
优于ViT!大规模CNN的新基本模型!:InternImage
三个要点
✔️ 以可变形卷积为核心的CNN模型在分类、检测和分割方面实现了与ViT相同或更好的准确度!
✔️ 在物体检测和分割方面取得了令人印象深刻的第一名!
✔️ DCNv3是DCNv2的改进版,以更少的参数扩展了3x3核的接受领域!在这个过程中,我们可以看到,DCNv3是一个很好的例子。
InternImage: Exploring Large-Scale Vision Foundation Models with Deformable Convolutions
written by Wenhai Wang, Jifeng Dai, Zhe Chen, Zhenhang Huang, Zhiqi Li, Xizhou Zhu, Xiaowei Hu, Tong Lu, Lewei Lu, Hongsheng Li, Xiaogang Wang, Yu Qiao
(Submitted on 10 Nov 2022 (v1), last revised 13 Nov 2022 (this version, v2))
Comments: Published on arxiv.
Subjects: Computer Vision and Pattern Recognition (cs.CV)
code:

本文所使用的图片要么来自论文、介绍性幻灯片,要么是参考这些图片制作的。
介绍
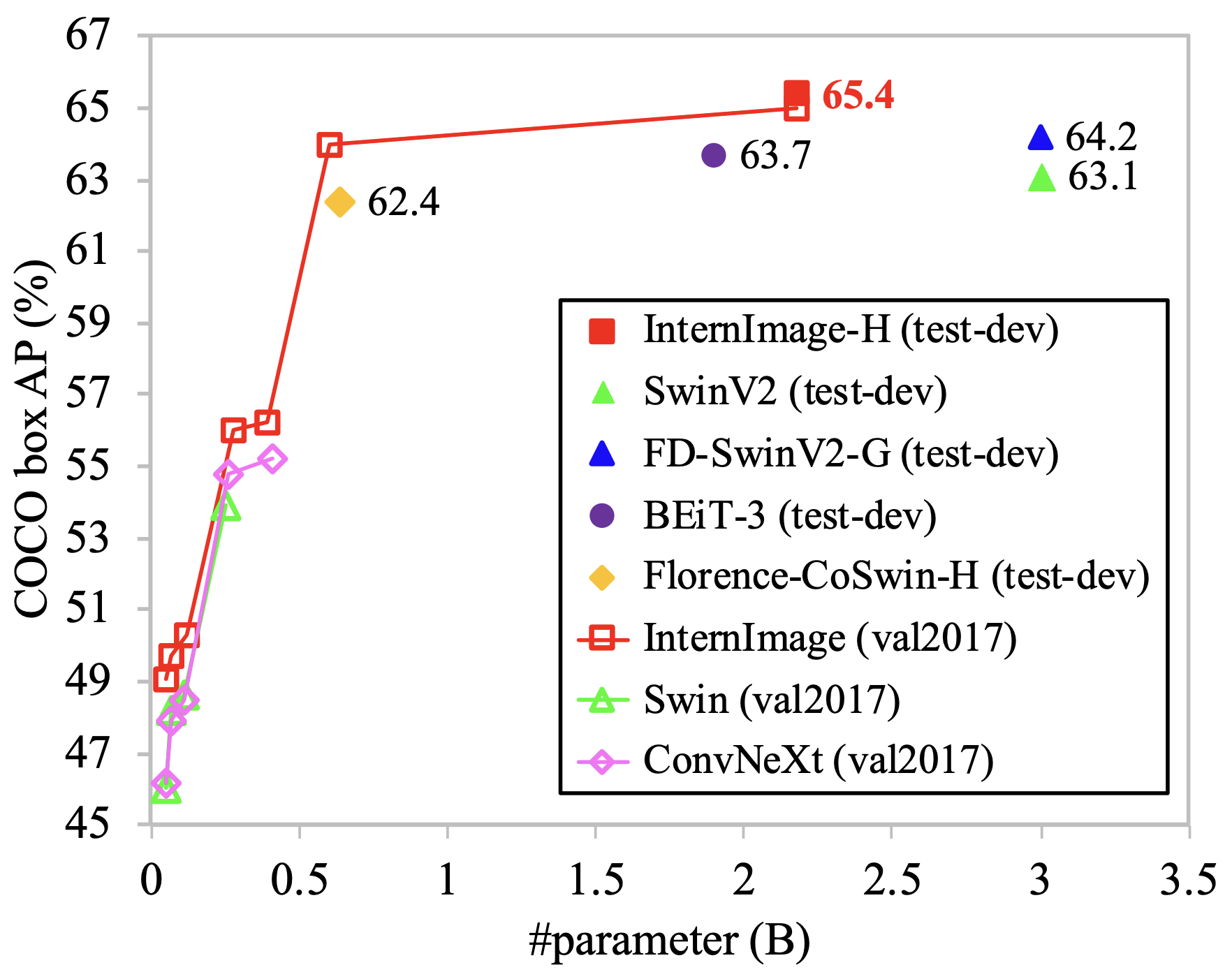
上图显示了基于ViT和CNN的方法在COCO数据集上检测物体的准确性,以及InternImage,它以较少的参数达到了最高的准确性。
自AlexNet以来,CNN一直主宰着计算机视觉领域,但今天,能够在没有归纳偏见的情况下学习大型数据集的视觉转化器(ViT)已经接管了许多任务。CNN和ViT之间的主导地位的差距有两个方面
- ViT可以在没有归纳偏见的情况下学习长距离的依赖关系
- ViT可以通过动态权重获得对输入的适应性依赖。
InternImage通过采用DCN填补了这一空白,能够以较少的参数在大型数据集上进行训练,并取得了较高的准确性,其结果与ImageNet上的ViT相当,在COCO和ADE20K数据集上都是第一名,使CNN与ViT一样,我们也在不同的规模上验证了模型。让我们来看看InternImage。
系统定位
CNN和ViT的主要区别在于是否存在归纳性偏差:CNN假设特征定位是一种偏差,其结构为多层小核的局部特征提取。这种结构允许CNN在相对较小的数据集上进行训练,但一般来说,深度学习模型的高精确度的关键是在大型数据集上进行训练。这应该可以从大型数据集中获得。另一方面,ViT是一个长距离依赖的机制,它可以学习图像中所有局部斑块之间的关系,而不需要假设一个归纳的偏见。虽然在小规模数据上的过度学习是一个挑战,但在大规模数据上学习时,ViT具有压倒性的优势。
另一个区别是权重是动态的还是静态的:CNN在推理过程中用一个独特的训练过的内核进行特征提取,与局部补丁无关。另一方面,ViT在采取Attention之前就将局部斑块线性地投射到Q、K和V上,因此它根据要提取的依赖关系动态地获得权重,并根据推理过程中的输入,提取不同权重的斑块之间的关系。
这两者是弥合ViT和CNN之间差距的关键。最近提出的大规模CNN模型RepLKNet关注长距离依赖和有效接收场之间的关系,并通过纳入大内核实现对大数据集的训练,指出虽然CNN也应该通过分层增加其接收场,但实际的有效接收场并不是很大。通过纳入特征的重新参数化和深度卷积,我们能够成功地训练出具有31x31大胆尺寸的内核。然而,该论文指出,ViT仍有差距,存在许多挑战,如31x31的大参数和复杂的噱头,使其可训练。
所提出的方法,InternImage,用一个小的3x3内核解决了上述两个问题,并被提议作为新的CNN的基础,可以有效地大规模。正如最近关于CNN扩展的研究,它是参照ViT的各种机制建立的。
DCNv3
本文重点介绍了可变形卷积网络(DCNs),以实现长距离依赖和动态权重。优势包括。
- 与普通卷积不同,它可以对长距离的依赖性和输入作出适应性反应。
- 与MHSA不同的是,它继承了归纳性的偏向,因此可以用较少的训练数据和时间来有效地学习它。
- 与MHSA和RepLKNet不同的是,3x3内核是完整的,并且在计算和内存上是高效的。
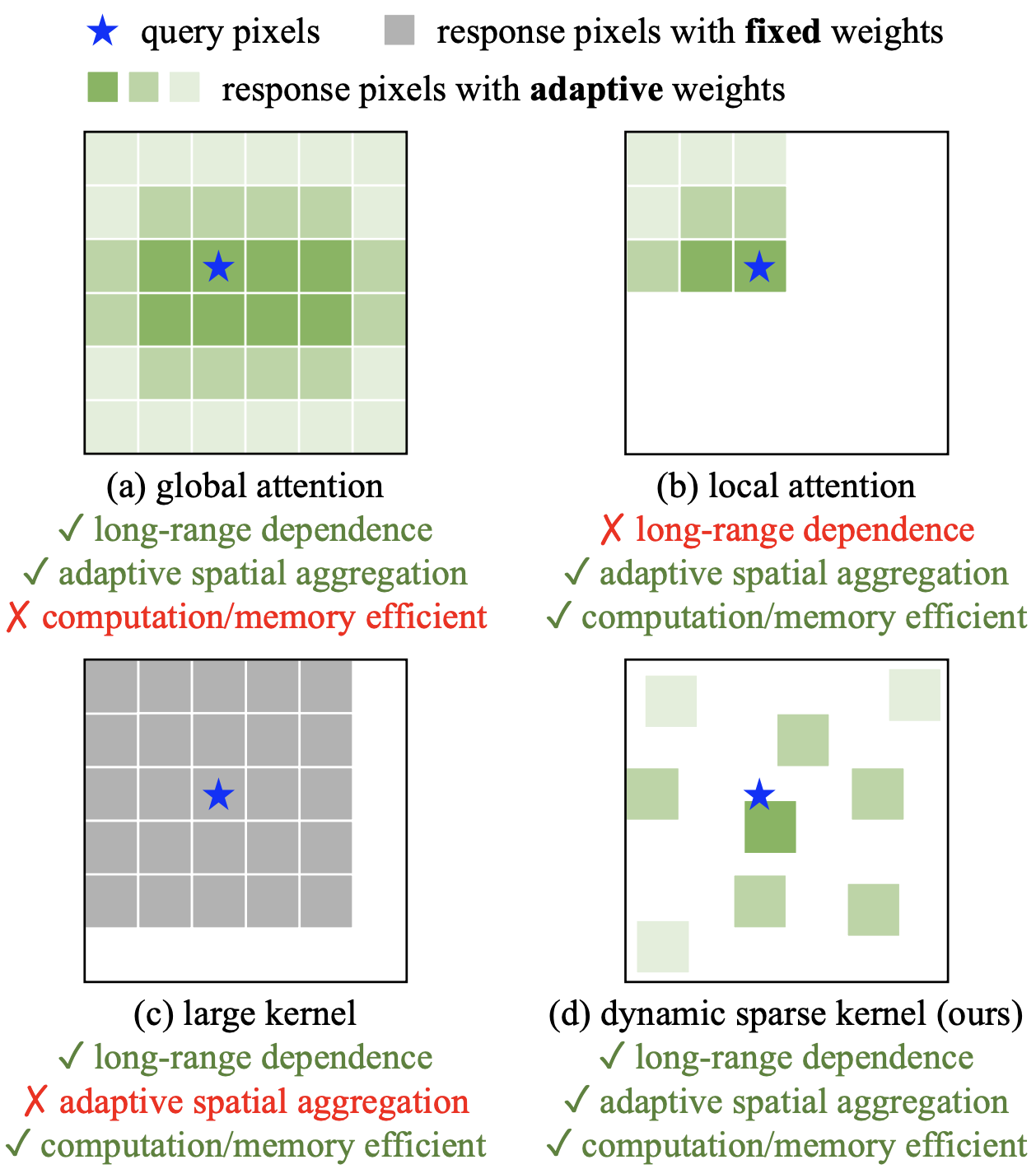
DCN是一个卷积的内核,通常取一个矩形窗口,可以根据数据进行转换。见下图。(a)局部注意和(b)全局注意,(c)大型内核,如RepLKNet,和(d)DCN的计算图像。注意会根据输入动态调整其权重,但全局注意计算成本很高,而且局部关注的问题是不能捕捉到长距离的依赖关系。与Attention相比,大核可降低计算成本,并能捕捉到长距离的关系,但它们不能对输入进行动态处理。然而,(d)中的DCN可以通过3x3核和小窗口的变形来捕捉长距离关系,其变形和权重根据输入而自适应变化,所以它可以实现长距离依赖、动态权重和计算成本的所有条件。
DCNv2
本文提出了DCNv3,是对现有DCNv2的改进,并将其用于InternImage.DCNv2用以下公式表示。
%3D%5Csum_%7Bk%3D1%7D%5EK%20%5Cmathbf%7Bw%7D_k%5Cmathbf%7Bm%7D_k%5Cmathbf%7Bx%7D(p_0%2Bp_k%2B%5CDelta%20p_k)%0A%5Cend%7Balign*%7D&f=c&r=300&m=p&b=f&k=f)
它显示了输入图像x的卷积,它是CxHxW,在坐标p0。K是内核中的参数数,k是内核中的每个方块,pk是图像中的坐标。核心权重wk是一个静态权重,无论输入坐标如何,都有一个共同的值,而DCN有Δp,它可以改变要加权的坐标,还有m,它根据输入对x进行加权。这使得感受野和权重能够根据图片中物体的形状和比例进行适应性改变。该参数应显示在上述方程中,因为它取决于每个坐标p0:通过卷积x,2xHxW的Δp和1xHxW的m被学习并输出。
%3D%5Csum_%7Bk%3D1%7D%5EK%20%5Cmathbf%7Bw%7D_k%5Cmathbf%7Bm%7D(p_0)_k%5Cmathbf%7Bx%7D(p_0%2Bp_k%2B%5CDelta%20p(p_0)_k)%0A%5Cend%7Balign*%7D&f=c&r=300&m=p&b=f&k=f)
DCNv3对此做了如下修改
- 分离为深度卷积和点积卷积,以减少计算成本。
- 通过分组卷积从不同角度看变形和加权
- 在内核单元中对每个m(p0)k进行归一化,以稳定学习。
可分离卷积
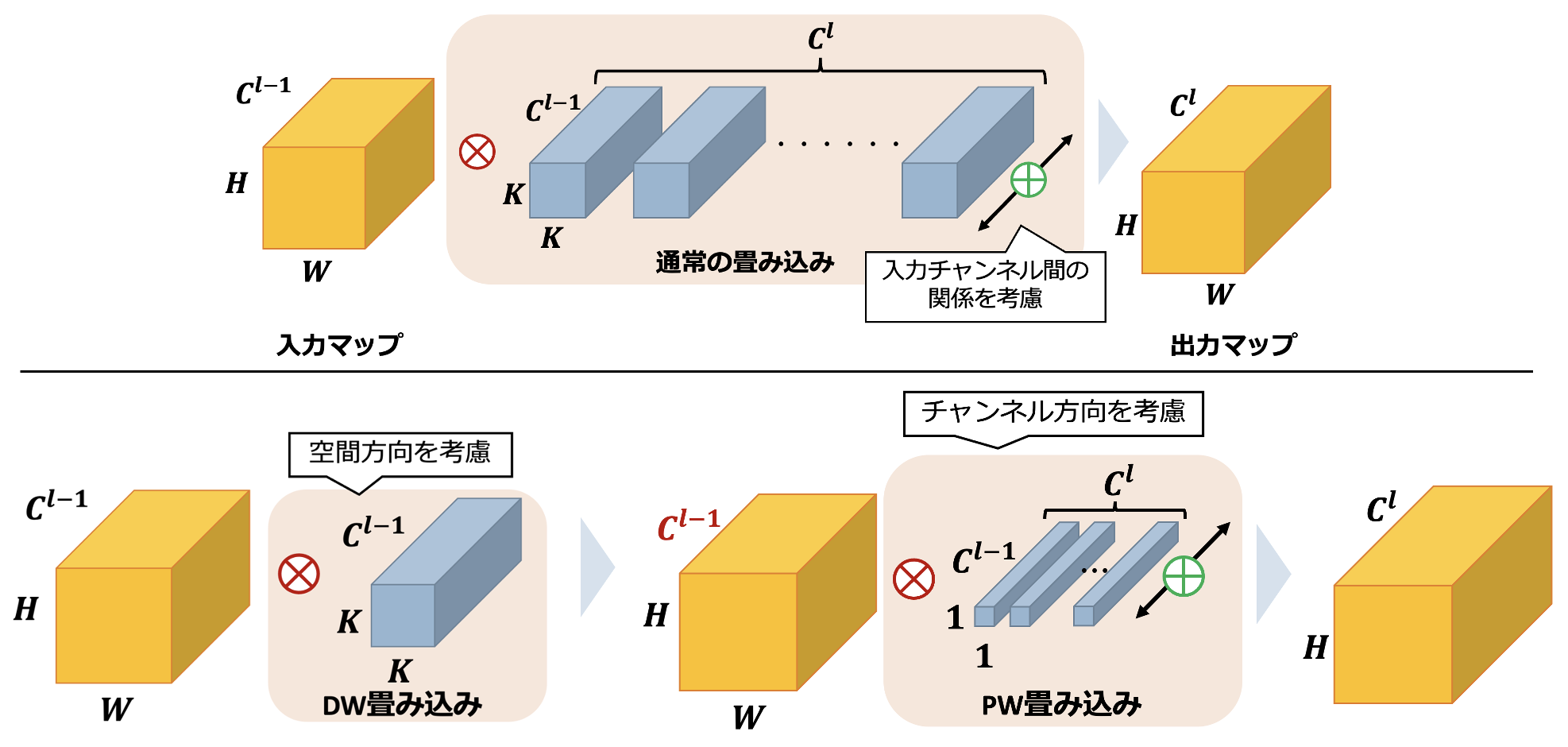
下面是一个关于可分离卷积的说明,其中l是一个层。在正常的卷积中,输入的空间和通道方向被一次性卷积,卷积的计算是针对Cl通道的。相比之下,可分离卷积通过将卷积分离为空间方向的卷积和信道方向的卷积,同时保持输出图的大小,大大减少了参数的数量。这是通过执行深度卷积来实现的,深度卷积只在空间方向上进行卷积,然后是点卷积,只在通道之间加权。
多组卷积
核心权重wk对每个通道有不同的观点,而mk和Δpk由输入图像的位置决定,对所有通道有一个共同的值。DCNv3构建了多个卷积组,每个卷积组有不同的mk和Δpk,以捕捉不同的依赖关系,如多头自-。DCNv3用以下公式表示,每一个G组都是g,通道的数量并没有因为G而增加,但每一组的输入通道似乎被划分为C'=C/G。方程中的xg代表了这一点。
%3D%5Csum_%7Bg%3D1%7D%5EG%5Csum_%7Bk%3D1%7D%5EK%20%5Cmathbf%7Bw%7D_g%5Cmathbf%7Bm%7D(p_0)_%7Bgk%7D%5Cmathbf%7Bx%7D_g(p_0%2Bp_k%2B%5CDelta%20p(p_0)_%7Bgk%7D)%0A%5Cend%7Balign*%7D&f=c&r=300&m=p&b=f&k=f)
核心单位的动态权重m(p0)k的归一化
在DCNv2中,应用sigmoid,使m对每个坐标的值为[0,1]。然而,有人指出,这导致内核中的权重之和在0到K之间变化很大,使学习过程不稳定。因此,DCNv3使用softmax函数,使每个核的权重之和为1。这可以预期会稳定学习。
形象
一旦了解了DCNv3的优势,就可以构建InternImage。与普通CNN不同,InternImage整体上采用了层规范化、FFN和GELU等结构,并参考了ViT结构。该机制被用于各种图像处理任务。这种机制已被证明在各种图像处理任务中是有效的。
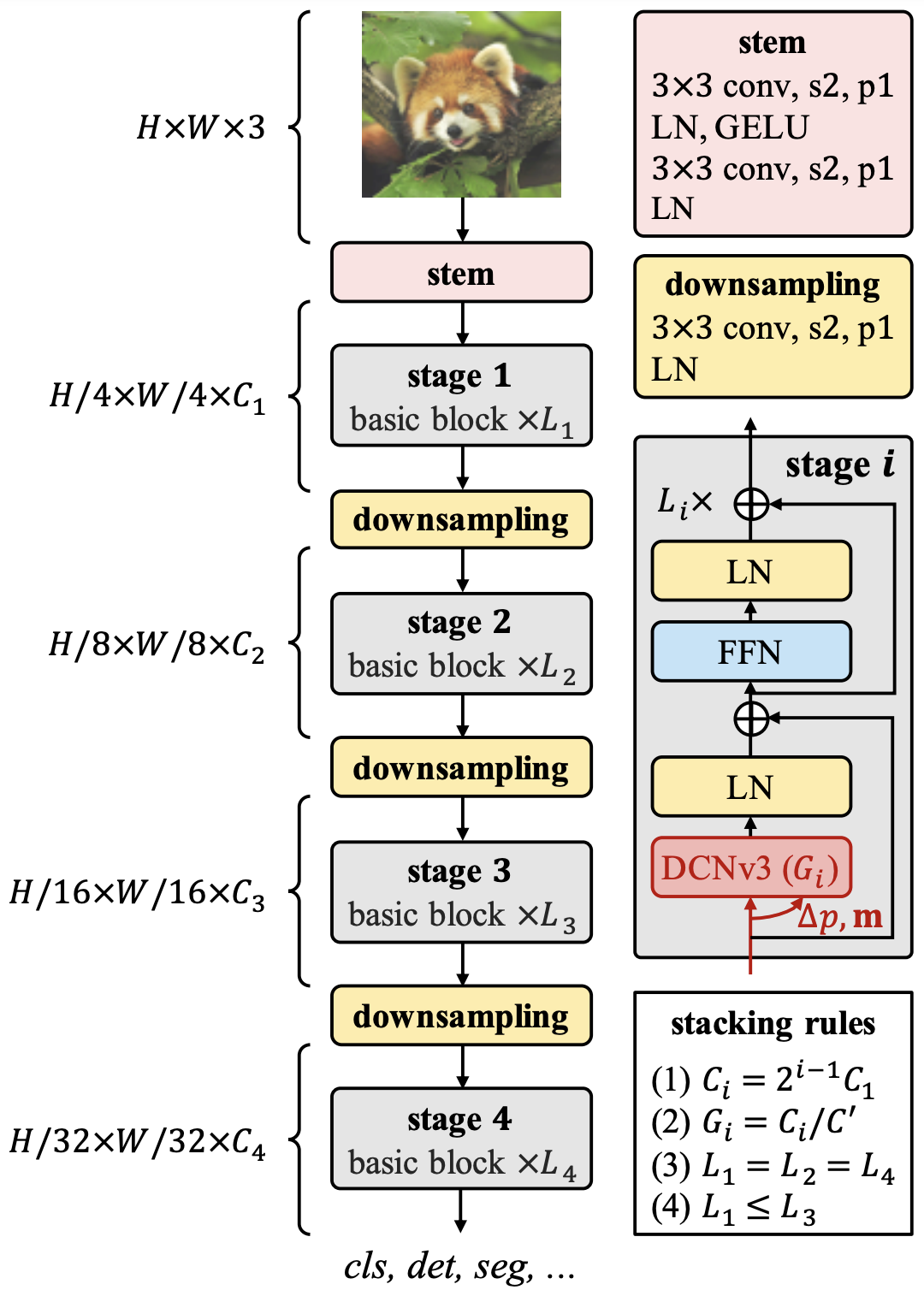
树干、下采样和阶段
Stem是在有DCNv3的阶段之前应用的;Stem由3x3卷积、LN和GELU组成;RepLKNet也有类似的结构,这说明在早期阶段需要详尽地提取局部特征。在这个阶段,分辨率降低了四分之一;下采样,顾名思义,是一个下采样系数为2的块。它被夹在每个阶段之间。阶段包含DCNv3,即InternImage的核心。图中显示了最基本的基本块,它被堆叠在每个Stage之上。
建筑
在Stem之后,Stage和DownSampling被堆叠了四次。在每个阶段i中,有通道数Ci、块数Li和卷积组数Gi。12个超参数的搜索区域太大,所以这里建立了三个规则来确定结构和缩放。
- 从第一阶段的C1开始,通道的数量增加了一倍。
- 组的数量由每个阶段的通道Ci的数量和每个组的通道C'的数量决定。
- AABA "模式,第1、2、4阶段每阶段的块数相同,第3阶段的数值较大
这样,模型的超参数就由(C1,C',L1,L3)决定。
缩放比例
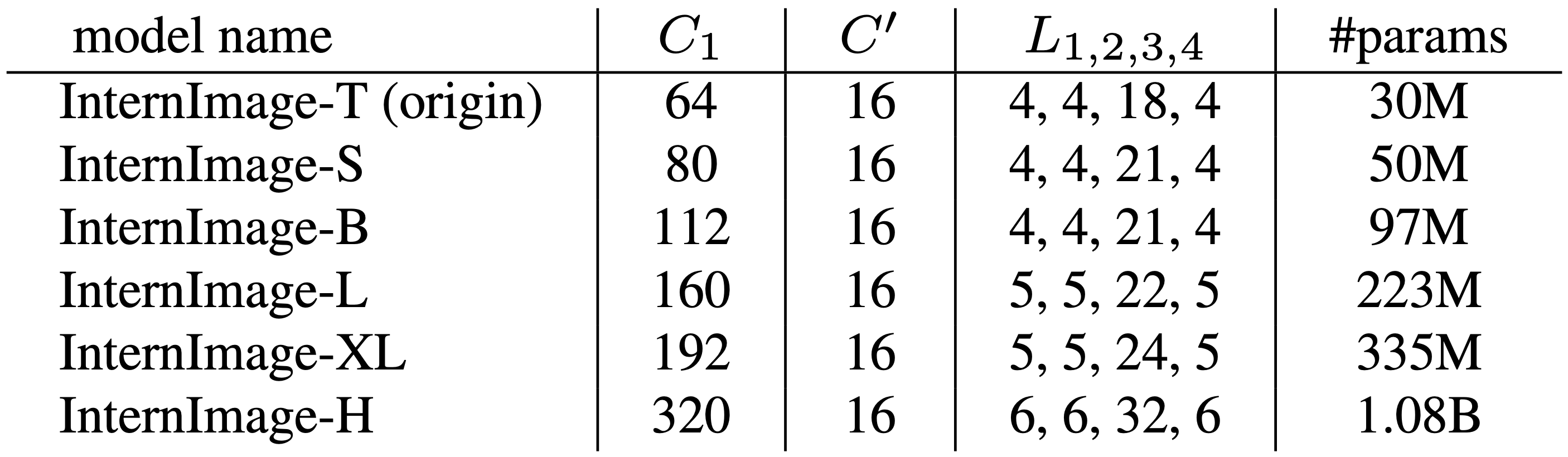
用(C1,C',L1,L3)=(64,16,4,18)的总共3000万个训练参数作为InternImage-T的模型规模。深度D(3xL1+L3)和通道C1的数量增加了α=1.09,β=1.36,Φ。
![]()
由此产生的InternImage标度如下表所示。-T到-XL的计算复杂度与ConvNext相似,而最大的规模,InternImage-H,有10亿个参数。
实验
实验证明了ImageNet图像分类的优越性,COCO物体检测使用它作为预训练和ADE20K分割实验。在每个实验中,基于CNN和基于VIT的SoTA模型在不同规模上进行了比较。据说消融的情况包括在补充材料中,所以想知道详细机制的优越性的人也应该看一看。
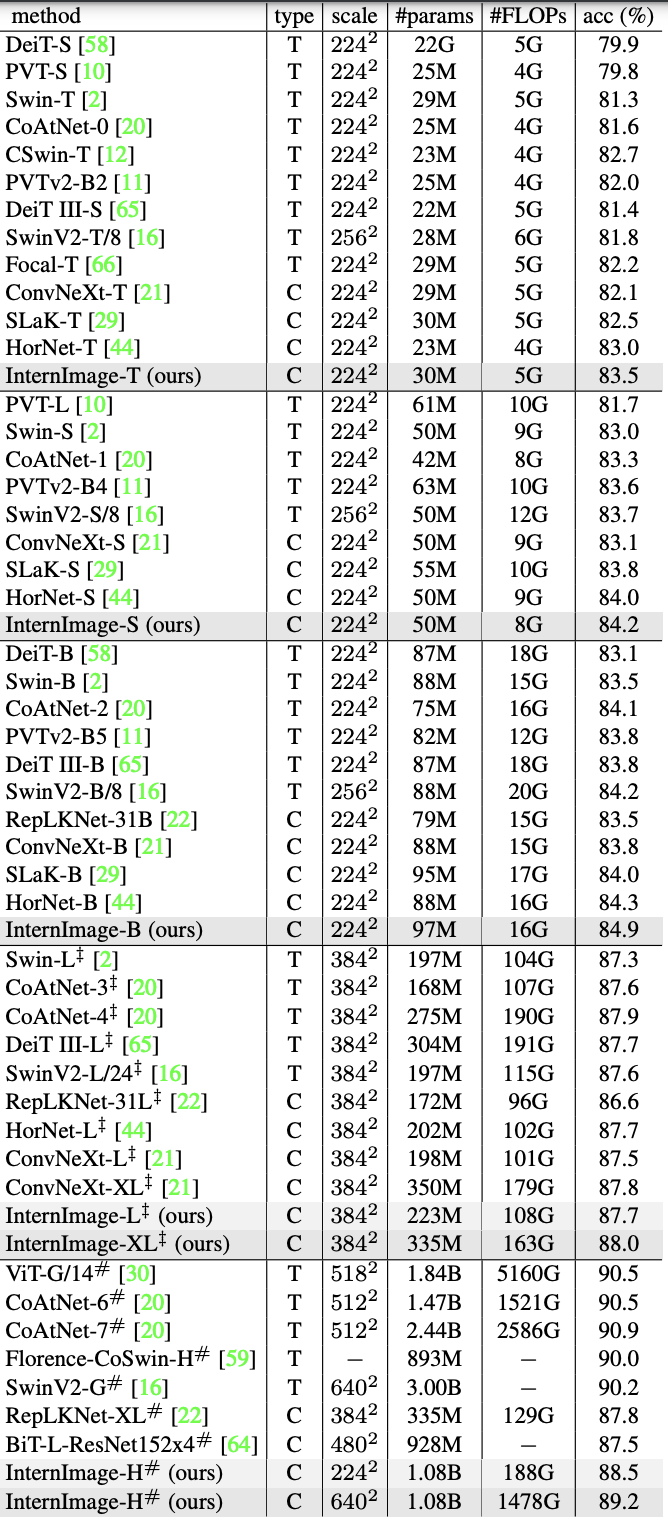
分类任务(ImageNet)。
为了确保在被比较的模型的规模上进行公平的比较,-T/S/B是以300个历时对ImageNet-1K的130万张图像进行微调,-L/XL是以30个历时对ImageNet-22K的1420万张图像进行微调,这些图像是以90个历时进行预训练。-L/XL在30个历时中进行了微调。对于大规模的-H,采用了M3I预训练。这整合了有监督、弱监督和无监督的预训练,只需一个阶段的预训练就能获得理想的参数,共训练了4.27亿张图像(Laion-400M、YFCC-15M和CC12M),经过30个epochs。在此基础上,对ImageNet-22K和-1K分别进行了30个epochs的微调。
结果如下表所示,其中类型表示ViT(T)或CNN(C),规模表示输入大小。在每个模型的规模上,这些模型都取得了与基于CNN的ViT SoTA模型相似或更好的准确率,其中InternImage-T以83.5%的成绩名列榜首,InternImage-S/B甚至超过了混合型ViT CoAtNet-1。InternImage-XL和InternImage-H分别取得了88.0%和89.2%的成绩,比在相同的大数据集上训练的传统CNN模型有所提高,与大规模ViT的SoTA模型的差距缩小到1.0左右。这一结果证明了前面定义的大数据集上的扩展和训练的有效性。
物体检测(COCO)。
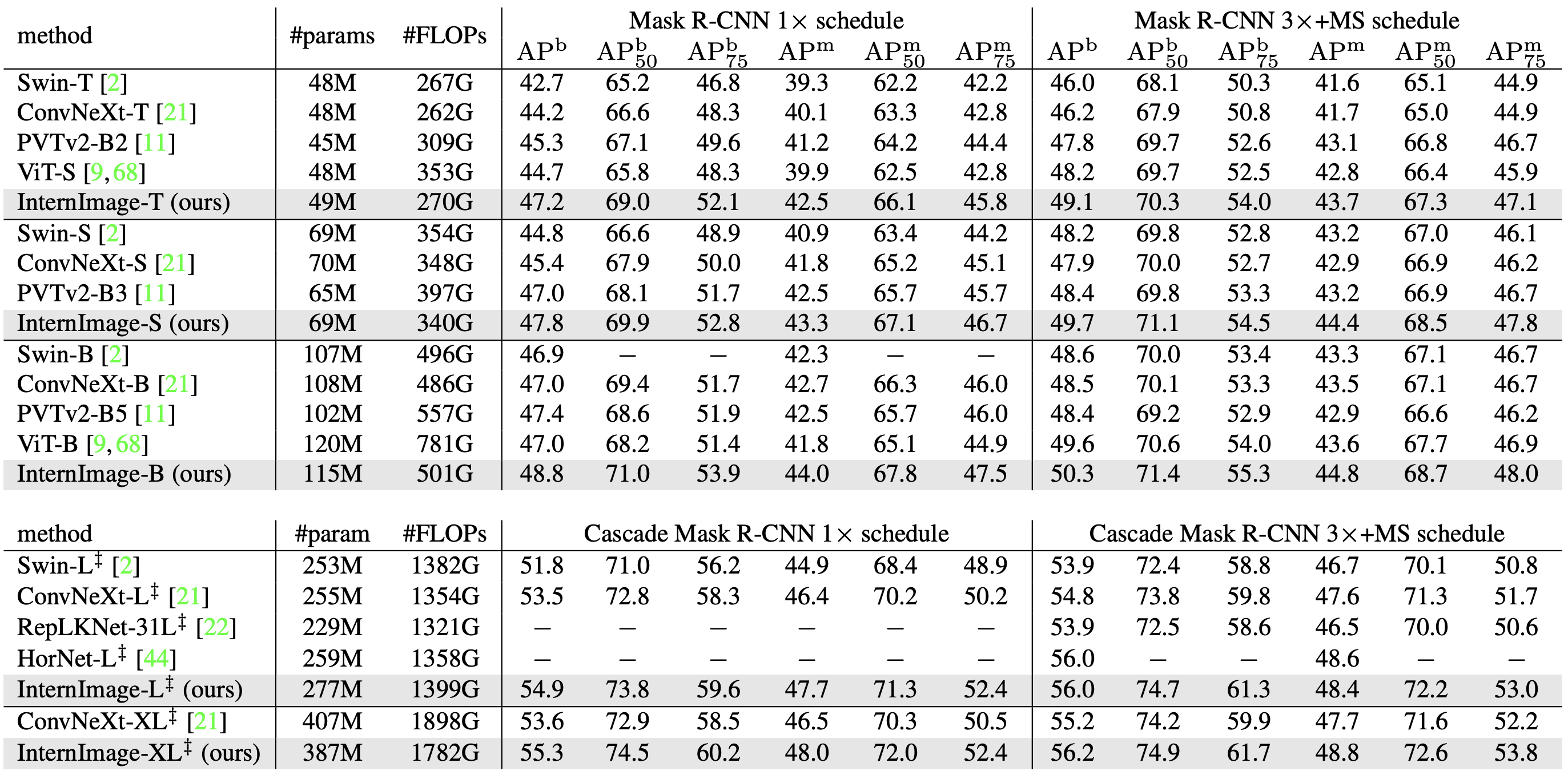
COCO进行了两个实验来验证准确性:一个是比较以Mask R-CNN和Cascade Mask R-CNN为检测器的骨干网,另一个是比较每个骨干网的不同检测器的骨干网。每个人都在对预先训练好的ImageNet进行微调。
屏蔽R-CNN/级联屏蔽R-CNN
下表比较了Mask R-CNN和Cascade Mask R-CNN分别训练12个epochs(1x)和32个epochs(3x)的准确性。3x训练是在多尺度下训练的。
Box-AP(APb):在Mask R-CN中,InternImage在相当数量的参数下明显优于InternImage;在1x中,InternImage-T实现的APb比Swin-T高4.5,比ConvNeXt-T高3.0;在3x训练的CascadeMask R-CNN,InternImage-XL的APb达到56.2,比ConvNeXt-XL高1.0。
mask-AP(APm):对于1x训练,InternImage-T取得了42.5的成绩,超过了SwinT和ConvNeXt;InternImage-XL的Cascade Mask R-CN取得了48.8的APm的最高精度。
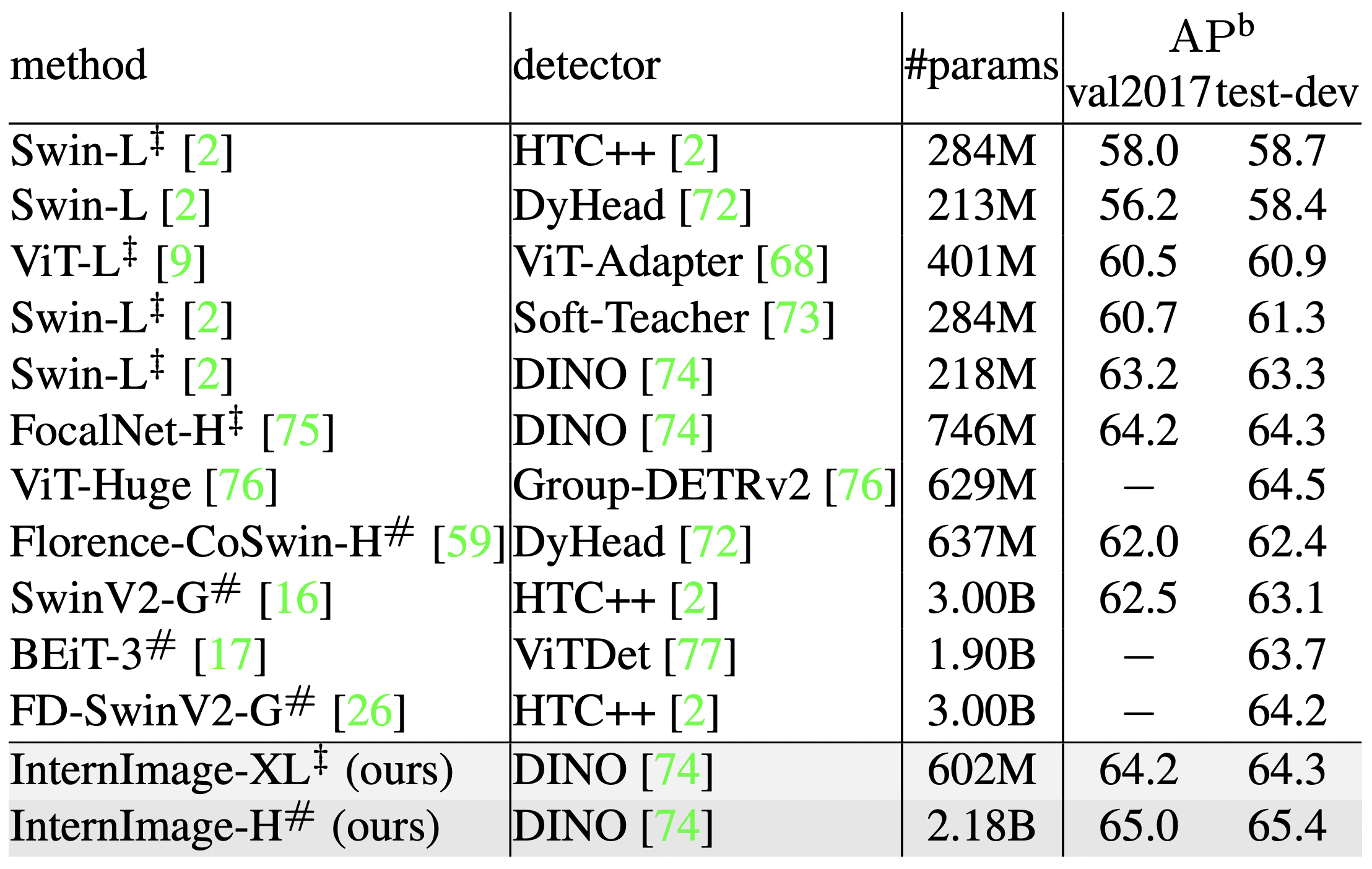
SoTA模式
为了进一步提高精确度,采用了各种检测器,并与SoTA模型的精确度进行比较。在这个验证中,Objects365数据集被训练了26个epochs,COCO被训练了12个epochs。因此,基于DINO检测器的InternImage-XL/H在COCO数据集val2017和test-dev上达到了65.0APb和65.4APb的最高精度。此外,这是在比现有的SoTA模型少27%的参数下实现的,表明InternImage对检测任务也很有效。
对象检测(COCO)语义分割(ADE20K)。
在ImageNet预训练以及检测的基础上,UperNet被用作ADE20K分割任务的模型。InternImage-H被用作更高级模型Mask2Former的骨干。
因此,InternImage+UperNet的表现一直优于现有方法。在参数和FLOPs数量几乎相同的情况下,InternImage-B达到了50.8 mIoU,超过了ConvNeXt-B和RepLKNet-31B等强大的CNN模型。在多尺度下,InternImage-H也取得了62.9 mIoU的成绩,是迄今为止最高的写作精度,超过了排名第二的BEiT-3。
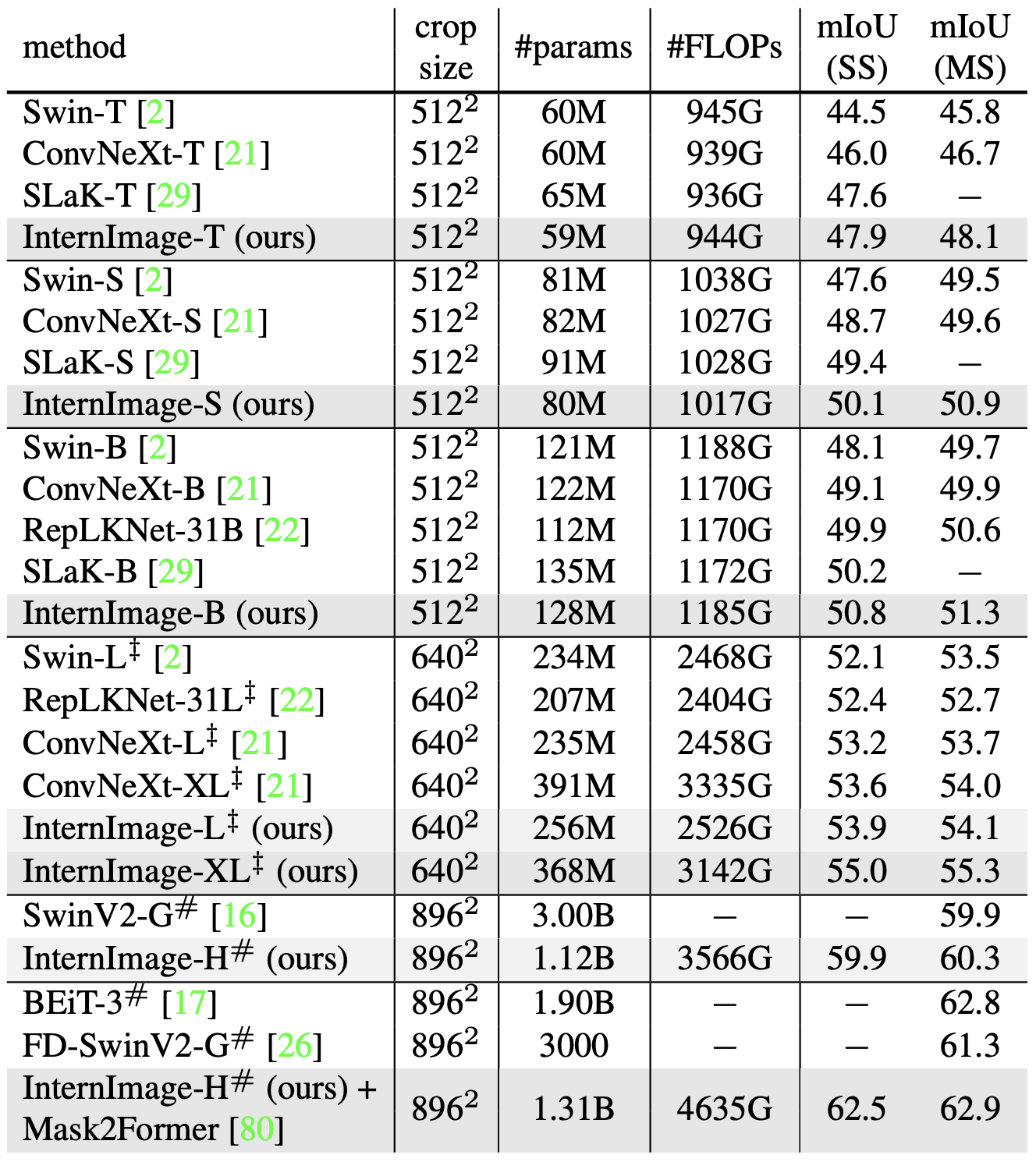
这些结果表明,基于CNN的基础设施模型可以从大型数据集中获益,并且非常接近于基于ViT的模型。
摘要
在这篇文章中,我们介绍了InternImage,一个大规模的CNN模型,其性能优于ViT。在ImageNet、COCO、ADE20K和广泛的基准上的实验表明,InternImage可以达到与在大规模数据上训练的ViT相同或更好的准确性。表明,CNN作为大规模模型的一种选择,具有很大的潜力。作为一个挑战,基于DCN的方法是处理量很大的。未来的发展是值得期待的。



与本文相关的类别






