![Brain2Music] 根据大脑信息自动生成音乐。](https://aisholar.s3.ap-northeast-1.amazonaws.com/media/December2023/brain2music.png)
Brain2Music] 根据大脑信息自动生成音乐。
三个要点
✔️ 基于人脑活动的自动音乐生成
✔️ 听音乐时人脑活动的 fMRI 测量
✔️ 使用 MusicLM 架构
Brain2Music: Reconstructing Music from Human Brain Activity
written by Timo I. Denk, Yu Takagi, Takuya Matsuyama, Andrea Agostinelli, Tomoya Nakai, Christian Frank, Shinji Nishimoto
(Submitted on 20 Jul 2023)
Comments: Preprint; 21 pages; supplementary material: this https URL
Subjects: Neurons and Cognition (q-bio.NC); Machine Learning (cs.LG); Sound (cs.SD); Audio and Speech Processing (eess.AS)
code:
本文所使用的图片要么来自论文、介绍性幻灯片,要么是参考这些图片制作的。
介绍
这项研究由谷歌、大阪大学和其他机构合作进行,开发出了 "基于大脑活动生成音乐的模型"--Brain2Music。生成的音乐可在以下 GitHub 页面上聆听。
https://google-research.github.io/seanet/brain2music/
具体来说,该技术利用 fMRI(功能磁共振成像)测量 "听音乐的受试者的大脑活动",并利用大脑活动数据生成音乐。这项研究很可能成为未来开发可输出想象旋律的模型以及大脑如何解读音乐的垫脚石。

顺便提一下,本研究中的 Brain2Music 使用了谷歌的文本到音乐模型 MusicLM。首先,让我们简要回顾一下 MusicLM。
MusicLM 概览
MusicLM 是一个文本到音乐模型,它将此类文本作为输入,并根据该文本生成音乐。例如,如果您输入 "小提琴独奏嘻哈歌曲 "的提示,如下图所示,它将生成 "小提琴独奏嘻哈歌曲 "的音乐。

https://arxiv.org/abs/2301.11325
MusicLM 生成音乐的步骤如下
- 沐兰音乐编码器生成的MT
- 在MT的限制下,使用仅解码器变压器生成 S
- 在MT 和S 的限制下,用纯解码器变压器生成 A
- A 信号通过 SoundStream(神经声码器)解码器。
下文还给出了上述符号的含义。
- MA:由沐兰音乐编码器获得的代币
- MT:通过 MuLan 文本编码器获得的令牌
- S:由 w2v-BERT 获得的代表 "音乐意义 "的标记
- A: 表示 SoundStream 获取的 "音频 "的标记
这里的关键是名为 "MuLan "的模块。这是一个文本-音乐对比学习模型。MuLan 的结构如下图所示。
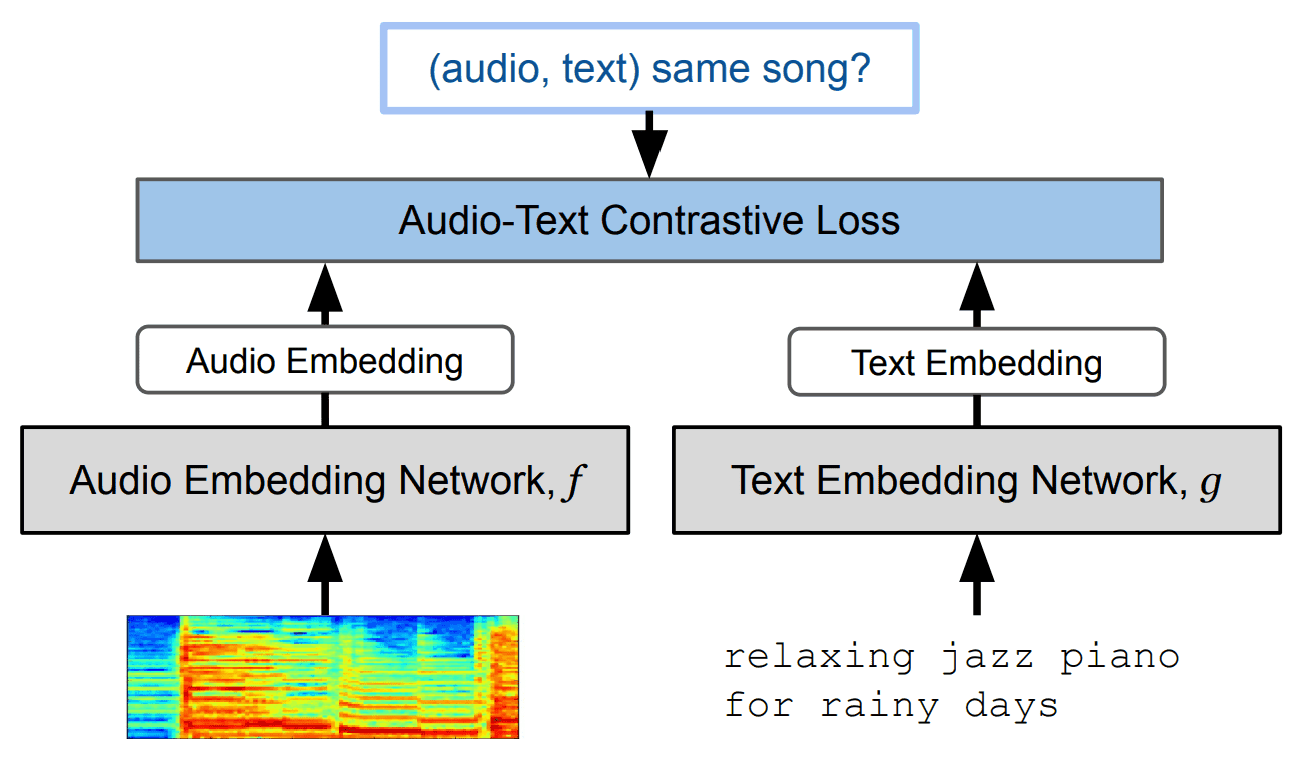
https://arxiv.org/abs/2208.12415
当输入文本时,该模型可用于生成 "与文本内容最匹配的音乐表示"。在本研究中,"BERT "被用作 MuLan 文本编码器,"ResNet-50 "被用作音频编码器。
在音频编码器中使用图像模型的原因是,频谱图图像数据被用作音乐数据,需要进行图像处理。
利用大脑信息创作音乐的方法
Brain2Music 的结构与 MusicLM 几乎相同;它与 MusicLM 的不同之处在于,它使用 fMRI 获取的大脑信息作为输入。
首先,让我们来看看 fMRI。
什么是 fMRI(功能磁共振成像)?
fMRI 是一种通过检测大脑血流变化来无创观察大脑活动的技术。它使用一种取决于血液中氧含量的信号(BOLD 信号)来显示大脑活动的空间分布。

fMRI 广泛用于研究与人类情绪和认知功能相关的大脑区域的活动。
fMRI 在研究对音乐的反应方面发挥了特别重要的作用。音乐会触发大脑的多种处理过程,并被用于情绪反应、记忆和注意力等多个领域的研究。这使我们能够探索大脑活动与音乐感知之间的联系,并更深入地了解大脑对音乐的反应。
数据集
本研究使用的数据集是经过预处理的 "音乐流派神经成像数据集",来自 Nakai 等人(2022 年)的研究成果。该数据集包含随机采样和播放 10 种不同音乐流派(蓝调、古典、乡村、迪斯科、嘻哈、爵士、金属、流行、雷鬼和摇滚)时的大脑活动数据。
最后,480 个示例用于训练,60 个示例用于测试。
大脑音乐架构
Brain2Music 架构如下图所示。
新方法利用 fMRI 技术捕捉受试者在听音乐时的大脑活动,并利用这些数据预测音乐的嵌入情况,进一步对其进行重构。
音乐生成过程如下
- 接收 fMRI 响应 R 作为输入。
- 用 R 作为解释变量预测沐兰的音乐嵌入。
- 基于音乐嵌入的音乐搜索或音乐生成
首先,它将 fMRI 反应 R 作为输入,并预测 MuLan 音乐嵌入。如果音乐嵌入为 T,则通过 L2- 规则化回归预测 T=RW(W 为训练参数)。
音乐是通过上述用于音乐检索或音乐生成的 T 根据大脑信息创作出来的。
・音乐搜索
在音乐检索方面,预先计算了音乐数据库中 106,574 首歌曲(前 15 秒)的音乐嵌入。然后,它预测之前预测的 T 与音乐数据库中音乐嵌入之间的相似度,并从数据库中提取相似度最高的歌曲。
・音乐世代
音乐生成使用 T,通过以下基于 MusicLM 的架构生成音乐。

这与传统的 MusicLM 几乎相同。不同之处在于,MuLan 嵌入 T(图中的 "High-level (MuLan)")是通过 fMRI 反应获得的。
评估测试
音乐嵌入预测的准确性比较
如方法部分所述,从 fMRI 数据生成音乐需要一个中间步骤,即预测音乐嵌入。为此,我们进行了对比实验,以确定以下四种嵌入式中哪种效果更好。
- SoundStream-avg
- w2v-bert-avg
- MuLantext.
- MuLanmusic.
在本实验中,通过回归方程 T=RW 根据 fMRI 预测了上述每种嵌入,并比较了它们的性能。结果如下

结果表明,MuLanmusic的性能最佳。因此,Brain2Music 将使用 fMRI 进行 "MuLanmusic预测"。
音乐搜索与音乐生成
下图显示了供受试者聆听的真实音乐和检索/生成音乐的频谱图图像。简而言之,真实音乐和检索/生成音乐的频谱图应该是相似的。

下图显示了利用 fMRI 数据对音乐再现准确度的定量比较。它评估了随机预测(Chance)和理想预测(Oracle)之间的实际预测性能。

每个 a~c 表示以下内容。
- a: 不同音乐嵌入的准确性。
- b:原始音乐与重建音乐的相似度。
- c: 各流派的准确性。
从上图我们可以看出
- 使用 MuLan 作为编码器会更加精确。
- MusicLM 生成的音乐更准确。
- Brain2Music 能以相同的准确度生成所有类型的音乐。
通过音乐嵌入进行 fMRI 信号预测任务
任务是使用 MusicLM 中出现的不同音乐嵌入来预测 fMRI 信号,并比较其准确性。这里使用的是带有 L2 正则化的回归模型。
・MuLanmusic vs w2v-BERT-avg
首先,建立编码模型来预测音乐嵌入(MuLanmusic和 w2v-BERT-avg)的体素活动(大脑活动),并比较这些活动在人脑中的不同表现形式。
MuLanmusic和 w2v-BERT-avg 模型都是将音频作为输入,并输出代表音乐含义的嵌入。
上述结果表明,两个模型都预测了相同大脑区域的活动。显示活动的区域与听觉皮层相对应。
因此,这两种嵌入方式在听觉皮层中都有一定程度的相关性。
・MuLanmusic vs MuLantext
然后,我们建立了一个编码模型,利用音乐衍生的 MuLanmusic和文本衍生的 MuLantextembedding 预测 fMRI 信号。要获得 MuLan 文本嵌入,需要将数据集中每首音乐对应的文本标题输入 MuLan 文本编码器。

上述结果再次表明,在这两个模型中,预测听觉皮层都会出现反应。
推广到其他流派
这里测试的是模型对 "训练中未使用的音乐类型 "的泛化程度。下图显示了使用所有数据("完整")训练出的模型的准确度,以及根据训练数据中未包含的音乐类型训练出的模型的准确度。

比较结果表明,该模型对训练过程中未使用的音乐类型具有一定的泛化性能。
摘要
本研究将以下三个问题确定为挑战
- 使用线性回归从 fMRI 数据中提取信息量的限制。
- 音乐嵌入(MuLan)所能捕捉的局限性
- 音乐搜索或生成功能的局限性。
这项研究评估了音乐的声学特征在人脑中的表现位置和程度。
未来,纯粹的想象力或许可以产生音乐。如果这种技术得以实现,例如可以
- 体现想象旋律的新时代音乐平台
- 能捕捉个人音乐感觉的服务,支持对音乐更感性的理解。
从生物学角度研究音乐的产生,是一个值得关注的领域。



与本文相关的类别
![[Libra] 利用解耦视觉系统对大规模](https://aisholar.s3.ap-northeast-1.amazonaws.com/media/February2025/libra-520x300.png)




