用Transformer实现路径预测的SoTA!mmTransformer用于多模式和多样化的路径预测。
三个要点
✔️ 用基于变压器的模型预测车辆路径
✔️ 实现多模式和多样化的预测
✔️ 在路径预测任务中实现SoTA
Multimodal Motion Prediction with Stacked Transformers
Written by Yicheng Liu, JinghuaiZhang, Liangji Fang, Qinhong Jiang, Bolei Zhou
( Submitted on 22 Mar 2021 (v1), last revised 24 Mar 2021 (this version, v2))
Comments: Accepted to CVPR2021.
Subjects: Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI)
code:.

首先
我们假设自动驾驶社会中的安全社会将通过预测包括我们自己在内的周围车辆的未来路径来实现。传统的方法通过改变特征和使用潜在变量对路线的不确定性进行概率建模来产生多个预测候选人。然而,潜在特征集中在数据中经常出现的模式(汽车类型),而且该方法依靠先验知识来生成和选择候选建议。换句话说,有必要设置一个先验分布并设计一个效果良好的损失函数。另一种方法,即基于建议的方法,通过事先建议可能的路径,然后减少或识别正确的路径来预测路径。然而,由于它不是未知路径的启发式方法,因此需要设计者的先验知识,而且多模态预测不能保证只有一个正确的答案数据。
因此,在本文中,我们提出了一个多模式变换器(mmTransformer),使用变换器在多种模式下进行端到端的行为预测。为了在每个独立路径建议的特征层面上实现多模态,我们随机初始化建议,并提出了一个基于堆叠变压器的模型(过去的路径、道路信息、社会互动),以多渠道的背景信息作为输入所提出的模型是基于一个堆叠的变压器。一个基于区域的学习策略被用来继承提案产生的多模态(减少行为预测的复杂性),并在Argoverse数据集(一个行为预测数据集)上进行实验以实现SoTA。我们成功地实现了建议路径的多样化,并提高了准确性。
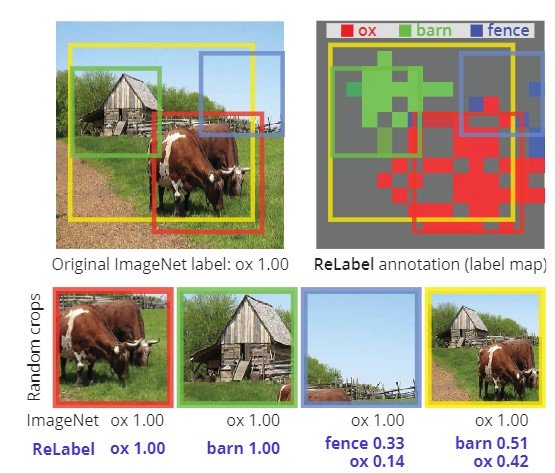
建议的方法:mmTransformer
mmTransformer有两个特点来改善单模态。
- 提出了一个行为预测的路线建议机制
- 基于区域的培训战略(RTS),以确保多模态性
路径建议机制异步收集来自mmTransformer编码器的多通道上下文信息,并将其作为建议路径传递给解码器的查询。这一提议具有独立的、因此是定制的特征,这使路线具有多样性和多模态性。
而在RTS中,周围的空间被划分为若干区域,建议的区域被分组为不同的集合,只有建议路径的集合被应用于可能有正确数据的区域。这样一来,每个提议只能学习一个特定的模式,而不考虑其他模式的提议的潜在特征。
mmTransformer使用堆叠式变压器作为骨干,并从建议的路径中学习上下文信息。解码器(Proposed Feature Decoder)对拟议路径的特征进行解码,并使用轨迹发生器和轨迹选择器输出相应的概率。这里使用的轨迹发生器和轨迹选择器的结构与变压器中使用的前馈网络的结构相同。
叠加式变压器
Transformer以其在连续数据上的高性能而闻名,为了使其适应路线预测的任务,我们需要处理上下文信息。一个直观的解决方案是将所有类型的输入串联起来,如过去的路线和车道信息,并将连续的竞赛编码到转化器中。然而,由于需要给变压器一个固定大小的输入,这种方法将需要巨大的计算能力。此外,由于不同类型的信息被串联起来并输入到注意力层,潜在特征的性质变得很重要。
我们通过将TRANSFORMER解码器中的QUERY处理为路径搜索来解决这个问题。这种方法的优势在于,平行路径建议可以独立地整合来自编码器的信息,并保留每条路径的特征作为分离模式的信息。堆栈的结构是这样的:多个输入可以提供给多个特征提取器,不同的上下文信息可以分层次地整合。特别是在这里,它由三个转化器单元组成:运动提取器、地图聚合器和社会构造器。
运动提取器对目标车过去的路线进行编码,地图聚合器从地图中学习地理和语义信息,如道路的形状,并表示输入的建议路线的特征,而社会构造器表示所有汽车的特征,以学习互动。并代表所有汽车的特征,以学习通过消融研究和逻辑决策,按照运动提取器、地图聚合器和社会构造器的顺序来组织。
解码器
建议路径的特征解码器由路径生成器和路径选择器组成,预测路径使用三层多层感知器生成,用于K目标建议。
基于区域的培训战略
为了保证模型的多模态性,本研究提出了RTS,以防止所提出的路径陷入模式平均问题。模式平均问题是一个输出结果忽略每个模式的问题,这意味着行人在路上行走,汽车也在人行道上行驶。在路上行走的行人或在人行道上行驶的汽车。这个问题的合理解决方案是只用最小的最终位移误差和建议的路径来计算回归损失和分类损失。我们认为这是一个基线。
在这个基线中,存在的问题是,随着确保多样性的拟议路径数量的增加,模式会崩溃。因此,我们提出了一个基于区域的学习策略(RTS),将建议的路径归为几个空间群组。如图所示,在每个场景中,场景被旋转一定的角度来划分区域,轴的中心是汽车在前一个路径中的位置。轴的中心是上一条路线的车的位置。 在不重复地划分场景后,提出K条路线并分配给每个区域,结果每个区域有N个建议。在训练中,我们使用回归损失和分类损失,与基线不同的是,我们计算每个区域内所有建议路径的损失。这样输出的结果可以确保预测路径的多模态性。
目标函数
上述划分正确区域的回归损失在每一步都使用Huber损失,分类损失使用交叉熵损失,这加快了mmTransformer + RTS训练的收敛速度。mmTransformer + RTS的收敛性。每个预测路径的置信度分数是用熵模型的最大值计算的,正确答案和预测路径之间的距离是用L2距离计算的,并使用Kullback-Leibler Divergence作为损失函数。通过使用Kullback-Leibler Divergence作为损失函数,这个距离越近,分数就被设计得越好。
在推理过程中,使用非最大抑制算法(一种在物体检测中经常用于移除提议区域的算法)移除重叠(接近重叠)的路径。
实验设置和结果
为了研究mmTransformer的性能,我们使用了Argoverse行为预测基准,其中有34万张包含5秒路径和上下文信息的图像作为数据集。目标是利用过去2秒的路径和背景作为输入,预测未来3秒的行为。在每种情况下,高清地图中基于中心线的连续线在本地地图中被表示为信息,如图所示。此外,为了建立车与车之间的互动模型,邻近的车和自己的车的过去路径和位置都被表示出来。
模型的评估方法是平均位移误差(ADE)和最终位移误差(FDE)。 为了评估多模态性,将前K(K=6)条路线的失误率(MR)与ADE和FDE的最小值进行比较通过以下方式对结果进行了比较。


实验是在Argoverse数据集的测试集上进行的。首先,我们将提出的方法mmTransformer与mmTransformer+RTS进行比较。表2显示,mmTransformer对minADE和minFDE具有最好的准确性,而加入RTS后MR更低(即预测正确)。建议路线的数量和每条路线的准确性如下。接下来,我们比较了消融研究中的建议路径和每个建议模块的数量。6个没有RTS的建议mmTransformer在minADE和minFDE中都比36个没有RTS的建议mmTransformer有更高的准确性。换句话说,如果我们把输出固定为少量的建议,我们将提前放弃多样性的选择,虽然准确率会提高,但MR会下降。此外,我们发现,当正确答案区域中被选中的提案数量变少时,minADE和minFDE的准确性就会下降。在这项研究中,我们认为,准确性和多样性是一种权衡。

接下来,我们评估了RTS中的空间划分,周围的区域被划分为几个空间。我们已经试验了K-means和手动分割作为分割方法。在人工分割中,该区域被分割成图3所示。训练样本根据数据的平衡被平均分配。与K-means相比,人工分割可以正确地分割模糊的样本,而且由于错误的分割较少,学习的准确性也较高。在这项研究中,我们只对样本进行了平均分割,而且我们还不知道学习的重要分割方法。

在图中,我们可视化了RTS(36个分区)。根据右上角的MR矩阵,单元格$(i, j)$代表预测区域$j$中包含的案例在区域$i$中的建议的MR。我们可以看到,每个提案产生的路径都属于一个预先分配的区域。换句话说,这表明mmTransformer能够通过基于区域的学习来学习不同的模式。
摘要
SoTA是通过在汽车路线预测任务中使用一个变压器来实现的。近年来,人们通常认为使用Transformer作为骨干可以提高准确率,但仅凭Transformer无法处理不同层次的输入,对于使用上下文信息进行路线预测是不够的。然而,仅靠变换器无法处理不同层次的输入,对于使用上下文信息进行路径预测是不够的。 在这项研究中,我们根据不同的信息使用不同的变换器来处理多通道的输入,并将建议的路径划分为不同的区域,以实现包括多模态的路径预测,这在过去一直是一个问题。由于未来的路径是未知的,所以需要多样性,但这是与预测准确性的权衡,在提高预测时间的同时,还需要进一步改进。



与本文相关的类别



![[MusicLM]谷歌开发的文本到音乐生](https://aisholar.s3.ap-northeast-1.amazonaws.com/media/October2023/musiclm-520x300.png)


