我们想从人类的运动视频中学习通用奖励,我们可以用它来训练我们的机器人!
三个要点
✔️通过使用大型和多样化的人类视频集,学习具有高泛化性能的奖励函数
✔️使用学习到的奖励函数解决任务,即使是未知的任务和环境。
✔️在与真实机器人的实验中表现出高成功率
Learning Generalizable RObotic Reward Functions from "In-The-Wild" Human Videos
written by Annie S. Cgeb,Suraj Nair ,Chelsea Finn,
(Submitted on 31 Nar 2021)
Comments: Accepted by RSS 2021.
Subjects: Robotcis (cs.RO), Artificial Intelligence (cs.AI), Computer Vision and Pattern Recognition (cs.CV), Machine Learning (cs.LG)
code:
本文所使用的图片要么来自论文、介绍性幻灯片,要么是参考这些图片制作的 。
简介
为了让机器人能够在各种环境中解决各种任务,必须要有任务成功的指标或奖励,这对计划和强化学习来说是必要的。特别是,在现实世界中,奖励函数需要对不同的任务、对象和环境具有通用性,只使用来自机载传感器的信息,如RGB图像。不是在机器人领域,而是在计算机视觉和自然语言等领域,通过使用大型和多样化的数据集,已经实现了一些通用性。然而,在机器人领域,这种大型和多样化的数据集是昂贵的,而且难以收集。在本文中,我们介绍了一种名为 "领域诊断视频判别器"(DVD)的方法,该方法通过充分利用人类解决任务的视频,如YouTube上的视频,学习一种能够应对未知任务的奖励函数。该方法被称为领域诊断视频分辨器(DVD)。我们已经证明,这种方法可以使用相对较大的人类解决任务的数据集和少量的机器人数据来估计未知任务和环境的奖励。在下一节,我们将更详细地解释该方法的工作原理。
方法
首先,人类的数据与机器人的观察空间有很大的不同,当然,机器人和人类在外观上也有很大的不同。不仅如此,人类和机器人的行动空间也非常不同,不可能将所有的人类行动转化为机器人行动。此外,所谓的 "野生 "数据,如在网络上发现的数据,有不同的观点和背景,而且有噪音。然而,我们的动机仍然是,我们可以很容易地获得大量的数据,我们想用它来学习机器人的奖励函数。
那么,我们如何使用人类的数据呢?这个想法是,给定两个视频,经过训练的分类器应该能够分辨出这两个视频是在解决同一个任务还是不同的任务。通过使用大量人类视频和少量机器人视频上的活动标签,我们可以了解两个视频是否在解决同一个任务,即使存在视觉领域的差距。这种方法被称为领域诊断视频判别器(DVD),是一种具有广泛用途的简单方法。一旦DVD经过训练,一个输入是人类对要解决的任务的演示,另一部分是机器人的行动视频,两个视频之间的相似度得分被用来判断任务是否成功。下图显示了整个过程。下图说明了整个过程。
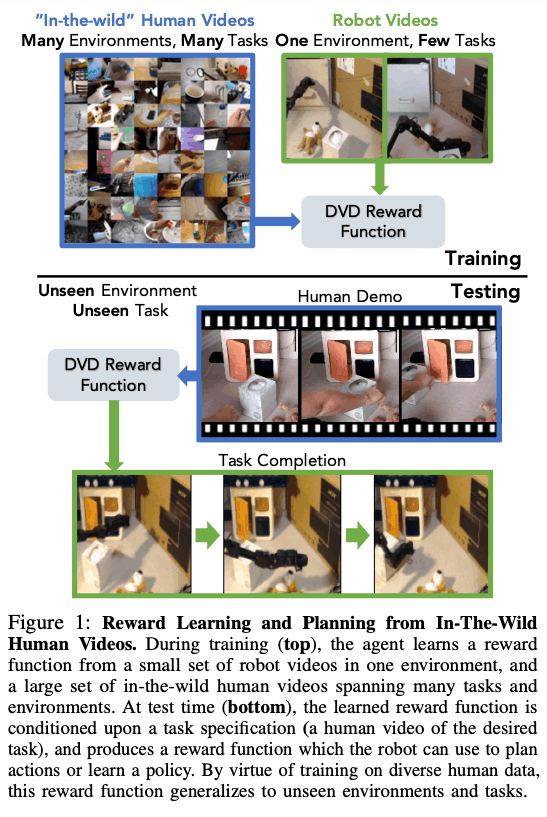
领域可知的视频鉴别器
现在我们将进一步详述有关DVD的方法。其基本思想是学习一个奖励函数$mathcal{R}_{theta}$,该函数可以捕捉两个视频的功能相似性(即它们是否在执行相同的任务),一个是关于任务$mathcal{T}_{i}$ $d_{i}$,另一个是关于任务$mathcal{T}_{j}$ d_{j}$。给定两个视频$mathcal{R}_{\theta}$和两个视频$d_{j}$,任务是学习一个奖励函数$mathcal{R}_{\theta}$,它可以捕捉两个视频之间的功能相似性(无论它们是否在执行相同的任务)。如果人类视频的数据集和少量机器人视频的数据集分别为$mathcal{D}^{h}$和$mathcal{D}^{r}$,那么这两个视频可以是属于$D^{h}$或者$D^{r}$的视频。然后,如下图所示,每个视频都有一个行动标签,它告诉你哪个视频属于哪个任务。

$mathcal{R}_{theta}$的输出代表了两个视频在任务层面的相似度得分,我们学习使用平均交叉熵损失来最小化成对视频的以下目标函数
$$ \mathcal{J}(\theta)=\mathbb{E}_{mathcal{D}^{h} \cup \mathcal{D}^{r}}[\log (\mathcal{R}_{theta}(d_{i}, d_{i}^{/prime}))+log (1-\logmathcal{R}_{theta}(d_{i}, d_{j})] $$
关于DVD的实施
要学习的奖励函数$mathcal{R}_{theta}$为
$$ \mathcal{R}_{theta}(d_{i}, d_{j}) = f_{sim}(f_{enc}(d_{i}), f_{enc}(d_{j}); \theta) $$
而$h=f_{enc}$是预先训练好的视频编码器,由参数$theta$代表的全连接神经网络$f_{sim}(h_{i}, h_{j}; \theta)$被训练为能够估计视频编码$h_{i}$和$h_{j}$是否相同。这里,视频编码器$f_{enc}$将视频放入潜伏空间,二元分类器$f_{sim}$接收这些视频编码,并如上一节所述进行训练。在这里,由于机器人和人类视频的数量不同,我们试图平衡它们,使每批$(d_{i}, d_{i}', d_{j})$有50%的机会是机器人视频。
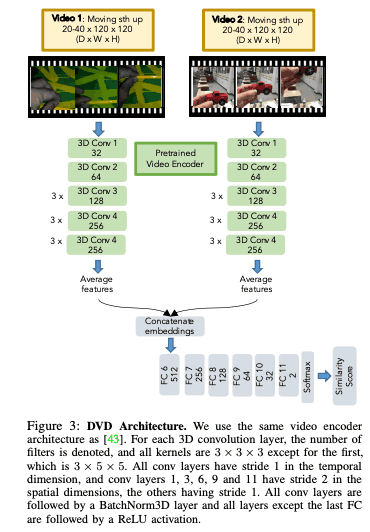
用DVD执行任务
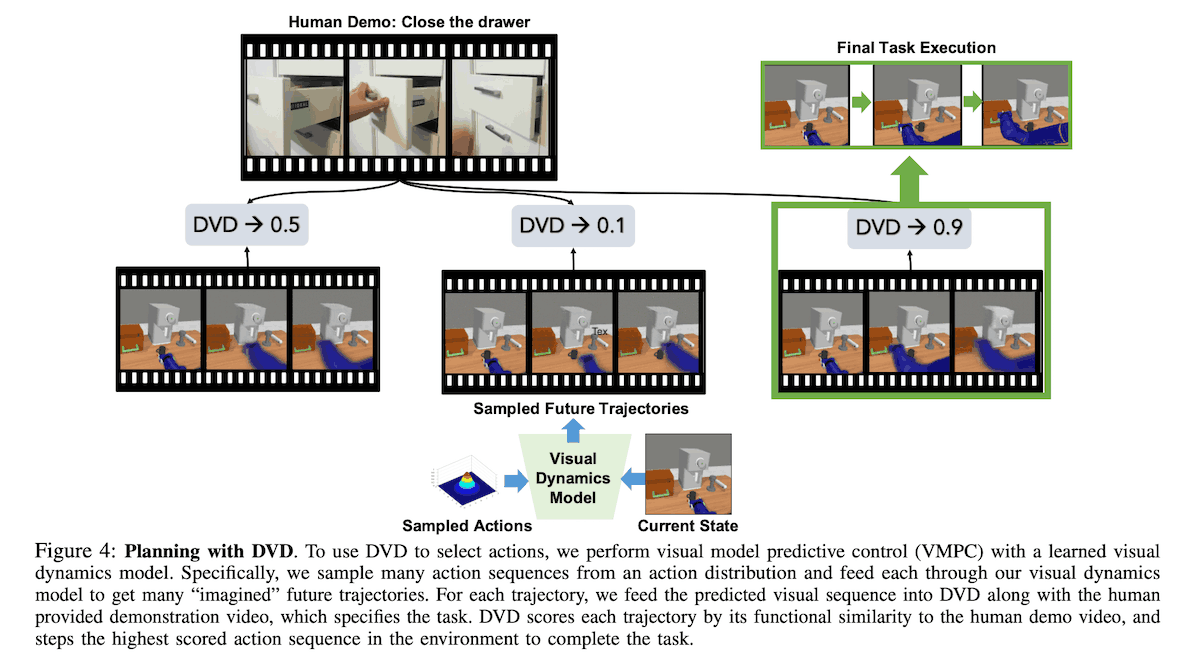
那么,我们如何使用学到的奖励函数$R_{theta}$来解决任务?这个奖励函数可以与无模型RL或基于模型的RL相结合。在本文中,我们使用了一种叫做视觉模型预测控制的方法,即用经过训练的视觉动力学模型来规划机器人的行动。在任务执行时,人类对要解决的任务进行演示,$d_{i}$,机器人的行动被优化为与演示相似。
现在让我们更具体一点。首先,我们使用SV2P模型训练一个动作条件的视频预测模型$p_{phi\}(s_{t+1:t+H}|s_{t}, a_{t:t+H})$。然后,使用交叉熵法(CEM)和学习到的动力学模型$p_{phi}$,选择行动来最大化与给定示范的相似度。换句话说,长度为H的动作序列的轨迹${s_{t+1:t+H}}^{g}$被收集用于G的滚动,并通过学习的动力学模型获得图像。然后将这些轨迹与演示进行比较,选择相似度最高的轨迹。
实验
在本文中,为了研究DVD是否有效地利用人类视频数据来提高概括性能,我们进行了实验,证实了以下几点
- DVD是否可以推广到新的环境
- DVD是否能普及到新的任务
- 由人类演示其中一张DVD的归纳是否比其他方法更有效
- 对于真正的机器人,奖励是否可以估计?
前三个任务是像下面左边这样的模拟,是基于学习环境的,但测试环境1的颜色不同,测试环境2的颜色和视角不同,测试环境3的颜色、视角和物体顺序不同。我们准备了三项任务:(1)关闭抽屉,(2)将水龙头转到右边,(3)将杯子从摄像头推到咖啡机上。
我们使用一个名为Something-V2数据集的人类数据集进行了实验,该数据集共包含174个类别和220,837个视频。这个数据集包含了各种各样的对象,这些对象被不同的行为操纵到不同的环境和对象。在这个实验中,我们使用了最多15个不同的人类任务的视频,每个任务有853-3170个数据点。我们还假设,机器人得到了120个关于这三项任务的视频演示。
真机上的实验是用WidowX200机器人进行的。使用与模拟中基本相同的设置,该实验涉及两个学习任务,每个任务有80个机器人和一个DVD被人类视频学习。学习环境是指有存放文件的橱柜的环境,如下图右侧所示。在测试环境中,它被一套玩具厨房所取代。学习任务是 "关闭东西 "和 "从左到右推东西",测试任务是 "关闭东西"(已知任务)和 "从右到左推东西"(未知任务)。测试任务是 "关闭东西"(已知任务)和 "从右到左推东西"(未知任务)。

当任务被解决时,会给出一个未知人类解决任务的视频,如下图所示,然后选择一个与人类视频有相似行为的轨迹。
对新环境的归纳
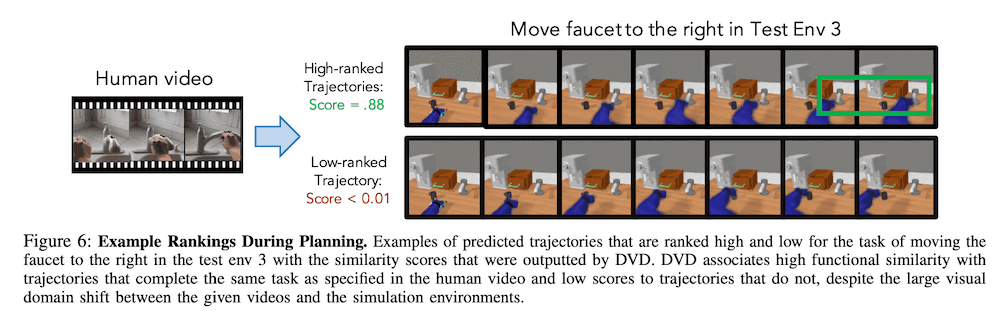
首先,我们研究了DVD对未知环境的概括性能。我们通过将不同数量的人类数据与机器人在训练环境中的视频混合在一起,来研究针对未知环境的泛化性能,以完成三个目标任务。假设是,使用各种人类数据将导致在未知环境上有更高的表现。为了检验这一点,我们比较了仅有机器人(Robot Only)和机器人+K人类任务(Robot+K Human Tasks)的表现。这里,$K$值为3意味着数据包含目标任务的所有数据,而$K$值大于3意味着数据包含与目标任务无关的任务的数据。为了评估这些结果,我们检查了在训练视觉动力学模型并将视觉MPC和DVD输出作为奖励时的成功任务数量,如上节所述。用于训练视觉动力学模型的数据是在测试环境中自动收集的。结果如下图所示,可以看出,包括人类数据时,成功的数量比不包括人类数据时要高得多,即使这些数据与任务不相关。
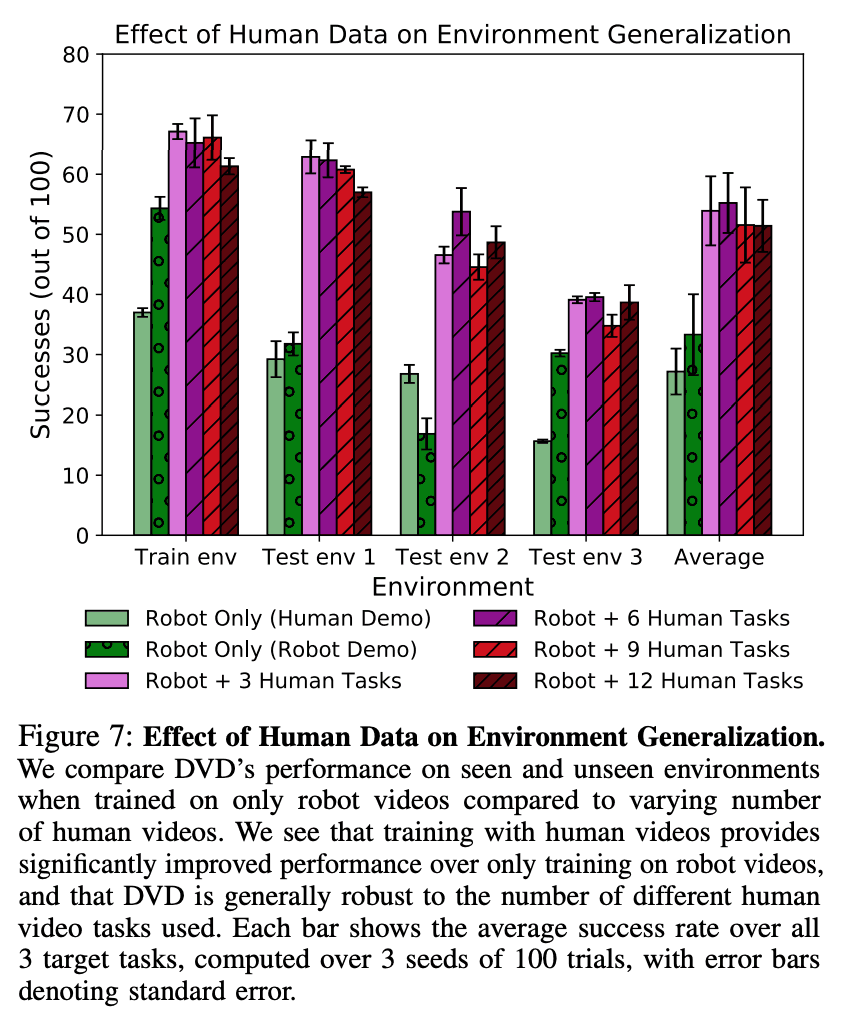
对未知任务的归纳总结
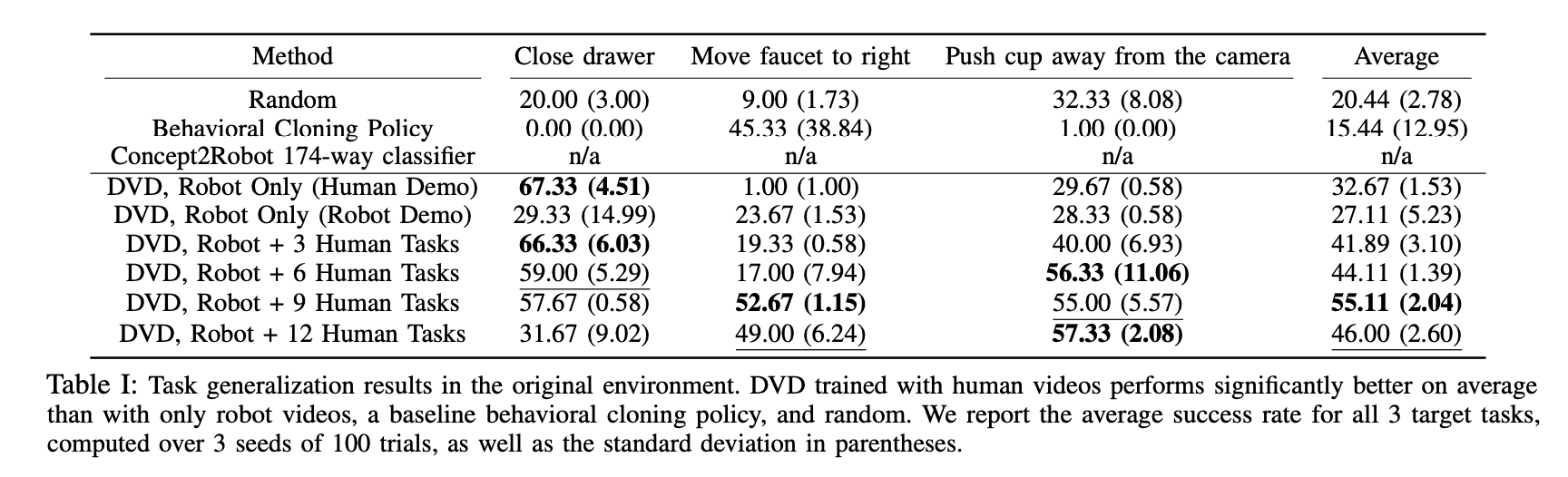
接下来,我们进行了一个实验来测试未知任务的泛化性能。在这里,我们没有把目标任务的数据纳入DVD的训练中,而是用机器人的数据和不同数量的人类数据来完成三项任务:(1)打开抽屉,(2)从右到左移动一个物体,(3)不移动任何物体。就实验环境而言,我们想研究任务的泛化性能,所以我们使用与测试环境相同的训练环境。下表显示了每个数据集的每个任务的成功率。从下面的结果中,我们可以看到,与前面的结果一样,即使我们添加了与任务无关的人类数据,与只有机器人的情况相比,成功率仍然平均较高。特别是在 "仅有的机器人 "的情况下,我们发现将水龙头移到右边的任务几乎不可能解决,因为它未能识别任务本身。
与其他方法的比较
在这里,我们检查了DVD是否能够比其他方法更有效地使用人类视频。其中一个基线是Concept2Robot,它使用用Sth Sth V2数据集训练的视频分类器的输出作为奖励。然而,与DVD不同,Concept2Robot不允许我们对演示任务的执行设定条件,因此我们在没有任何条件的情况下进行了实验。作为替代基线,我们使用了一种叫做演示条件行为克隆的方法,它使用行为克隆来学习以机器人或人类演示为条件的行动。我们还增加了一个随机政策作为比较。下图显示了结果,可以看出,与其他任何方法相比,DVD在100次试验中的成功次数最高,这表明Concept2Robot对未知任务的概括性不强,因为它不能以要解决的未知任务的演示作为条件。这表明Concept2Robot对未知任务的概括性能很差。
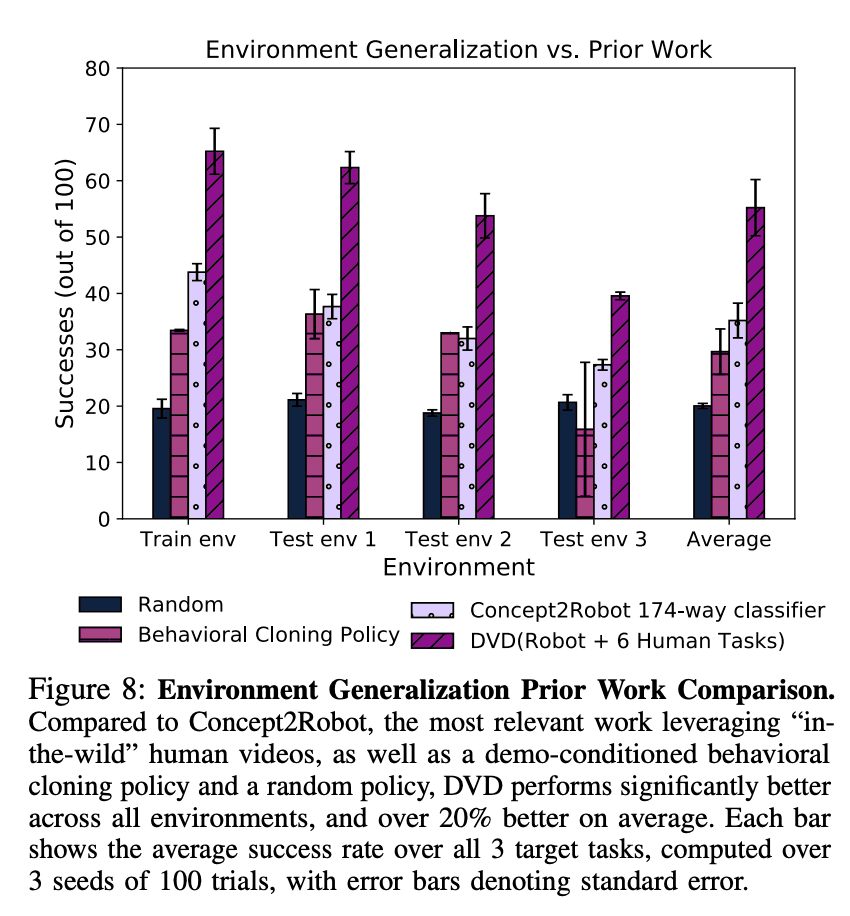
实际实验中的有效性
在模拟实验中效果很好,但在真实实验中呢?
在真正的实验中,和以前一样,我们用不同数量的人类视频来比较DVD。下表显示了在20次试验中我们能够解决多少次任务,从结果中我们可以看出,使用人类视频比单独使用机器人数据获得了更多的成功。下面的结果还表明,使用与任务基本无关的人类数据($K$>3),比不使用人类数据的成功率更高。
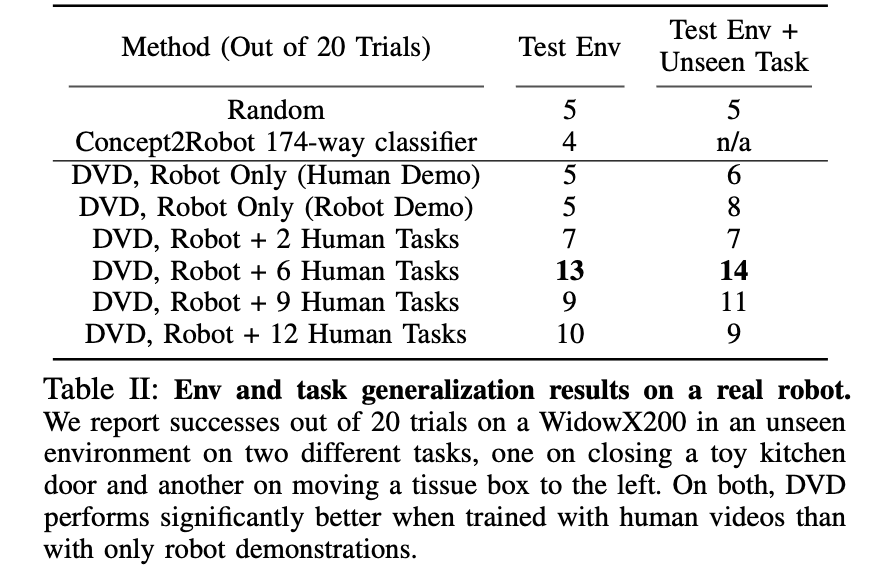
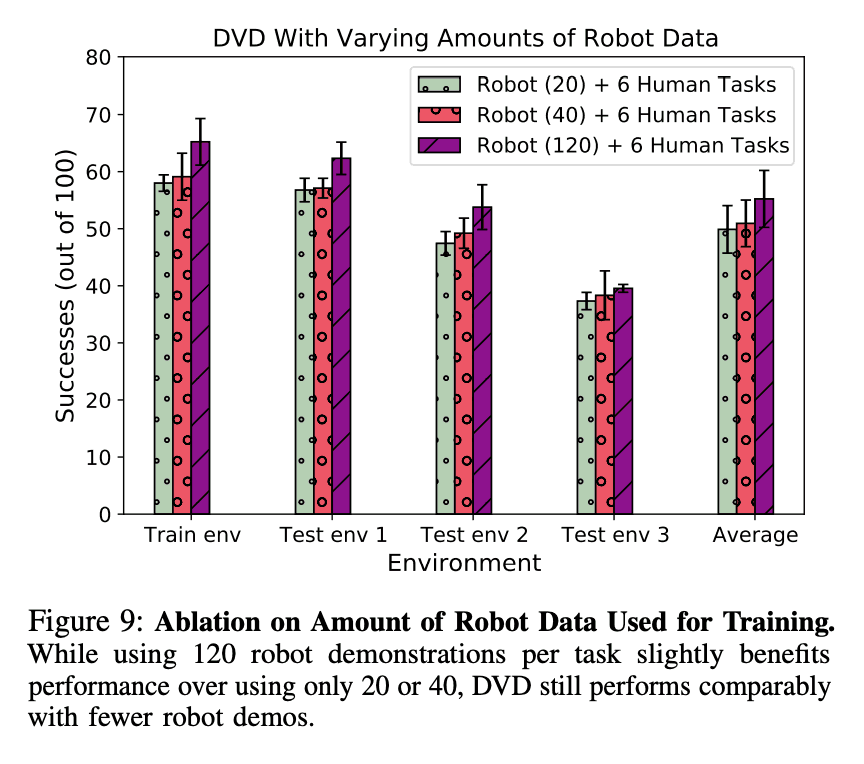
数据量与机器人性能之间的关系
最后,我们调查了机器人数据量和性能之间的关系。在前面的实验中,我们使用了120个机器人演示,但下图是一个实验的结果,看看如果机器人的数据量小得多,性能会受到什么影响。下图显示,当数据量减少时,成功任务的数量没有明显差异,这表明拥有少量DVD数据的机器人可以表现良好。
摘要
长期以来,人们都知道机器人的大规模数据很难获得,最近有很多研究方向是利用人类数据来提高学习效率和泛化性能,本文就是这样。然而,机器人数据和人类数据之间的领域差异太大,所以我们需要继续探索如何更有效地使用它们。



与本文相关的类别





