视觉任务的变换器混合模型:BoTNet
3个要点
✔️ 使用卷积层和自注意力层的混合架构
✔️ 与卷积层饮水网络相比,提高了模型性能
✔️ 在物体检测、实例分割和图像识别任务中取得了良好的效果
Bottleneck Transformers for Visual Recognition
written by Aravind Srinivas, Tsung-Yi Lin, Niki Parmar, Jonathon Shlens, Pieter Abbeel, Ashish Vaswani
(Submitted on 27 Jan 2021)
Comments: Technical Report, 20 pages, 13 figures, 19 tables
Subjects: Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI); Machine Learning (cs.LG)code:

首先
如今的计算机视觉任务,如图像识别、实例分割和对象检测,通常使用深度卷积神经网络(Deep CNNs)来执行。这些网络通常由大小为3x3的卷积层组成,善于捕捉局部信息。此外,还有一种趋势是通过积累许多信念网来适应全球信息。变形金刚和多头自我注意(MHSA)网络在捕捉NLP任务所需的全局信息方面非常出色。因此,我们可以直观地认为,使用MHSA采集全局信息,使用CNN采集局部信息可以提高性能。
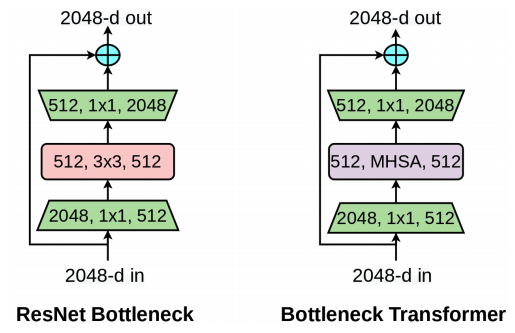 ResNet瓶颈块和瓶颈变压器(BoT)块。
ResNet瓶颈块和瓶颈变压器(BoT)块。
在本文中,我们提出了一种混合网络,其中ResNet架构中的卷积层被MHSA层取代。这种混合网络提高了网络的全局信息捕获能力,同时又利用了卷积层的下采样和局部特征捕获能力。
瓶颈变压器网(BoTNet)

BoTNet架构与ResNet架构的比较,如表所示。每个架构都由四个阶段[c2,c3,c4,c5]组成,每个阶段都由多个残差块组成;BoTNet中唯一不同的是,最后堆栈中的3x3卷积层被一个MHSA层取代。
自觉性块的计算复杂度为O(d)2n)其中n是实体的数量,d是这些实体的维数。可以看出,对于分辨率为1024x1024的图像,需要相当大的计算量。因此,MHSA只在特征图的最后一部分被纳入网络,因为那里的分辨率较小。在ResNet的第一个块中,我们使用stride 2卷积对图像进行降采样。为了在BoT块中进行下采样,堆栈的第一层使用Stride 2。平均合用层。

对于小尺寸的图像,如ImageNet,当达到MHSA时,第五堆栈中的特征图会变得更小(对于1024x1024的大图像来说是64x64或32x32,而对于224x224的小图像来说是14x14或7x7)。因此,我们引入BoTNet-S1架构,它省略了c5块组第一块的两个跨度。换句话说,模型注意不要让初始输入图像尺寸太小。
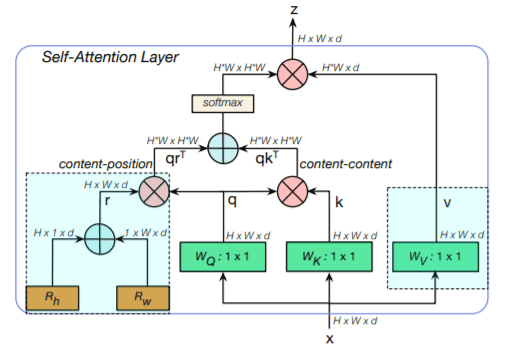 BoTNet中使用的MHSA
BoTNet中使用的MHSA
上图显示的是全部2全部 注意,其中1x1代表1x1卷积,+代表元素相加,X代表矩阵乘法。每个BoT块由上述四个注意头组成:两个相对位置编码:高度和重量,用来给二维特征图添加空间信息。这些编码相加,再乘以查询矩阵的副本。自我关注的操作,对qrT+qkT其中,自我关注的操作由以下方式给出其中k、q、r分别是密钥、查询和位置编码。在数学上,这块工作原理如下。
q=conv1x1Wq(X),v=。 conv1x1Wv(X), k=conv1x1Wk(X)
Y = Softmax(qrT+qkT))v
评估
BoTNet架构非常容易实现,所以这不是本论文的目的。本文的目的是制定一个带有卷积层和自注意力层的混合架构。在计算机视觉任务中是有效的。为此,我们比较了卷积层专用网络ResNet、EfficientNets、SENets和卷积层和自觉性层,以及带有卷积层和自注意层的BoTNet,用于视觉任务(图像识别、实例分割和物体检测)。自我关注块的加入,以实现各种任务的性能提升,如下图所示。
BoTNet与ResNet
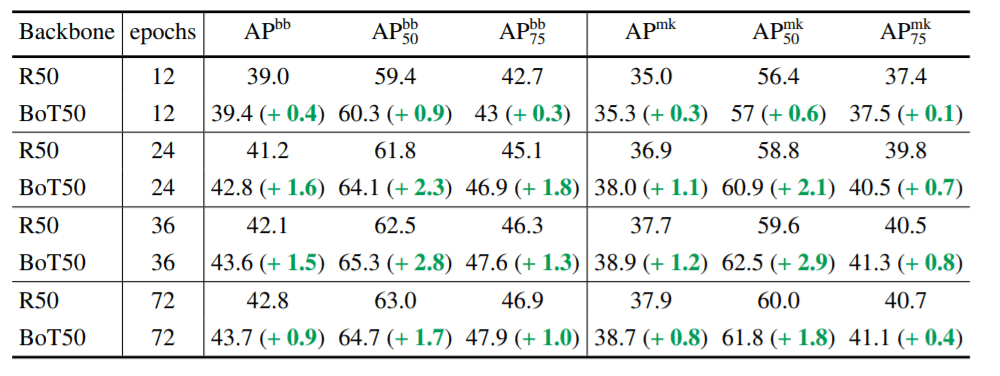 COCO上的BoTNet与ResNet
COCO上的BoTNet与ResNet

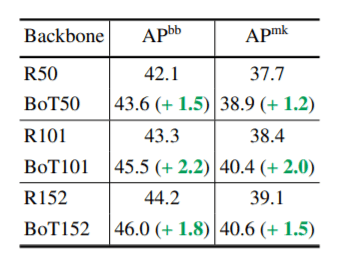
BoTNet与ResNet在ImageNet上的对比。
上表显示了在COCO数据集上训练的ResNet-50骨干和BotNet50。 骨干网在COCO数据集上训练的CNN架构,下表是ImageNet上的图像分类性能。自我关注在所有情况下,基于BoTNet的技术都优于ResNet架构。另外,BoTNet在以下方面的表现优于ResNet。多级抖动我们可以看到,BoTNet更多的受益于扩展,如
上图显示了一个多级抖动在一个更大的ResNet架构上,在1024x1024分辨率的图像上训练36个纪元。
BoTNet vs EfficientNets vs SENets
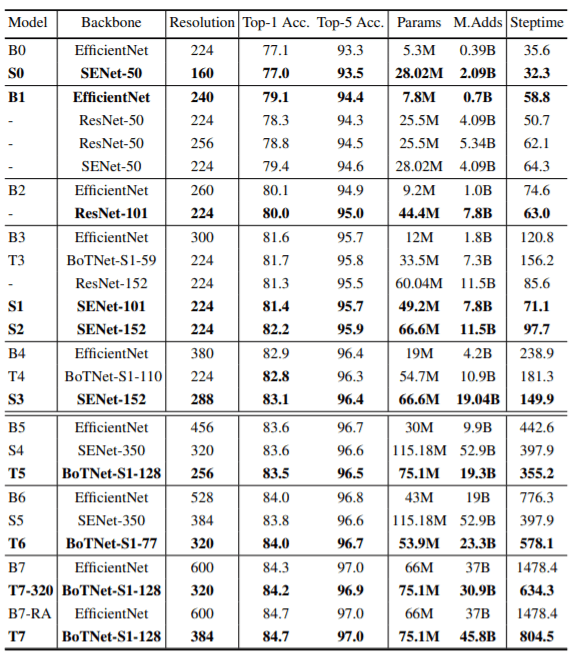
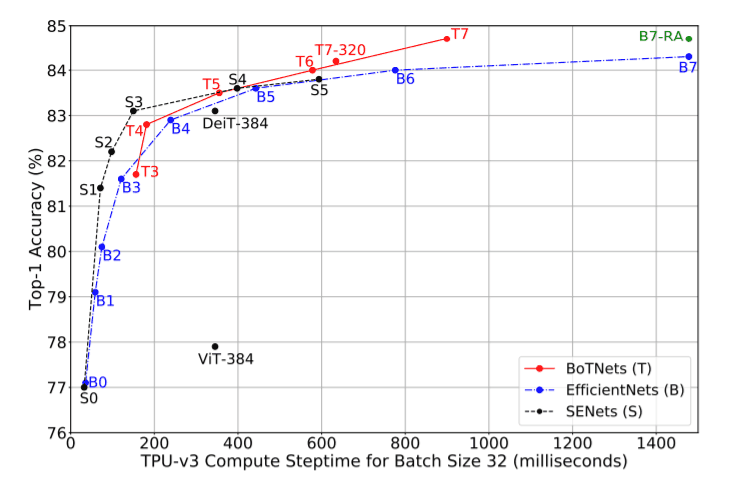
上图显示了BoTNets与EfficientNets、SENets、ViT和其他自注意力网络的比较。可以看出,对于高精度模型来说,BoTNets的效率要比EfficientNets高得多;EfficientNets的参数较少,但似乎没有利用现代TPU的强大功能,几乎在所有情况下都比ResNets和SENets在低精度体系中对模型的表现非常好,但在高精度体系中表现落后。
多少钱需要自我关注?

上图显示了用MHSA替换不同数量的3x3卷积层进行消融的结果。[x1,x2,x3]代表三个卷积层,0。指不替换,1意味着被替代.可见,R101和R50都被BoT50和BoT101的适当配置所击败。从这一结果,我们可以得出这样的结论。MHSA:块,说明增加块数不一定能提高性能。然而,与其说是堆叠卷积层,不如说是堆叠卷积层以某种形式,而不是堆砌到自我关注。到某种形式的自我关注,比堆叠卷积层更好。
结论
本文的实验是基于自觉性和CNNs可以结合起来,提高计算机视觉的准确性。然而,这似乎是一种比构建所有卷积层更好的方法。在今后的工作中,我们将探索使用。自觉性与其他模型(如DETR)配合使用,甚至将其扩展到大型数据集,如JFC、YFCC和Instagram。如何将这种混合网络应用于开发未来最先进的模型,将是一个有趣的问题。



与本文相关的类别



![[MusicLM]谷歌开发的文本到音乐生](https://aisholar.s3.ap-northeast-1.amazonaws.com/media/October2023/musiclm-520x300.png)


