
你需要知道的关于计算机视觉中变压器的一切!Part5(视频理解、低镜头、聚类、3D分析)
3个要点
✔️解释Transformer在计算机视觉中的应用。
✔️讲解视频理解、低镜头、聚类和3D分析任务中的研究实例。
✔️共37款,本文介绍了9款。
Transformers in Vision: A Survey
written by Salman Khan, Muzammal Naseer, Munawar Hayat, Syed Waqas Zamir, Fahad Shahbaz Khan, Mubarak Shah
(Submitted on 4 Jan 2021)
Comments: 24 pages
Subjects: Computer Vision and Pattern Recognition (cs.CV)
首先
Transformer不仅在自然语言处理方面表现出了很高的性能,在其他很多领域也表现出了很高的性能。其中,变压器在处理视觉信息的计算机视觉领域的应用研究已经非常普及。
鉴于这种需求,我们将对计算机视觉中的Transformer进行非常广泛和详细的描述。
本文介绍了Transformer在视频理解、低镜头、聚类和3D分析任务中的应用。
介绍了四种用于视频理解的模型,两种用于低镜头任务,两种用于聚类,三种用于3D分析。
关于其他任务的研究实例请参见第2、3、4部分,第1部分是关于计算机视觉中变压器的一般描述。
总体结构(目录)
1. about Transformer in Computer Vision (Part1)
2. A Concrete Example of Transformer in Computer Vision(Part2~5)
2.1 Transformers for Image Recognition(Part2)
2.2 Transformers for Object Detection(Part2)
2.3 Transformers for Segmentation(Part3)
2.4 Transformers for Image Generation(Part3)
2.5 Transformers for Low-level Vision(Part3)
2.6 Transformers for Multi-modal Tasks(Part4)
2.7 Video Understanding
・VideoBERT
・PEMT(Parameter Efficient Multi-modal Transformers)
・Video Action Transformer
・Skeleton-based Action Recognition
2.8 Transformers in Low-shot Learning
・CrossTransformers
・FEAT(Few-shot Embedding Adaptation)
2.9 Transformers for Clustering
・Set Transformers
2.10 Transformers for 3D Analysis
・Point Transformer
・PCT(Point-cloud Transformer)
・METRO(Mesh Transformer)
3.A Concrete Example of Transformer in Computer Vision(Part1)
2.7 视频理解
继续第4部分的内容,我们介绍一个使用Transformer进行视频理解任务的例子。从性质上看,有些模型与第4部分介绍的多模态方法密切相关。
视频 BERT
VideoBERT使用Transformer和自我监督学习,为视频理解任务提供有效的多模态学习。其架构如下:
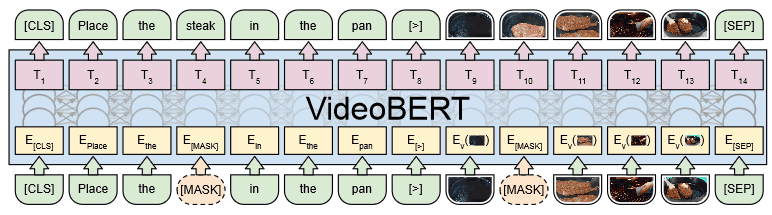
如图所示,我们以视频的字幕文字和视频特征作为输入,可以看到其结构与第四部分介绍的图像语言模型的单流模型非常相似。
使用预先训练的S3D模型获取20帧(1.5秒)视频的视频特征。此时,考虑到视频之间的状态转换速度存在差异,即使是对应同一个动作,也会以1到5步的速度对视频令牌进行随机次采样。这使得系统对视频中的速度变化具有很强的鲁棒性,并使我们能够捕捉到长期的依赖性。
训练前的任务主要分为三类。这些分别对应于输入数据模式(纯文本、纯视频和文本/视频)。
在这里,针对输入数据只有文本或只有视频的情况,我们训练系统恢复被屏蔽的令牌,就像BERT的MLM一样。
相反,如果同时给出文字和视频,我们预测文字和视频是否匹配。为此,我们使用[CLS]令牌的最后一个隐藏状态。但请注意,这个任务是嘈杂的,因为字幕文字表示的是视频中不存在的东西。
VideoBERT在动作分类、零镜头分类和视频字幕等任务上表现非常出色。实际生成的字幕句子举例如下,其中GT为正确答案句,S3D为现有方法生成的字幕句。

PEMT(参数高效多模态变压器)
现有的多模态方法如VideoBERT和VilBERT已经将语言模型部分固定为预训练模型(如BERT)。因此,他们学习跨模态信息的能力是有限制的。为了解决这个问题,实现一个可以端到端训练的多模态变压器,需要减少参数的数量(因为它消耗了大量的内存)。
我们已经证明,PEMT可以通过各种创新减少高达80%的参数数量,以端到端的方式从头开始训练多模态模型(视频中的非标记视觉和音频信息)。
该模型架构如下
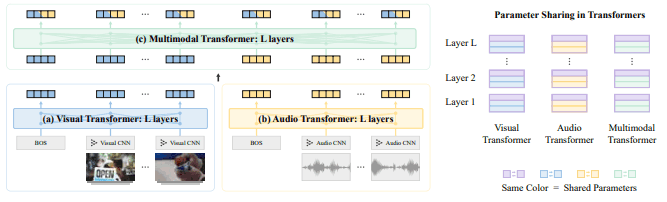
该模型的输入是一个视频片段序列$v_{1:T}$与相应的音频流序列$a_{1:T}$。例如,这些输入数据是通过将30秒的视频分成30个片段(每个片段1秒)获得的。根据此图,解释如下图所示。
(1)局部特征嵌入(对应图中的视觉/听觉CNN)
这些视觉和音频数据分别通过CNNs转换为局部特征嵌入(Local Feature Embedding)。此时,CNN的训练不是用预先训练好的模型,而是用随机初始化的模型进行端到端训练。
(2)单模情境化嵌入(对应图中的视/音频变换器)
如上所述,通过CNN获得的特征只能捕捉局部关系,无法捕捉长期依赖关系。因此,视觉和音频数据通过单独的Transformer(Visual/Audio Transformer)来获得捕捉长期依赖性的Unimodal Contextualized Embedding。
(3)多模态情境化嵌入(对应图中多模态变换器)
最后,为了获得跨模态信息,我们使用多模态变换器。经由过程这个过程,我们获得了跨越视觉和音频信息两种模式的情境化嵌入(Multimodal Contextualized Embedding)。
在预习过程中,你将执行以下两项任务。
(1)屏蔽嵌入预测(MEP)
与第4部分介绍的多模态模型类似,MLM任务有望成为第一个学习恢复随机掩盖的令牌的任务,但由于PEMT中的输入数据是视频和音频数据,因此由于输入的差异化导致的信息丢失是然而,在PEMT中,输入数据是视频和音频数据。
因此,PEMT使用对比学习来训练模型,以区分负面样本和正确样本(视频剪辑和音频流)。
具体来说,就是使用InfoNCE()。此时,InfoNCE的损耗函数如下。
$L_{NCE}(x,\tilde{o})=-E_x[\sum_tlog\frac{I(x_t,\tilde{o}_t)}{I(x_t,\tilde{o}_t)+\sum_{j∈neg(t)}I(x_j,\tilde{o}_t)}]$
这里,$\tilde{o}_t$是三个变压器中任何一个变压器在掩盖$t$的第$x_t$输入时的$t$输出。另外,$neg(t)$是负样本的指数,$I(x_t,\tilde{o}_t)=exp(FFN^T(\tilde{O}_t)W_Ix_t)$ (FFN是双层前馈网络)。
同时,在对负样本进行采样时,我们会优先选择和CNN嵌入中的正例相似的样本,以有效地训练它们。
(2)正确配对预测(CPP)
MEP任务有利于学习各模式内的动态。另一方面,对于学习跨模态动态,我们使用了一个任务来预测视频和音频数据是否来自同一个视频(CPP)。
两个[BOS]的输出,即视频/音频序列的第一个tokens,或随机位置的输出用于预测分类器。损失函数如下:
$L_{CPP}=-E_{x,y}[c・log p(c|s_g)+c・log p(c|s_h)]$。
最终的损失函数为$L_{MEP}+\alpha L_{CPP}$,对于PEMT来说,$alpha=1.0$($alpha$的值对最终的性能影响不大)。
除了变压器层之间的重量分担外,三个变压器之间的重量分担也大大缩小了模型尺寸。如下图所示。

在本文中,我们测试了第4部分介绍的多模态模型的不同架构,如早期(单流配置,如VideoBERT和VL-BERT)、中期(两个并行流配置,如Vil-BERT和LXMERT,与提出的方法相同)和后期(两个单模态的变压器配置)、后期(两种单模变压器配置),由于验证了不同的架构,证实上述提出的方法的配置是最优的。
在Kinetics-700数据集上进行了预训练,随后对下游任务进行了微调,如UCF101(短视频分类)、ESC(语音分类)、CHarades和Kinetics-Sounds(长期动作识别)。在实验中。
这表明,PEMT可以从未标记的视频(视频和音频)数据中学习有效的表征,既可以完成分别与视频和音频相关的单模态任务,也可以完成跨越视频和音频的跨模态任务。
视频动作转换器
动作变换器是一个识别视频中人类动作的模型。
人的动作识别不仅需要目标人的信息,还需要周围人和物的信息(如"拿着一个东西"或"看着一个人")。因此,本研究的目标是实现一种能够获取和使用与目标人物相关的周围人和物的上下文信息的模型。项目的总体流程如下:
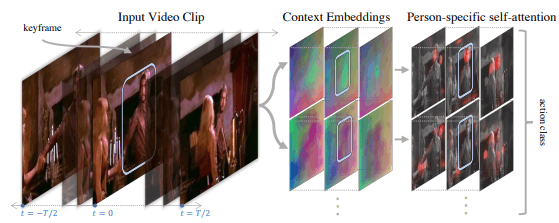
通过这种方式,从输入的视频中获得情境嵌入,然后通过特定人的自我关注来处理特定人及其周围环境的信息,进行行为分类。
其架构如下
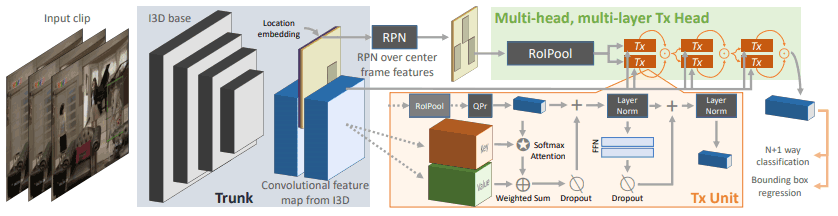
首先,我们使用CNN来提取给定关键帧前后64帧剪辑的特征。
然后通过区域提案网络(RPN)获得代表关键帧中出现的人的位置的框和分数。
在这些(代表人和他们在图像中的位置)中,选择得分高的$R(=300)$盒子,这些盒子被用作变压器头的查询$Q$。对于键值$K$和值$V$,采用键帧前后的部分。
这个过程中,我们可以处理特定的人及其周围环境与这个人的关系信息。
动作变换器在动作识别任务中表现出了优异的性能。然而,它往往不适合本地化任务,如识别一个人的位置(因为Transformer往往包含全局信息而不是本地信息)。因此,如何实现全局信息与局部信息的权衡,将是未来的一个挑战。
・基于骨架的动作识别
基于骨架的动作识别是基于人体骨架进行动作识别的任务。在这样的任务中,如何不仅获取和处理一个视频的多帧之间的关系,而且处理多个关节之间的关系是一个问题。
在本研究中,引入了空间自我注意(SSA)和时间自我注意(TSA)来处理这种时间和空间信息。画面如下图所示。
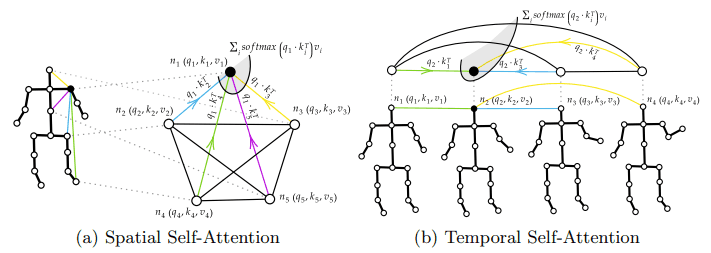
因此,SSA用于处理骨骼关节之间的(空间)信息,TSA用于处理多帧之间的(时间)信息。
如下图所示,该架构是一个并行的双流结构,分别处理空间和时间信息。
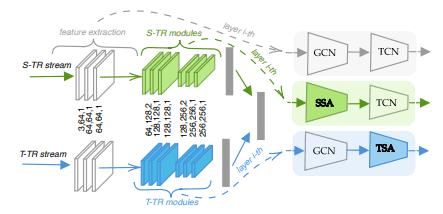
其中,GCN为图卷积,TCN为时间维度的二维卷积层。
该机型(2s-ST-TR)在NTU RGB+D 60和NTU RGB+D 120数据集上实现了SOTA。
2.8 低射学习中的变压器
接下来,我们将介绍一个变压器在Low-shot Learning环境下的应用实例。
交叉变压器
CrossTransformers在火车/测试之间分布不同的情况下,使用自我监督学习和变压器。
这里的目标是一个低镜头分类任务(使用Meta-Dataset),模型在底层数据集上进行训练,然后使用少量的标记数据(支持集)适应新的类。
本文假设当训练/测试集的分布发生变化时,性能下降的原因是只检索到分布中数据的有用表征,而分布之外的类的有用信息缺失,并将此问题称为监督崩溃问题这个问题叫做监督崩溃。如下图所示。

对于该图,Query显示了从Meta-Dataset ImageNet测试类中检索的查询的训练/测试支持集类中的最近邻居(最多前9名),使用用Prototical Net学习的embeddings。(试管状的标记表示测试组中的那些)。
理想情况下,最近的邻居应该与查询同级(即与查询有相似表示的数据被归入与查询同级),但实际上,只有5%的数据是匹配的。
此外,许多最近的邻居样本来自同一个错误的类(图中的红框),而实际上来自同一类的样本有非常不同的外观(在沙棘的情况下最明显)。
这可以解释为,虽然我们成功地将同一类数据的表征放置在特征空间的近似区域,但没有考虑到附近存在分布外样本的可能性(导致分布外类与分布内类的表征相似)。
CrossTransformers应用SimCLR和Transformer来解决这个问题。其架构如下
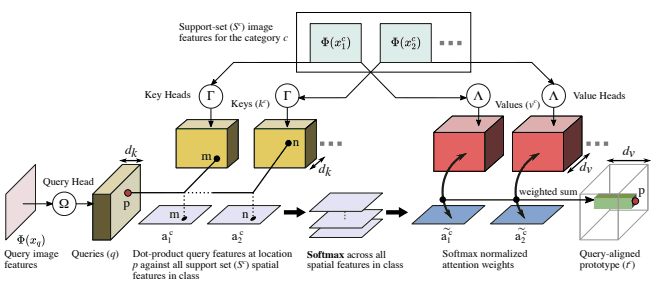
最初,我们训练了一个修改版的SimCLR(SimCLR episodes),替换了50%的训练情节。引入此法是为了避免前述强烈依赖分布内类的嵌入,并获得对分布外类也可用的嵌入。
接下来,我们使用CrossTransformers作为分类器,使用这样得到的嵌入。这是基于现有的一种方法,原型网。
从查询图像中获取查询$Q$,从支持集图像中获取密钥$K$和值$V$,根据查询图像和支持集图像的相似区域和特征进行查询图像的类判定。我们省略了细节。
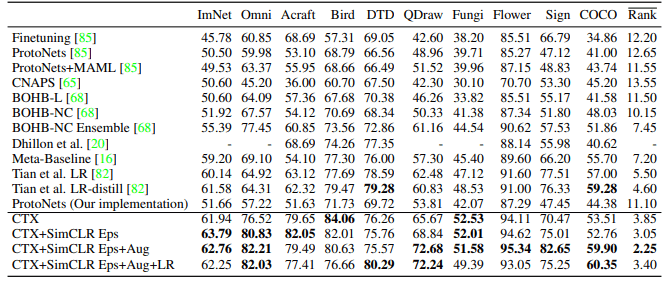
该方法在Meta-Dataset中表现出优异的性能,如下表所示。
FEAT(Few-shot Embedding Adaptation)(23)
FEAT提出了一种使用集对集函数(如Transformer)来调整实例的嵌入以适应目标分类任务的方法。
其架构如下:
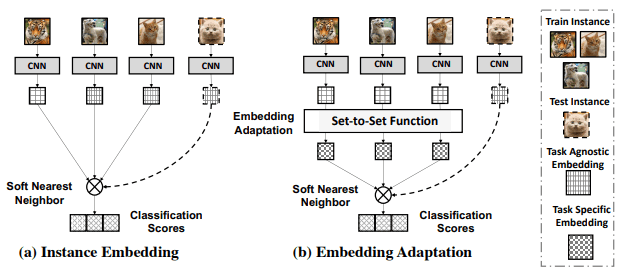
在现有的方法中,通常对所有任务使用相同的嵌入函数$E$,但FEAT使用集对集函数来获得特定任务的嵌入(图(b)嵌入适应)。
FEAT模型在归纳/归纳/概括的Few-Shot学习任务中表现良好。
2.9 设置变压器(聚类用变压器)
聚类是一种常见的无监督学习技术,其目的是将相似的数据分组。
应用Transformer的一个例子是Set Transformer,它解决的是一个叫作amortized clustering的问题。
这里的摊牌聚类是学习一个参数函数的任务,该函数将一组输入点映射到点所属的聚类中的一个中心。需要注意的是,这个任务的特点是,输出与输入数据的顺序是不变的。
集变压器旨在通过使用变压器来学习此类功能。
在变压器改进的总结中也介绍了这套变压器。
通常的变换器对n$的输入点需要$O(N^2)$的计算。为了减少它,采用ISAB(Induced Set Attention Block),如下图所示。

(MAB指多头注意块,SAB指自我注意块)。
ISAB利用$m$诱导点$I$,计算复杂度为$O(m・n)$。这些引导点被放置在空间的分布区域,这些引导点与输入点集进行比较,以帮助解决任务。
在这种情况下,最终的模型是编码器-解码器模型,如图(a)所示。编码器-解码器分别基于SAB或ISAB构建。
编码器和解码器的计算公式分别如下。
$Encoder(X)=SAB(SAB(X))$或$Encoder(X)=ISAB_m(ISAB_m(X))$。
$Decoder(Z;\lambda)=rFF(SAB(PMA_k(Z)))∈R^{k×d}$。
$PMA_k(Z)=MAB(S,rFF(Z))∈R^{k×d}$.
输入的$X$由SAB或ISAB组成的编码器转换为特征$Z$,并通过解码器转换为输出。
SetTransformer不仅对淘化聚类进行了评估,还对各种集转换任务进行了评估,如对输入集中的唯一元素进行计数、异常检测和点云分类,并表现出优异的性能。
也有新兴的研究改进SetTransformer,通过使用顺序生成簇的方法,允许可变数量的簇。
2.10 3D分析用变压器
最后,我们介绍了我们使用Transformer进行3D点云分析的工作。需要注意的是,与上述的摊开聚类类似,输出具有对输入数据的顺序不变的特性。
点式变压器(本网站的说明文章)
点变换器是研究用变换器进行三维点云处理的。如上所述,输出对输入集的顺序不变的特性与Transformer将输入集转化为输出集的特性是一致的(自然语言处理使用位置编码来表示输入标记的顺序,但点云处理不需要这样的顺序不需要信息,只需要点的坐标即可)。)
详情请参考本站的说明文章。
Point Transformer在3D分类和分割任务中表现出优异的性能。
PCT(点云式变压器)
PCT是与Point Transformer并行的研究,它是一个类似的模型,使用Transformer进行3D点云处理。不过,这个和原来的变形金刚架构比较相似。
其架构如下
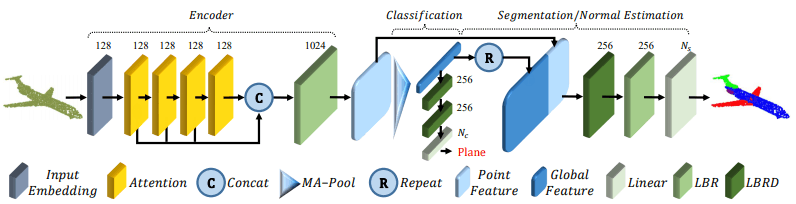
我将根据这个数字来解释。MA-Pool显示的是Max pooling和Average pooling,LBR显示的是Linear层、BatchNorm和ReLU层,LBRD显示的是添加了dropout层的LBR)。
- (1)初始,我们得到一个输入点群$P∈R^{N×d}$。
- (2)通过输入嵌入模块将输入点云转化为$d_e$维的嵌入特征$F_e∈R^{N×d_e}$。输入嵌入模块将在本节后面介绍)。
- (3)$F_e$通过四个Attention模块转换为$F_1,F_2,F_3,F_4$。注意力模块将在后面介绍)。
- (4)将$F_1,F_2,F_3,F_4$进行串联(concat),并通过LBR层转换为特征。此时,点向特征$F_o=concat(F_1,F_2,F_3,F_4)・W_o$以后用于LBR线性层的权重$W_o$。
- (5)通过Max pooling和Average pooling,提取出充分代表点云的全局特征(global feature)$F_g$。
此后,根据下游应用任务的不同,分为两大部分。
- 对于分类任务,全局特征$F_g$经过两次LBRD层,最后经过线性层来预测类。
- 对于分割任务,我们将全局特征$F_g$与点向特征$F_o$进行连接。之后通过LBRD层、LBR层和线性层进行点状分割预测。
大体上可以归纳为以下几点:
- (1)用基于注意力的编码器获得全局和点的特征。
- (2)对于分类任务,采用全局特征。
- (3)对于分割任务,采用全局和点状特征。
在这里,我们简单介绍一下前面省略的Attention模块和Input Embedding模块。
首先,作为一个Attention模块,PCT使用了一种新的方法,叫做Offset-Attention。如下图所示。
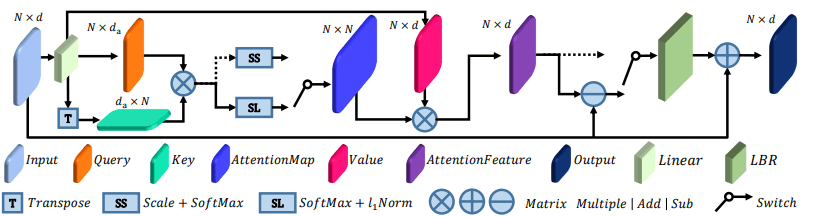
看起来很复杂,但它仍然是一个Attention过程,使用查询$Q$(橙色)、键$K$(蓝绿色)和值$V$(深粉色)。
重要的部分是计算每个元素的输入(Input:浅蓝色)和通过Attention过程获得的特征(AttentionFeature:紫色)之间的差异(Offset)的部分(图中圆圈内有水平线的部分)。
在这种情况下,当输入为$F_{in}$,输出为$F_out$时,通常Attention用下式表示。
$F_{out}=LBR(F_{sa})+F_{in} ( F_{sa}=softmax(\frac{(QK^T)V}{\sqrt{d}}))$。
而另一方面,Offset-Attention则是这样的。
$F_{out}=LBR(F_{in}-F_{sa})+F_{in}$
研究发现,使用Offset-Attention,即对Attention的修改,可以获得更好的表现。
另外,输入嵌入模块如下所示

图的左侧叫邻居嵌入架构。它是为了成功提取局部特征而设计的。
SG代表SG模块(采样和分组),中间的水虚线表示。
这样的过程有效地提取了局部信息密集型特征。
PCT在ModelNet40和ShapeNet数据集上进行了评估,在3D形状分类、法线估计和分割等任务上表现出了优异的性能。
METRO(网状变压器)
该模型旨在从单一的二维图像中重建人类的三维姿势和网格。下面是这个任务的一个例子。

在这种情况下,(a)代表输入图像,(b)代表手关节和网格顶点之间的注意力,(c)代表重建的网格。
对于这项任务,重要的是学习人类关节和网格顶点(例如手和脚)之间的非局部交互,如图(b)所示。
为了捕捉METRO中的这些相互关系,我们使用了如下的Transformer。
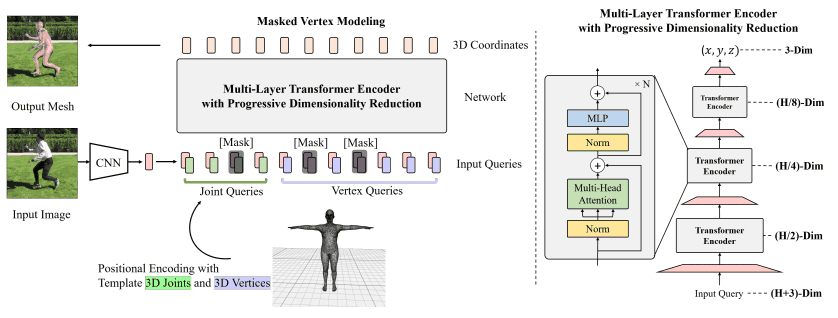
该模型的粗略描述如下:
- (1)给定一个输入图像,用CNN提取图像特征。
- (2)将人体网格模板(图中底部中心)添加到图像特征中。即把每个关节$i$的三维坐标$(x_i,y_i,z_i)$和每个顶点$j$的三维坐标$(x_j,y_j,z_j)$连成图像特征。
- (3)将(2)中得到的关节查询和顶点查询通过图中右侧表示的模块,输出关节和网格的三维坐标。这个变换器架构对特征进行连续的维度减少,以便将2D图像映射到3D网格。
在训练过程中,使用掩模顶点建模(MVM)来恢复掩模输入,类似于BERT的MLM。
METRO在Human3.6M、3D PW数据集上实现了3D人体网格重建任务的SOTA。实际生成的例子(注意力地图网格)如下图所示。

总的来说,我们发现Transformer在3D点云处理方面能力很强。
摘要
在本文中,我们对计算机视觉中的视频理解、低镜头、聚类和变压器间的三维分析任务等相关方法进行了详细的描述。
本文无法介绍的方法,请参考第2、3、4部分的解释,一般解释请参考第1部分。
Transformer不仅应用于自然语言处理,还应用于图像处理、视频处理、三维点云处理等计算机视觉任务,并表现出优异的性能。虽然Transformer还有一些问题需要解决,但改进Transformer的研究正在进行中,我们会持续关注未来的研究。
要阅读更多。
你需要在AI-SCHOLAR注册。
或


与本文相关的类别



![[MusicLM]谷歌开发的文本到音乐生](https://aisholar.s3.ap-northeast-1.amazonaws.com/media/October2023/musiclm-520x300.png)


