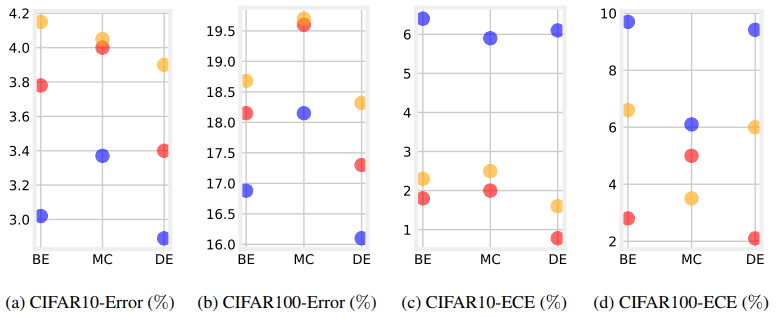
这些结果显示了五个随机种子运行结果的平均值。红色只代表合体,蓝色代表Mixup+合体,橙色代表两者都不是。在图(a)和(b)中,我们可以看到Mixup和Ensemble的组合提高了测试性能(减少误差)。
另一方面,图(c)和图(d)显示,当Mixup与Ensemble结合时,校准效果更差(ECE增加)。
为什么Mixup合集会使校准恶化?
我们更详细地研究了当集合体与数据增强相结合时的校准退化现象。下图为BatchEnsemble和Mixup组合时,不同置信区间计算出的平均精度和平均置信度的差异。
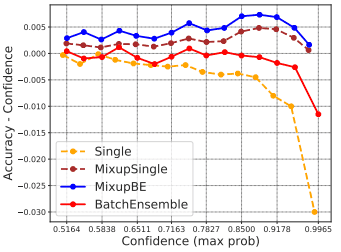
如果准确度与置信度的差值(纵轴)为正,则说明该准确度的置信度较低(置信度被低估),如果为负,则说明置信度较高(置信度被高估)。
该图显示,与Single网络情况相比,BatchEnsemble-only和Mixup-only情况下的准确性-可靠性差异变得更大,并接近零。
在Misup+BatchEnsemble的情况下,整体的精度-可靠性差异偏向于正向,说明相对于精度而言,可靠性被低估了。换句话说,虽然数据增强法和合集法具有防止高估置信度的作用,但两种方法同时使用反而低估了置信度,这似乎是校准恶化的原因。
再举一个可视化的例子,在一个由5个簇组成的简单数据集上训练一个三层MLP的置信度(softmax概率)如下图所示
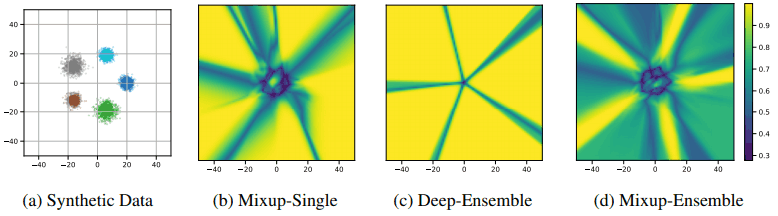
在Mixup/no ensemble情况下(c),预计总体概率较高(黄色)。引入Mixup后,这种情况得到了缓解,同时使用合集,我们可以看到,整体的置信度预测要低很多(绿色)。
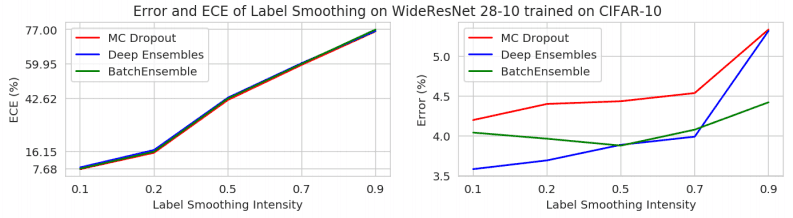
此外,标签平滑是抑制置信度过高的最有效方法之一,当这种标签平滑与合集一起使用时,也会出现同样的现象。当标签平滑与合集一起使用时,也会出现同样的现象,如下图所示,标签平滑应用得越强,ECE的增幅越大。
信心调整混合集合(CAMIXUP)。
在本文中,我们提出了CAMixup作为一种方法来防止这种由于低估置信度而导致的校准退化,CAMixup的基本思想是,在分类任务中,预测的难度可以因类而异。在这种情况下,对于预测容易的班级,宜提高信度,对于预测困难的班级,要防止信度提高太多。
CAMixup就是基于这个思想,对每个类的Mixup应用程度不同,特别是对模型置信度可能被高估(难以预测)的类。如下图所示。
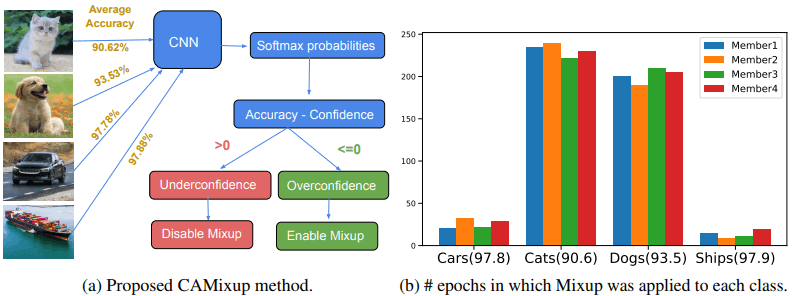
如左图所示,如果精度-置信度差值为正,则不应用Mixup,如果为负,则应用Mixup。在右图中,显示了250个纪元中每个类的Mixup应用次数。在这种情况下,我们可以看到Mixup经常应用于难以预测的类(狗和猫)。
使用CAMixup的结果如下。
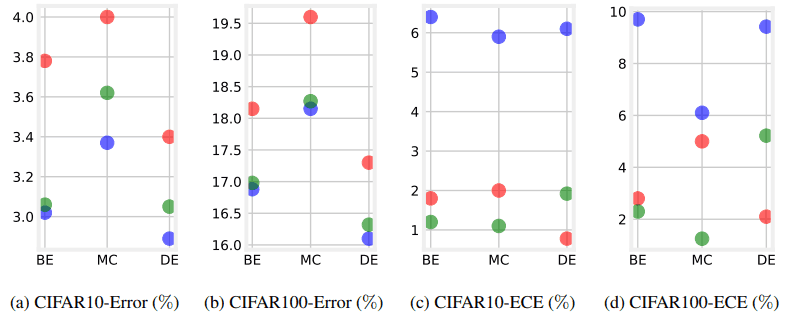
红色显示的是合奏的结果,蓝色显示的是Mixup+合奏,绿色显示的是CAMixup+合奏。图(a)和图(b)显示,与常规Mixup相比,测试精度略有降低,但ECE可以显著降低。在下表中,我们还显示了ImageNet上的结果。
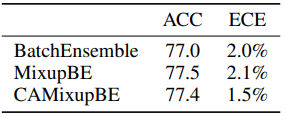
研究表明,在精度损失可以忽略不计的情况下,ECE可以得到显著提高。
分配班期间的业绩
CIFAR-10-C/CIFAR-100-C(C表示腐败)的评价结果如下:
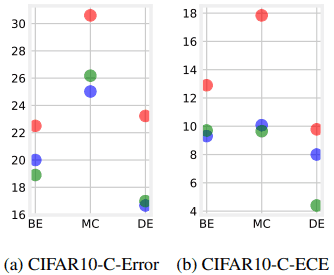
如图所示,CAMixup即使在发生分布转移的任务环境中也是有效的。CAMixup在AugMix上也有很好的表现,AugMix是一种先进的数据增强方法。结果如下:
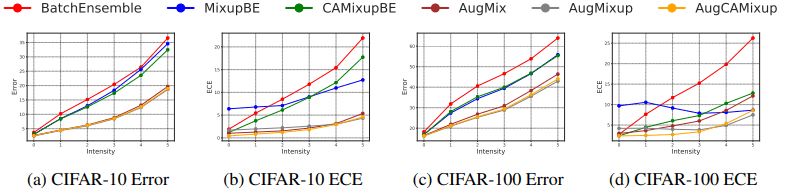
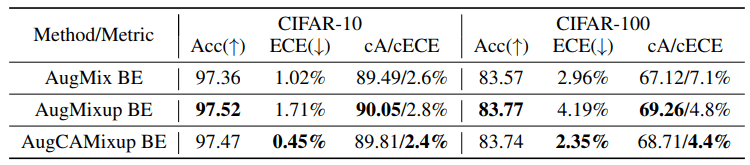
AugMixup是一个结合了AugMix和Mixup的方法(细节省略)。修改后的AugMix结合CAMixup(AugCAMisup)的版本,与普通CAMixup的情况一样,都能显著提高ECE。
摘要
在下面的论文中,证明了当合集与数据增强相结合时,校准会降低。这可能是由于合集和数据增强低估了置信度。为了避免这种情况,我们提出了CAMixup,根据预测类的难易程度来改变Mixup的应用。
虽然数据增强和合集都是提高性能的有效方法,但这是一项重要的研究,我们发现了一种将它们结合在一起可能会带来危害的现象,并展示了一种解决方案。



与本文相关的类别






