一个与模态无关的transformer:Perceiver Model
三个要点
✔️基于跨模态transformer,在多个任务上表现出色
✔️具有处理超过100,000个输入的序列的能力
✔️与ImageNet、AudioSet和ModelNet-40 SOTA模型性能相当或更好。
Perceiver: General Perception with Iterative Attention
written by Andrew Jaegle, Felix Gimeno, Andrew Brock, Andrew Zisserman, Oriol Vinyals, Joao Carreira
(Submitted on 4 Mar 2021)
Comments: Published on arxiv.
Subjects: Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI); Machine Learning (cs.LG); Sound (cs.SD); Audio and Speech Processing (eess.AS)
code:
首先
人类和其他动物处理高维度的多模态信息,如视觉、语言和触觉来感知他们的周围环境。另一方面,神经网络只适合执行它们被训练过的特定任务;CNN已经彻底改变了计算机视觉,因为它们对图像有强烈的归纳偏见。然而,鉴于多模态数据集的规模越来越大,我们很自然地想知道这种偏差是否限制了模型的能力。
在本文中,我们提出了一个感知器模型,它使用相同的基于transformer的架构来处理任意配置的不同模式。我们选择了transformer,因为它们的电感偏差很小,而且具有很强的可扩展性。目前的视觉transformer使用像素网格结构和积极的子采样技术来减少自我注意网络的计算成本。然后我们引入一个新的机制,使我们能够直接和灵活地处理50000像素。
Perceiver的性能可与强大的视觉模型相媲美,如ImageNet的ResNet-50,AudioSet在声音事件分类基准中的最先进性能,以及ModelNet-40在点云分类中的强大性能。
感知者
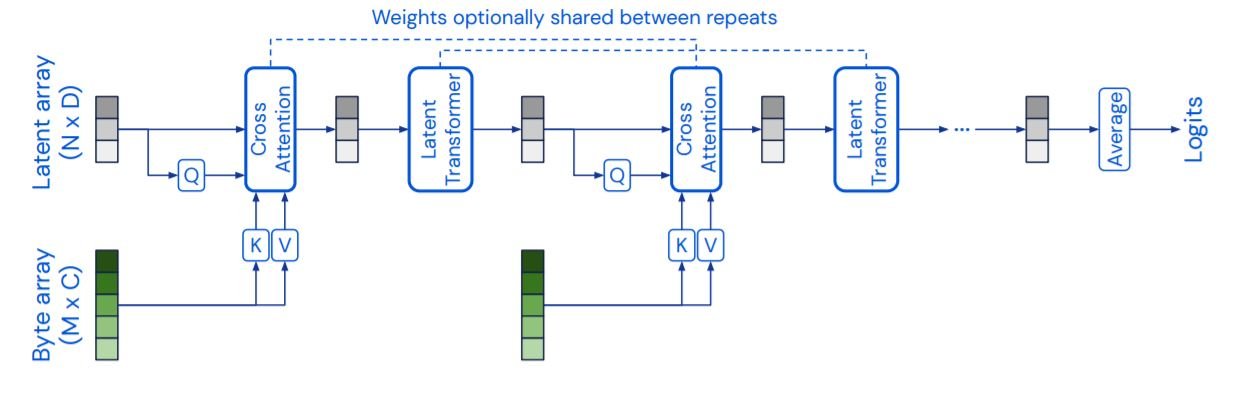
感知器是一个交叉注意和潜在的感应器由两个主要部件组成:交叉注意和电位transformer。交叉关注交叉注意transformer是一个将潜在序列映射到字节序列的transformer。潜伏transformer是一个将潜伏阵列映射到潜伏阵列的transformer塔。字节数组的大小取决于输入类型,对于224x224的图像来说,大约是50176。潜伏数组的大小要小得多,在ImageNet的情况下约为1024。交叉注意层和潜在的变频器一层接一层地交替进行。高维的字节序列被连续投射到低维注意力的瓶颈处,然后变频器然后在由于权重在迭代层之间共享,我们的模型可以被解释为一个RNN。此外,还有注意图层不使用遮罩。
提高自我注意的复杂性
查询(Q)-键(K)-值(V)。自我注意-softmax[(QKT)V] 的复杂性。O(M2)和M是序列长度。这使得处理具有50176像素的图像的较大序列长度是不切实际的。所以为了解决这个问题,我们用交叉注意是用来解决这个问题的。查询(Q)是从一个潜在的序列(NxD)而不是一个字节的输入序列(MxC)中获得。这里,N是一个超参数,通常比M小很多。这将复杂性降低到(MN),并允许M被扩展到更大的值。
而且交叉注意模块只取决于Q网络的输入。这交叉注意层是瓶颈,只减少了潜在的换能器复杂性。O(N2).这使得电位transformer要更深入,而且不使用QKV注意力的近似值,视觉变频器让我们能够在无法接触到的深度学习网络。潜伏转化器是GPT-2模型,N<=1024,潜伏序列使用学到的位置编码。
迭代式关注
瓶颈降低了复杂性,但限制了输入信号的信息流。为了确保模型不遗漏任何必要的细节,不受冗余信号的困扰,Perceiver使用了多个字节关注层。这个字节关注层用于每个交叉注意层迭代地从每个交叉注意层之前的输入序列中提取信息,并根据需要将其保存在一个潜伏阵列中。为了进一步提高模型的效率,交叉注意在ImageNet的实验中,参数共享将参数的数量减少了10倍。
位置编码
自我关注操作是变异的,感知器模型没有能力像CNN那样利用输入数据的空间关系。因此,我们对输入序列使用参数化傅里叶特征的位置编码。这种编码被称为[孽(fk.pi.xd),cos(fk.pi.xd)],它的值可以是在这里,频率fk是在1和µ/2之间对数线性排列的频率库的第k个频段。xd是沿dth维度的输入位置的值(例如,d=2用于图像,d=3用于视频)。我们发现,与其将位置嵌入添加到图像特征中,不如将它们串联起来,以提高性能。这是由于NLP模型的输入特征的维度要大于本研究中使用的模式(图像、视频和音频)。
这些基于特征的位置编码允许模型学习如何利用位置依赖关系。只要已知输入的维度相对较小,它们就可以很容易地适用于各种领域。此外,它们可以在多模态环境中使用。每种模式都可以根据其维度使用单独的位置编码,而分类位置编码可以用来区分领域。
实验和评估
将进行一些实验来比较模型,如Perceiver和ResNet-50、ViT-B和Transformer堆栈在三个不同领域:视觉、声音和语音以及点云。
图像:ImageNet
首先,我们在ImageNet分类任务中测试Perceiver。位置编码是使用224x224输入作物的(x,y)位置生成的。在生成位置特征之前,(x,y)坐标被归一化为作物的每个维度的[-1,1]范围。庄稼我们发现,如果用图像的坐标代替作物的坐标,就会出现过度拟合。庄稼导致位置和长宽比的增加,并阻止模型在RGB值和位置特征之间进行关联。
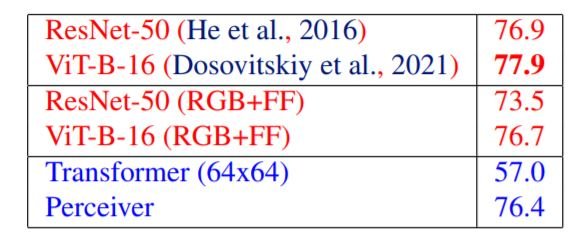
如上表所示,在ImageNet中,我们的模型与SOTA模型的表现一样好。当用位置性傅里叶特征(RGB+FF)训练基线模型时,性能稍差。我们不得不在测试前将图像降采样为64x64,因为转换器不能处理224x224的长序列。
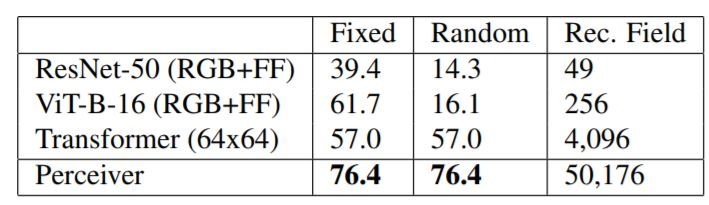
接下来,我们使用ImageNet的包络版本来评估该模型。首先,我们对所有图像使用一个单一的排列组合(固定),然后对所有像素进行随机排列(随机)。变形器和感知器不受影响,但使用网格结构的ResNet-50和ViT-B却受到了破坏:既然有二维网格结构,人们可能会问为什么不使用它?这个实验说明了在某些模式和跨模式下使用CNN和ViT的挑战。例如,将点云转换为二维网格是很复杂的,如何将音频和视频的组合表示为一个网格?
声音和音频: AudioSet
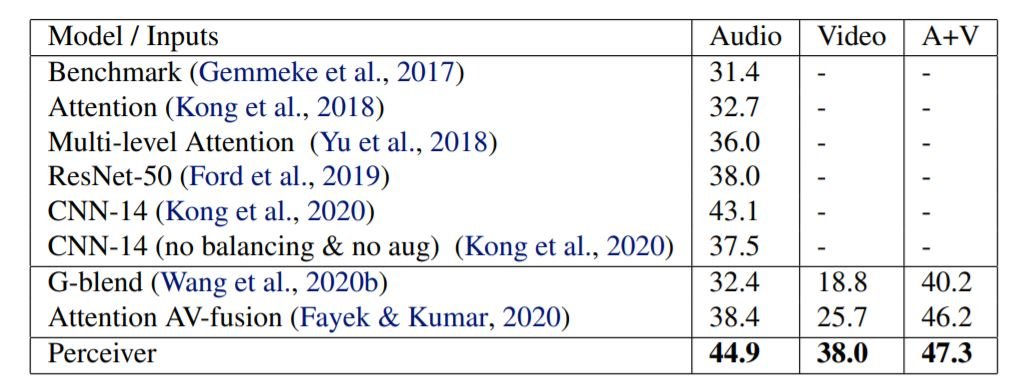
Perceiver也在AudioSet数据集上进行了测试。这个数据集是一个大型数据集,包括1.7M个长度为10秒的训练视频和527个类别。如上图所示,Perceiver在音频、视频和A+V分类任务上的表现优于其他SOTA模型。 音频的采样频率为48kHz,在1.28s的视频上有61,400个输入。傅里叶特征被用于音频的振幅轴以及时间轴。
对于视频,我们使用了一个2x4x4几何形状的边界框,将32帧的片段降格为256x256像素,总共有65,536个输入。如果不进行下采样,输入序列将是32x256x256,即大约200万个输入,但该模型可以工作,尽管很慢。
在音频+视频(A+V)的情况下,这些序列被串联起来。连接额外的特定模式的学习嵌入,使音频输入的尺寸与视频输入的尺寸相同。
点云:ModelNet40
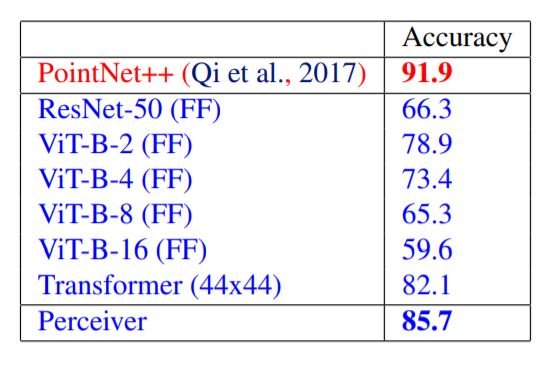
ModelNet40是一个从三维三角网中得到的点云数据集,给定三维空间中2000个点的坐标,该模型从40个人工类别中做出预测。在这里,每个点云被随机放置在一个二维网格上,并被送入模型;Perceiver的表现优于ViT和ResNet,但没有击败特定领域的PointNet++。然而,应该注意的是,PointNet++使用了先进的数据增强和特征工程技术。
摘要
感知器架构能够处理超过10万个向量的输入序列。这使得同一个感知器模型可以在不同的模式下使用,只需稍作重新配置即可。尽管如此,这个模型不能灵活地处理任意的输入,因为它使用了特定领域的位置编码输入和数据增强。是否有可能消除这些特定领域的假设是未来研究的一个课题。



与本文相关的类别



![[MusicLM]谷歌开发的文本到音乐生](https://aisholar.s3.ap-northeast-1.amazonaws.com/media/October2023/musiclm-520x300.png)


