语言抑制transformer对非语言任务很有用!
三个要点
✔️ 微调语言模型以执行视觉和蛋白质折叠预测等领域的任务。
✔️ 在特定任务的数据集上,表现得比完全训练transformer更有竞争力或更好。
✔️ 在各种领域中,比随机权重初始化更高效,学习速度更快,性能更好。
Pretrained Transformers as Universal Computation Engines
written by Kevin Lu, Aditya Grover, Pieter Abbeel, Igor Mordatch
(Submitted on 9 Mar 2021)
Comments: Accepted to arXiv.
Subjects: Machine Learning (cs.LG); Artificial Intelligence (cs.AI)
code:
首先
transformer架构在以下几个领域一直处于技术进步的前沿:T?变形器已被用于各种任务,包括视觉(对象检测、实例分割)、NLP(情感分析、语言建模)和视觉+NLP(视觉关联、视觉答题)。最近,一个单统一变形(UniT)模型的性能已被证明与微调的特定任务模型一样好。
一般的趋势是在大型数据集上训练大型模型,然后针对较小的特定任务数据集对模型进行微调。例如,在庞大的文本数据语料库上预先训练的GPT模型可以在情感分析数据集上进行微调。如果使用来自不同领域(如视觉)的数据集对模型进行微调,那么在大型文本数据语料库上预先训练的模型是否也同样有效,这将是非常有趣的。
T变形器 该自觉性层,我们假设它可以在一个富含无监督训练数据的领域(如NLP)中进行预训练,然后进行微调,在不同的领域(如视觉)中表现得非常好。具体来说,对于一个预训练的GPT-2模型,如果只有0.1%的模型是微调的(Frozen Pretrained Transformer),那么完全微调的变电 和LSTMs也可以执行。
模型

使用GPT-2模型,嵌入尺寸/隐藏尺寸为n昏暗和层数为n层次而输入维度为d在而输出尺寸为d出且最大序列长度为l。自觉性参数被冻结,只有以下参数会根据任务进行微调。
1)输出层:输出维度是一个简单的线性层,其冻结了自觉性层被最小化,以确保它能执行最多的任务。对于分类任务,输出维度等于类数。例如,对于CIFAR-10来说是10,线性层的权重矩阵的维度为768x10。
2)输入层:不同数据集的输入数据的维度不同,需要进行微调。同样,一个简单的线性层被用来计算冻结的。自觉性层,使冻结的自我注意层更加复杂。线性层的权重矩阵尺寸为n在xn昏暗即在CIFAR-10的情况下,16×768。
3)图层归一化参数:作为标准做法,我们对图层归一化图层的尺度和偏置参数进行微调,在GPT-2中,每个图块有两个图层规范,共为4 × n昏暗 × n层次 参数=4×768×12=36684。
4)位置信息嵌入:。我们的实验表明,位置嵌入在不同模式下是非常相似的。不过,微调一下也是有益的。位置嵌入的尺寸为lxn昏暗并且在CIFAR基础模型的情况下有64×768=49512个参数。
在CIFAR-10基础模型中,这些参数仅占GPT-2模型总量的0.086%,占GPT-2 XL模型的0.029%。
评估
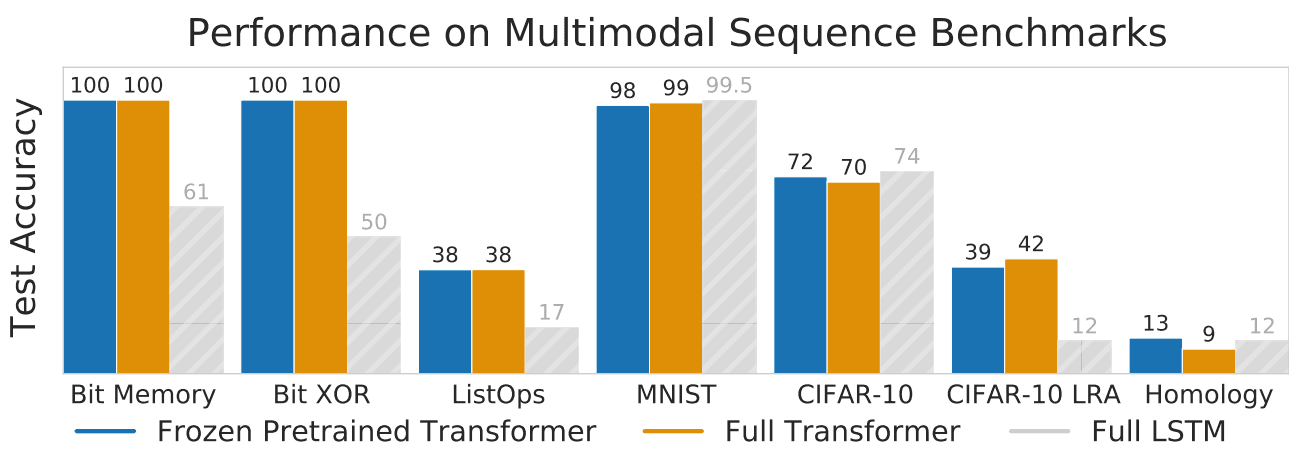
该模型在不同领域的任务上进行了评估。具体来说,它已经在以下任务上进行了评估:位内存(存储1000位长位序列的任务)、位XOR、ListOps(预测列表运算结果的任务)、MNIST、CIFAR-10、CIFAR-10 LRA(具有较长输入序列的长距离竞技场基准CIFAR-10)。修改),以及远程同源检测(预测蛋白质褶皱的任务)。

冷冻自觉性参数微调模型称为冷冻预训练换能器(FPT)。除此之外,我们还为任务训练了一个LSTM模型和另一个完全训练好的变换模型(Full)。所有任务的结果如上表所示。在所有任务中,FPT的表现都优于或优于全transformer和LSTM。
对于Bit XOR和Bit Memory任务,当序列长度为5时,FPT实现了100%的精度。换句话说,我们能够恢复完整的序列。我们还发现,即使对于大到256的序列长度,我们也能恢复精确的算法。由此可见,与LSTM相比,FPT具有更大的内存。
当数据集较小时,我们发现很难完全训练12层的变换模型,因为它可能不稳定,容易过度拟合;对于CIFAR-10模型,我们发现3层模型是合适的。 发现CIFAR-10模型适合做三层模型。全transformer的情况下,会产生额外的调整模型大小的问题。相反,我们发现FPT的性能随着模型大小的增加而提高。
先前学习模式的重要性
在这里,我们看看如何改变先前学习的模式(口头、视觉、随机、记忆)影响FPT跨任务的表现。

该模型自觉性在1)ImageNet数据集上预训练的ViT transformer的参数。自觉性ViT transformer的参数,预训练了1)ImageNet数据集,2)随机初始化,3)位内存任务预训练模型的。自觉性参数。上表的结果显示了语言预训练的有效性:FPT在MNIST(视觉)数据集上的表现优于ViT,而令人惊讶的是,在随机数据集上,它在所有任务上的表现都明显优于ViT。另一方面,ViT几乎只在视觉任务上胜过随机初始化,在同源性上最差。
通过预学习语言提高计算效率

从上表可以看出,FPT收敛速度比随机初始化快,而且节省计算资源。
通过对语言的预习,防止过度适应。

其他两个t变形器(Vanilla Transformer和Linformer)由于数据集中的实例数量较少(上表中CIFAR-10 LRA的实例数量为5万个)而出现过拟合,而FPT则不易出现过拟合,且对验证数据有很好的泛化作用。观察到FPT模型对验证数据有很好的泛化作用。另外,FPT模型对数据的拟合度往往不足,因此增加模型的容量可以提高其性能。

你要不要微调你的转发层和关注层?
在对前馈层进行微调后,我们观察到CIFAR-10、Homology和MNIST数据集的性能有所提高,但根据之前的研究,在训练过程中可能会出现分歧。注意,层,即使是在微调了微调注意力和前馈层都没有效果。

摘要
大规模的实验表明,在大量的文本数据语料库上对预训练的语言模型进行微调,可以提高模型在各种任务上的性能。语言学习可以导致自觉性层可以学习对任意数据序列的有用表示。这就使其无需对整个网络进行昂贵和耗时的微调。随着更大数据集的开发(如最近的维基百科图像文本-WIT数据集),未来还可以探索其他数据丰富的模式(更大的视觉数据集、视觉-文本数据集-WIT)。



与本文相关的类别



![[MusicLM]谷歌开发的文本到音乐生](https://aisholar.s3.ap-northeast-1.amazonaws.com/media/October2023/musiclm-520x300.png)


