[AutoFormer] 寻找图像识别的最佳转化器
三个要点
✔️ 在视觉任务中应用One-Shot NAS到Transformer。
✔️ 提出权重纠结,分享大部分的子网权重
✔️ 与现有基于变压器的方法相比,性能优越
AutoFormer: Searching Transformers for Visual Recognition
written by Minghao Chen, Houwen Peng, Jianlong Fu, Haibin Ling
(Submitted on 1 Jul 2021)
Comments: Published on arxiv.
Subjects: Computer Vision and Pattern Recognition (cs.CV)
code:

本文所使用的图片要么来自论文、介绍性幻灯片,要么是参考这些图片制作的。
简介
Transformer在自然语言处理以及各种视觉任务(如图像分类)中表现出很高的性能。那么,对于视觉任务来说,变压器的最佳架构是什么?
在Transformer中,可以通过改变嵌入维度、层的深度、头的数量等来设计各种架构。然而,这些应该如何设置并不明显。这使得为变压器设计一个合适的架构成为一个困难的问题。
在这篇文章中,我们介绍了AutoFormer,一种致力于在视觉任务中搜索Transformer的最佳架构的NAS算法,这是一项解决这个问题的研究。
建议的方法(AutoFormer)
AutoFormer是一种技术,它将一种叫做One-Shot NAS的技术应用于视觉任务中的Transformer的架构探索。然而,由于很难将现有的One-Shot NAS原封不动地应用到变形金刚上,所以又应用了一种叫做重量纠缠的扭曲。
关于一拍即合NAS
在NAS(神经架构搜索)中,找到最佳架构的最简单方法是从头开始训练不同的架构并比较它们的性能。当然,随着数据集和架构的增大,这种方法大大增加了所需的计算成本。
One-Shot NAS是旨在减少这种计算成本的方法之一。
One-Shot NAS分为两个主要层次。
在第一步,由超网$N(A,W)$代表的网络被训练一次($A$是建筑搜索空间,W是超网的权重)。
在第二阶段,我们用一些超网的权重$W$作为子网$alpha\in A$的权重,这些子网是搜索空间中的候选架构,以比较每个架构的性能。这些由以下公式表示
- 第一步:$W_A=underset{W}{arg min} L_{train}(N(A,W))$
- 第二步:$alpha^{ast}=underset{alpha\in A}{arg max} Acc_{val}(N(alpha\w))$
在学习的第一阶段,我们在超网中随机抽取子网,并更新这些子网所对应的点的权重。在架构搜索的第二阶段,我们使用各种搜索技术,如随机、进化算法和强化学习。
关于重量纠缠
在现有的One-Shot NAS中,网络中的每一层都使用不同的独立块作为子网权重。如果这个策略直接应用于变压器,就会出现超网收敛慢和子网性能差等问题。因此,AutoFormer通过在每层之间共享大部分权重来解决这些问题。这些差异在下图中得到了说明
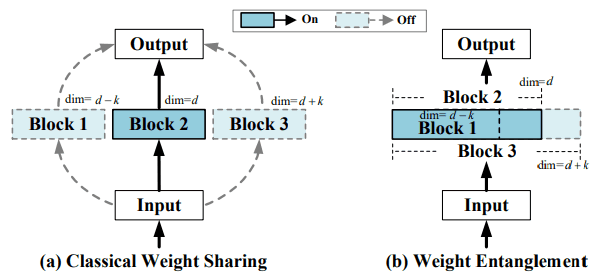
换句话说,AutoFormer在子网中选择尽可能大的区块子集来进行搜索。
(超级网将与子网中最大的架构相同)。
下面是现有政策和权重纠缠之间的比较结果。
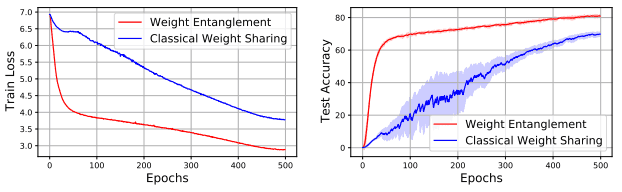
左图为超网训练损失,右图为子网ImageNet Top-1准确率。
这种独创性导致(1)更快的收敛,(2)减少内存成本,以及(3)改善子网性能。
关于搜索空间
AutoFormer在三个主要的搜索空间(微小/小型/基础)进行架构探索。这在下表中有所显示。
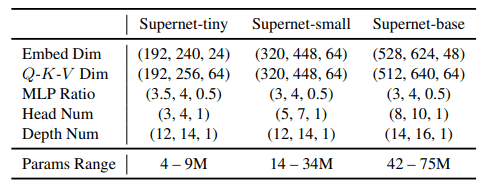
本表中的(a,b,c)分别表示(下限,上限,台阶)。例如,(192,240,24)意味着对三个参数设置[192,216,240]进行搜索。
关于自动成形器管道
与前面提到的One-Shot NAS一样,AutoFormer的流水线也分为两个阶段。
第一阶段:学习超级网
在超级网的训练过程中,在每个迭代中,从定义的搜索空间中随机抽出一个子网,并更新超级网的相应权重(其余部分被冻结)。
第二阶段:架构的进化探索
为了找到最佳架构,我们使用进化算法来搜索具有最高验证精度的子网。具体来说,要遵循以下步骤
- 最初,选择$N$随机架构作为种子。
- 选出前k$架构作为父代,通过交叉和突变生成下一代。
- 交叉:在两个随机选择的候选人基础上生成一个新的候选人。
- 突变:以概率$P_d$突变层的深度,以概率$P_m$突变每个区块,生成新的候选区。
AutoFormer在寻找最佳架构时遵循这些管道。
实验结果
在我们的实验中,我们将根据以下设置来测试AutoFormer的性能
学习超级网的知识
Supernets的训练方式与DeiT相同,是一种基于Transformer的视觉任务的方法。超参数和其他训练设置如下
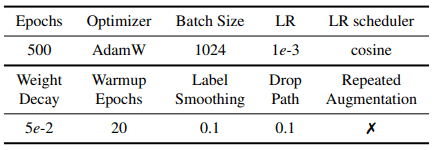
对于数据增强,使用RandAugment、Cutmix、Mixup和随机擦除等方法,设置与DeiT相同。图像被分为16x16个斑块。
关于进化搜索
进化搜索遵循与SOPS相同的协议。我们使用ImageNet验证集作为测试集,10,000个训练实例作为验证集。种群规模设定为50,代数设定为20,每代的父系结构数设定为10,突变概率设定为$P_d=0.2$和$P_m=0.4$。
关于权重纠缠和进化搜索
首先,在AutoFormer中验证权重纠缠和进化搜索的有效性的结果显示如下。

在这个表格中,Retrain显示的是搜索得出的最佳架构从头开始重新训练300个epochs时的性能(Inherited意味着没有重新训练)。
令人惊讶的是,对于权重纠缠,在没有重新学习和没有重新学习的两种情况下,性能变化很小。下面是关于这一点的更详细的实验。
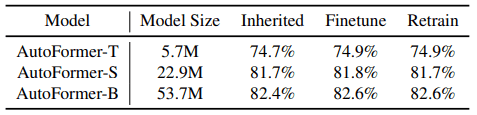
从表中可以看出,从超网继承的权重(Inherited)、30个历时的微调(Finetune)和300个历时的从头学习(Retrain)在性能上的变化非常小。
下图还显示,有一些子网在没有重新学习的情况下表现良好。
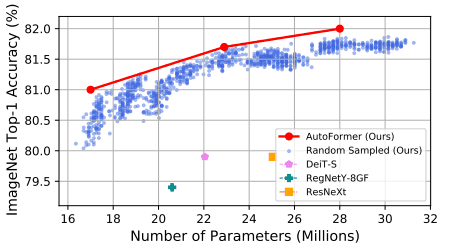
这些结果表明,使用子网的性能是有效的,其权重是从超网中继承的,作为比较架构优越性的措施。随机搜索和进化搜索的比较结果也显示如下。
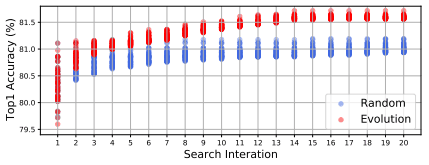
在这个图中,每一代的前50名表现都被绘制出来,显示了进化搜索比随机搜索的优越性。
与现有方法的结果比较
与AutoFormer在ImageNet上对现有各种基于CNN/Transformer的方法的比较结果如下。
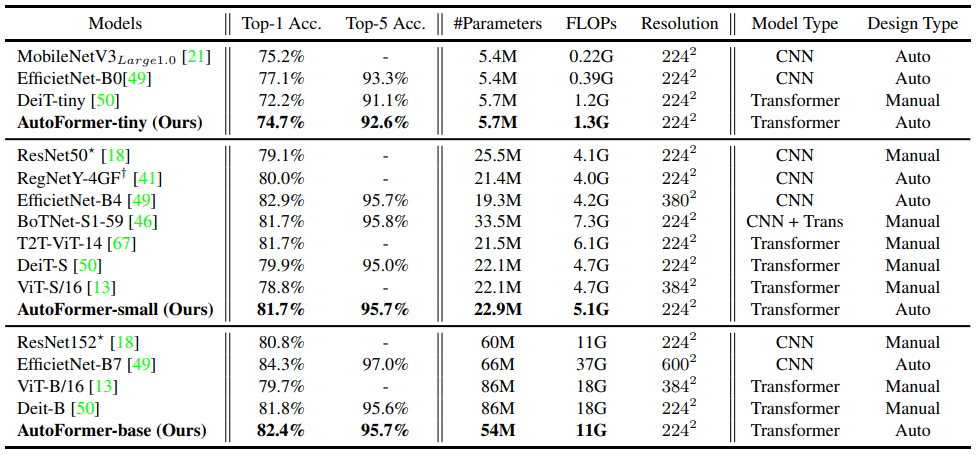
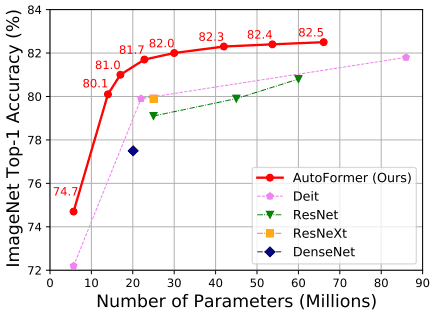
AutoFormer的结果显示了没有重新学习或微调的结果,以及从超网继承的权重。
从表中可以看出,我们的方法的准确性优于基于变形器的方法ViT和DeiT。然而,应该指出的是,它仍然不如基于CNN的方法MobileNetV3和EfficientNet,而且在视觉任务方面没有超过所有现有方法。
关于转移学习
下面是在不同的数据集上转移训练一个在ImageNet上训练的AutoFormer的结果。

总的来说,可以看出,即使在参数数量较少的情况下,其准确性也与现有的方法相当。
摘要
本文介绍了AutoFormer,即Transformer用于可视化任务的一次性架构探索方法。
通过使用Weight Entanglement(与现有的One-shot NAS不同的策略),AutoFormer取得了优异的性能,如更快地学习超网和更好的子网性能。此外,在搜索空间中加入卷积运算,并使用权重纠缠进行卷积网络的搜索,使这项研究在未来有了很大的发展。



与本文相关的类别



![[MusicLM]谷歌开发的文本到音乐生](https://aisholar.s3.ap-northeast-1.amazonaws.com/media/October2023/musiclm-520x300.png)


