
ControlNet将彻底改变扩散模型,使稳定扩散的AI角色能够被引导到特定的姿势?
三个要点
✔️ ControlNet是一个神经网络,用于控制大型扩散模型并适应额外的输入条件
✔️ 它可以端到端地学习特定的任务条件,对小的训练数据集具有鲁棒性
✔️ 大型扩散模型,如稳定扩散模型,可以用ControlNet来增加条件输入,如边缘图、分割图和关键点
Adding Conditional Control to Text-to-Image Diffusion Models
written by Lvmin Zhang, Maneesh Agrawala
(Submitted on 10 Feb 2023)
Comments: Published on arxiv.
Subjects: Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI); Graphics (cs.GR); Human-Computer Interaction (cs.HC); Multimedia (cs.MM)
code:

本文所使用的图片要么来自论文、介绍性幻灯片,要么是参考这些图片制作的。
与以前的研究相比,它有什么了不起的地方?
这篇论文发表于2023年2月10日,几天后,在GitHub上实现了稳定扩散的 WebUI扩展,并迅速成为世界性的现象。这是一个巨大的成功,因为它使人们在用人工智能生成图像时更容易使角色摆出特定的姿势。
随着Controlnet的推出,AI Illustration已经完全改变了游戏。从线条艺术中着色的能力是一个真正伟大的功能!关键是你可以 "保持线条的原样 "或 "让人工智能纠正它们"!关键是你可以 "让线条保持原样 "或 "让AI纠正它们"。
- Io Kenki @Studio Masakaki (@studiomasakaki) 2023年3月5日
这个人没有指定颜色,但如果你指定 "红头发、黑衣服、黄眼睛 " pic.twitter.com/V0flFRYmqp
介绍。
本文介绍了ControlNet,一个端到端的神经网络架构,它控制一个大规模的图像扩散模型来学习特定任务的输入条件。
ControlNet将大型扩散模型的权重克隆为可训练和锁定的副本,并使用一种称为 "零卷积 "的独特类型的卷积层将它们连接起来。在本文中,我们表明,即使ControlNet是在个人电脑(单个Nvidia RTX 3090 Tl)上的一个小数据集上训练的,它也能在一个特定的任务上取得与在具有TB级GPU内存和数千个GPU的大型计算集群上训练的商业模型相当的竞争结果,并具有我们已经证明可以获得有竞争力的结果。
大规模的文本-图像模型可用于通过简单的文本提示输入来生成有视觉吸引力的图像。然而,这就提出了一个问题:这种方法对于具有明确问题集的特定图像处理任务来说是否有效,例如理解物体形状和方向。本文认为,某些任务往往有小的数据集,可能需要快速的学习方法和预先训练好的权重来在可用的时间和内存空间内优化大型模型。此外,各种图像处理问题涉及不同形式的问题定义、用户控制或图像注释,这可能需要一个学习解决方案,而不是人类指导的程序性方法。这就是控制网被提出的地方。
ControlNet将权重分为可学习和锁定副本,锁定副本保留原始权重,可学习副本在特定任务的数据集上学习条件控制 ControlNet使用卷积层来存储可生成的权重。在不同大小的数据集上,可以像使用独特的卷积层类型(ZERO CONVOLUTION)微调扩散模型那样快速学习。
建议的方法
1.控制网的细节。
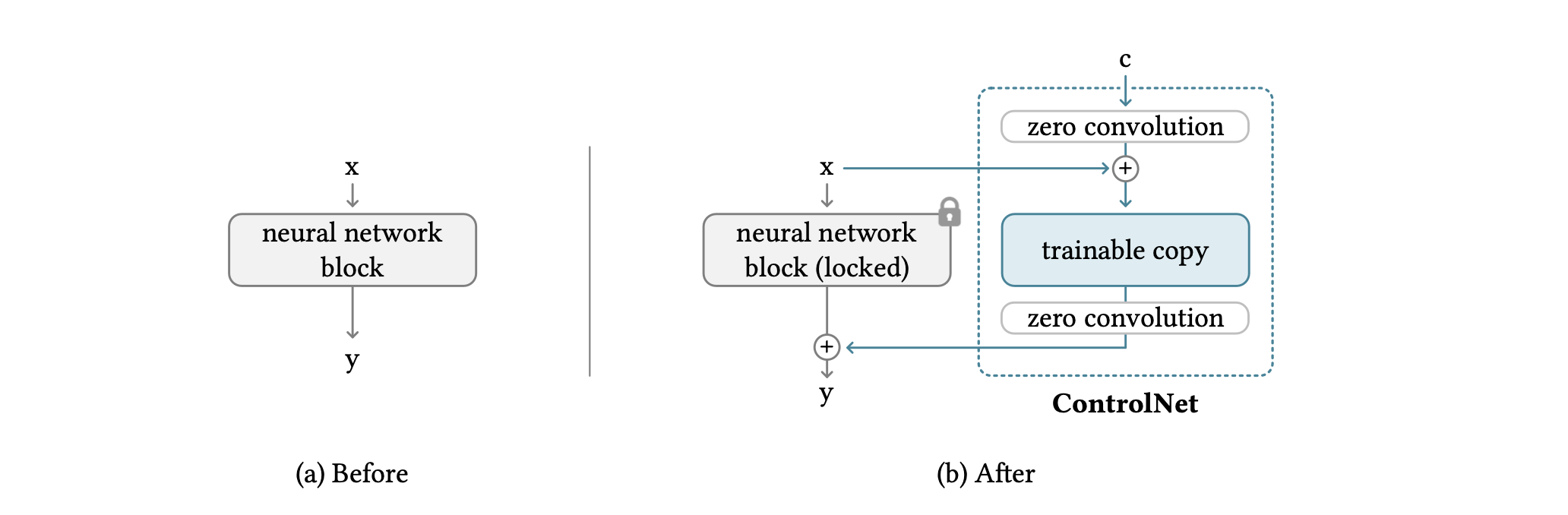
ControlNet允许你对神经网络块的输入条件进行操作,以更精细地控制整个神经网络的行为。在这种情况下,"网络块 "是一个常用于建立神经网络的单元。例子包括'resnet'块和'transformer'块。
网络块由一个特殊的卷积层连接,称为 "零卷积",它允许更高的控制程度,同时保留神经网络的每一层。零卷积是一个1×1卷积,初始化为零层,其结构包含可训练副本和原始参数。同时,零卷积的梯度计算是直接的:神经网络块的权重和偏置的梯度不受影响,因为特定输入的梯度为零。这使得零卷积成为一个唯一连接的层,通过学习从零增长到其最佳参数。(1)是零卷积连接前的方程,(2)是连接后的方程。

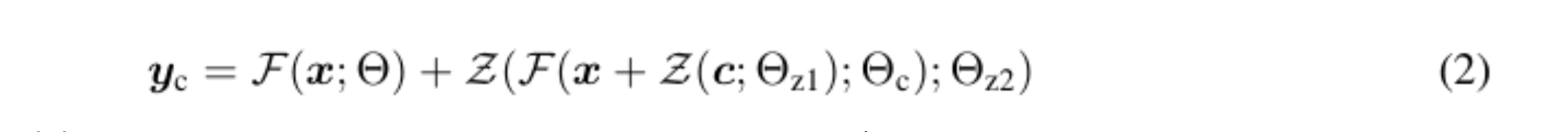
2.图像扩散模型中的控制网。
描述了使用ControlNet来控制一个叫做稳定扩散的大型文本-图像扩散模型,它基本上是一个25个块的U型网。该模型使用OpenAI CLIP对文本进行编码,并使用位置编码对扩散的时间步骤进行编码。为了有效地训练模型,整个512x512的图像数据集以类似于VQ-GAN的方式被预处理成64x64的 "潜在图像"。因此,ControlNet需要将基于图像的条件转化为64x64的特征空间,并匹配卷积大小。
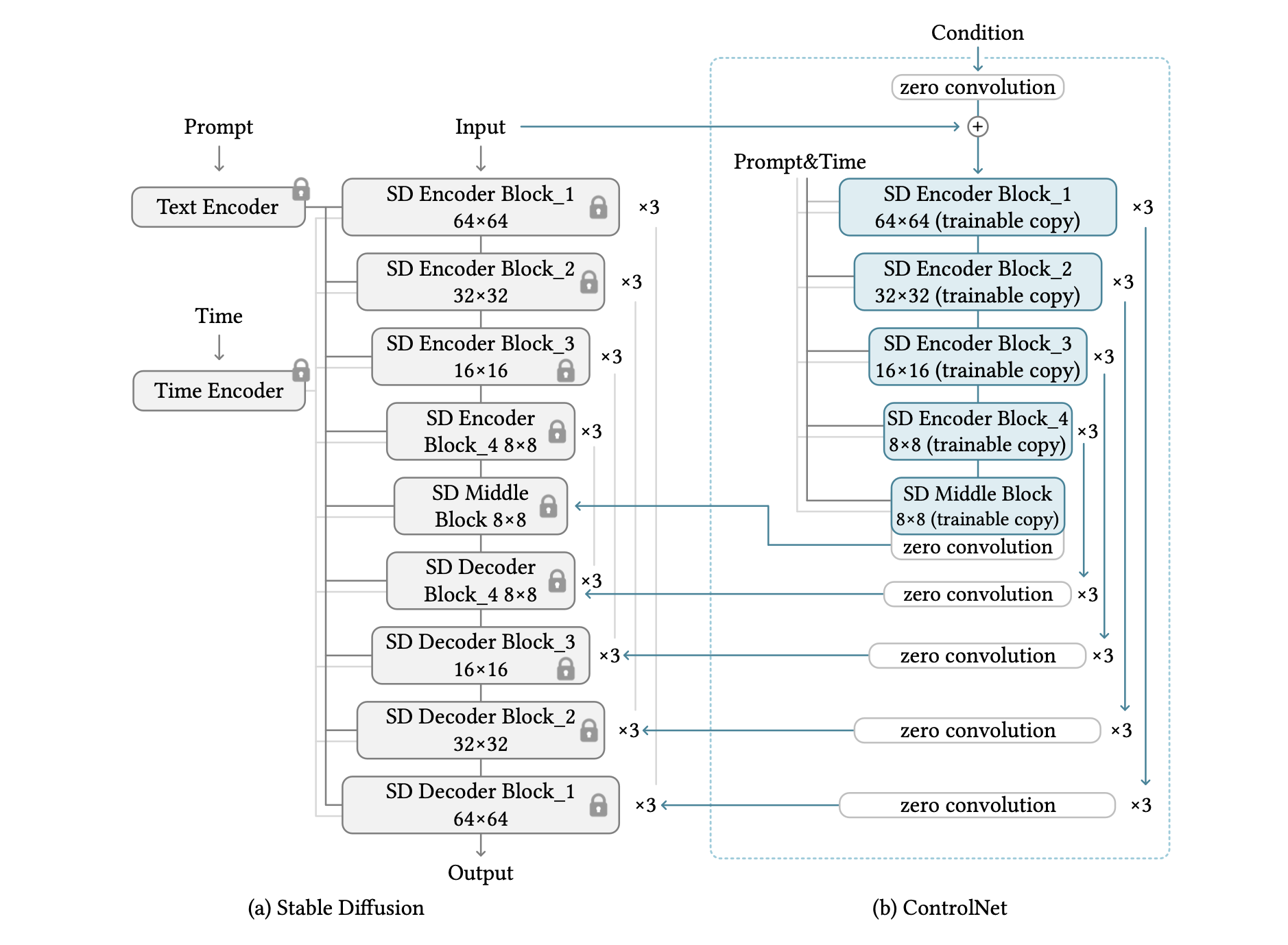
上图显示了ControlNet被用来控制U型网的每一层。这种架构的计算效率高,节省了GPU内存,并可能适用于其他扩散模型。原始权重被锁定,所以在学习过程中不需要对原始编码器进行梯度计算,因为原始权重被锁定。这加快了训练速度并节省了GPU内存,因为避免了原始模型一半的梯度计算:在ControlNet上训练稳定扩散模型节省了大约23%的GPU内存,每次迭代训练只需要通常时间的34%(Nvididia(在Nvidia A100 PCIE 40G上测试)。
3.关于学习模型
图像扩散模型通过向像素或潜伏图像空间添加噪声来逐步对图像产生噪声;稳定扩散使用潜伏图像进行训练。这些模型根据时间步骤、文本提示和特定任务等条件,学习预测将被添加到图像中的噪声。
在训练过程中,50%的文本提示被随机替换为空字符串,以提高模型从输入控制图中识别语义内容的能力,如Canny边缘图和人类涂鸦。这是为了让模型编码器从输入控制图中学习更多的语义内容,作为不显示提示信息时的一种选择。
实验结果
实验装置
在这个实验中,所有的结果都是在CFG规模设置为9.0时获得的。DDIM被用作采样器。默认情况下,使用20个步骤。三种类型的提示被用来测试该模型。
- 没有提示:使用空字符串""作为提示。
- 默认提示:由于稳定扩散本身是根据提示进行训练的,因此,如果不提供提示,空字符串对模型来说是一个意外的输入,SD倾向于生成随机纹理图。更好的设置是使用无意义的提示,如 "一张图片"、"一张漂亮的图片 "或 "一张专业图片"。在本实验中,"一张专业的、详细的、高质量的图像 "被用作默认提示。
- 自动提示:为了测试全自动管道的最大质量,利用在 "默认提示 "模式下获得的结果,使用自动图像说明方法(例如BLIP[34])生成提示。生成的提示语再次被扩散。
- 用户提示:用户给出提示。
定性结果
本文中的定性结果见图4~15。这里挑出一些结果。



因果推理
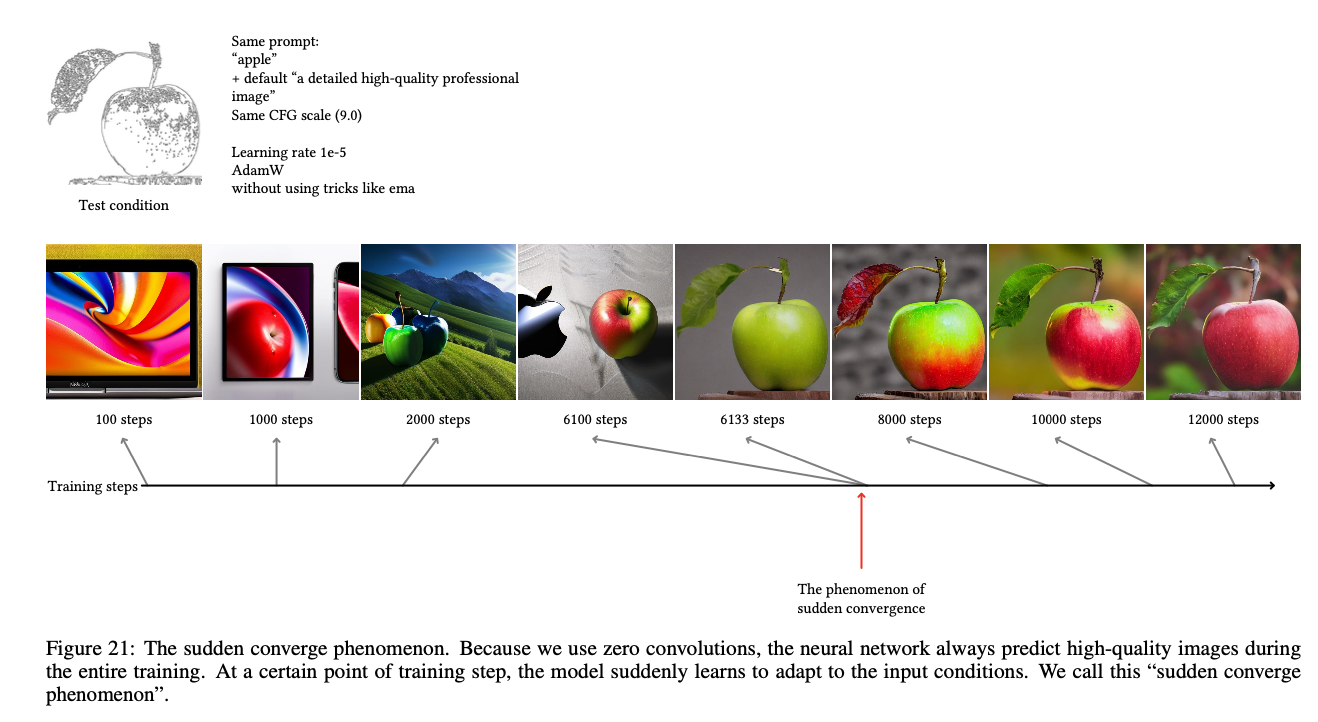
在图21中,注意到了 "突然收敛现象",即模型突然跟随输入现象。
是否有任何挑战?
如果模型错误地感知了输入图像的含义,即使提供强有力的提示,似乎也难以消除负面影响。在下面的图片中,提示表示 "从头顶看农场的景色",但人工智能模型错误地将线图识别为 "一杯水"。

摘要
论文提出了一个神经网络架构ControlNet,用于控制扩散模型;ControlNet支持扩散模型的额外条件,并可以在小的训练数据集上进行稳健的训练。ControlNet的学习速度与扩散模型的微调相当,可以在个人设备上进行训练。ControlNet也可用于丰富控制大规模扩散模型的方法,并使相关的应用更加容易。



与本文相关的类别

