CNNやTransformerは人間の視覚と比べてどうなのか?
3つの要点
✔️ TransformerとCNNを人間の視覚と比較
✔️ ニューラルネットワークと人間の視覚を比較するための新しい指標を紹介
✔️ ViTとCNNの形状/テクスチャーの偏りを人間の視覚と比較
Are Convolutional Neural Networks or Transformers more like human vision?
written by Shikhar Tuli, Ishita Dasgupta, Erin Grant, Thomas L. Griffiths
(Submitted on 15 May 2021)
Comments: Accepted at CogSci 2021
Subjects: Computer Vision and Pattern Recognition (cs.CV)
code:
はじめに
畳み込みニューラルネットワーク(CNN)は、画像分類、セグメンテーション、物体検出などのコンピュータビジョンのタスクにおいて、現在の主流となっています。さらに近年ではself-attentionベースのtransformerも効果的であることも示唆される研究が出てきました。そのため、将来的にはCNNに取って代わるのではないかと言われています。
CNNは人間の視覚野に似ているところがあります。各画像パッチに同じ重みが使われるため、位置普遍性です。とはいえ、局所的な接続性はグローバルなコンテクストの喪失につながるため、これらのモデルは形状ではなくテクスチャに依存すると言えます。逆に人間は画像を認識する際に、テクスチャではなく形状を利用します。このあたりについても、AI-SCHOLARで既に取り上げられています「CNNは本当にテクスチャ好きなのか?」。一方ViTのようなトランスフォーマーは、誘導バイアスが排除されているため、グローバルな特徴も効果的に捉えることができます。また、CNNよりも柔軟性が高いため、NLPと視覚の両方で大きな成功を収めています。この論文の目的は、Cohen's Kappa、Shape biasなどの既存の指標と、クラスごとやクラス間のJS距離などの新しい指標を使って、ViTとCNNが人間の画像認識にどれだけ近いかを調べることです。
誤差の整合性を測定
モデルの精度は、どのモデルが優れているかを比較することはできますが、モデルがどのような間違いをしているのかを理解するのには役立ちません。
システムは、物事の分類を間違える方法に違いがあります。2つのシステムがどのように分類を間違えるかという点で類似性を測定するには、単純に個々の軌跡のうちいくつが同じであるかを考えればよいです。これが、2つのシステムの一致度を測る観測誤差オーバーラップです:cobs(i,j) = e(i,j)/n
ここで、pcorrectの精度で分類するシステムを考えてみましょう。これは、二項分布から無作為にサンプリングすることと同じです。このような2つのモデルは、pcorrectが大きくなるにつれて、観測される誤差の重なりが大きくなります。期待されるオーバーラップは、cexp(i,j) = pipj + (1-pi)(1-pj)で与えられます。この値を正規化に用いると、誤差の整合性は次のように計算できます。
Ki,jはCohen's kappaと呼ばれ、人間とニューラルネットワークの比較に使用できます。しかしCohen's kappaを使って、分類の違いがどこにあるのかを解釈することは困難です。
混同行列は、どのクラスがどれだけ分類され、誤分類されたかという情報で構成されています。しかし、ImageNetのような1000クラスのデータセットでは、非対角要素は非常に疎であり、この1000×1000の行列を埋めるだけの十分な人間データを集めることは困難です。そこで、1000個のクラスを16個のカテゴリにクラスタリングし、得られた混同行列を評価することにします。各クラスの要素が誤って分類された回数(ei)を計算し、エラーの正味数で正規化することにより、クラスC上のエラー確率分布を作成します。

次にJensen-Shannon (JS) 距離を測定します。これはKL ダイバージェンスをより対称的に、より平滑化したものです。JS距離が低い2つのモデルは、似たような誤分類をします。またJSスコアは精度に依存しません(mは2つの分布の点ごとの平均値)

下図のようにどのクラスがどれだけ誤分類されたかを計算することで、クラスごとのJS距離も計算します。この場合のeiは、混同行列の各列を合計して求めます。実験的にクラスごとのJS距離は、cohen's kと逆相関することがわかっています。

さらにクラス間JS距離は、混同行列(CM)の非対角要素のエラーカウントを用いて計算します。クラス間JS距離は、さらに細かい類似性の指標で、任意のクラス 'i' が他のクラス'j' と混同する確率(i,j∈C)を考慮して算出します。実験の結果、クラス間JS距離はcohen's kと無相関であることがわかっています。
![]()
比較結果
人間の予測値と、いくつかのCNN(ResNet、AlexNet、VGG)、Transformer(ViT)の誤差の整合性を比較します。これらのモデルは、Stylized ImageNetデータセット(SIN)で評価されます。

上のように、このデータセットでは、テクスチャベースのstyle transferを使って、テクスチャと形状の対立を発生させています。この特徴を利用して、モデルがどれだけ形状/テクスチャに偏っているかを計算することができます。その結果を以下に示します。
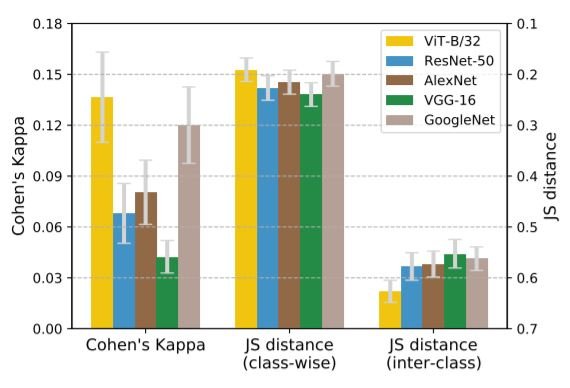
上の図は、SINデータセットのエラー一貫性の結果を示しています。JS距離は、Cohen's Kとのパターンの類似性を強調するために、大きさが小さい順にプロットされています。また、JS距離が小さく、Cohen's Kが大きいほど、人間とのエラー一貫性が高いことを示しています。
Cohen's KとクラスごとのJS距離を考慮すると、ViTは人間と同じようなミスをしていることがわかります。ViTのクラス間JS距離はCNNよりも大きい。つまり、各クラスがどれだけ誤分類されているか(クラス間JS)を見ると、ViTは人間に近いのです。一方で、各クラスがどれだけ他のクラスに誤分類されているか(クラス間JS)を見ると、CNNと人間の方が近いように見える。論文ではクラス間JS距離に基づいてViTがより人間に近いと強調されているが、クラス間JS距離はより細かい指標であり、無視することはできない。次のセクションでは、人間の視覚とニューラルネットワークの類似性を示すもう一つの指標である「形状バイアス」を比較します。
形状バイアス
人間は形状バイアスがあります。つまり、通常物体の識別には、その質感よりも形状を使用します。同様にモデルの場合、形状バイアスは「形状と質感のどちらか一方の予測が正しかった試行において、モデルが形状を正しく予測した割合」と定義されます。SINデータセットでの結果は、モデルがテクスチャに偏っているか、形状に偏っているかを評価するために使用されました。下図は、異なる物体カテゴリに対する各モデルの形状ベースとテクスチャベースの判断の割合を示しています。
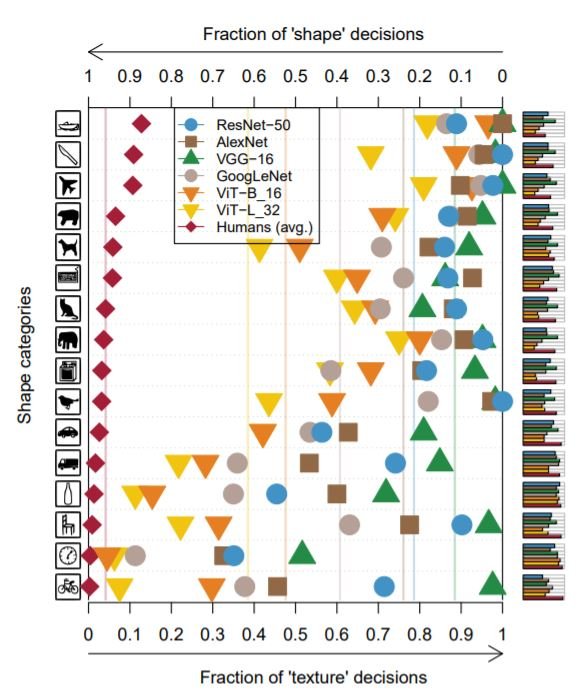
すべてのカテゴリにおいて、ViTはCNNと比較して人間のバイアスに近いことがわかります。形状バイアスの計算では、形状やテクスチャの予測が正しく行われた場合を全体として考慮しています。そのためこれらの結果は、ViTのクラスごとのJS距離の値が低いという先ほどの観察結果と一致しており、クラスごとの誤分類も全体として考慮しています。つまり形状バイアスには、完全な誤差分布からの情報(各クラスがどれだけ他のクラスに誤分類されているか)は含まれていません。この結果が以前にクラス間のJS距離で示唆されたこと、つまりCNNのほうが人間に近いということと矛盾しているのも説明がつく。
Data AugmentationによるFine-Tuning
色の歪み、ノイズ、ブラーなどの単純なデータ増強は、モデルのテクスチャバイアスを大幅に減少させ、ランダムな切り出しなどの増強は、テクスチャバイアスを増加させることが判明しています。ImageNetデータセットにおいて、データ増強(回転、ランダム切り出し、Sobelフィルタリング、ガウスブラー、色歪、ガウスノイズ)を用いてすべてのモデルをfine-tuningし、それらに対して誤差整合性分析と形状バイアス分析を行った。
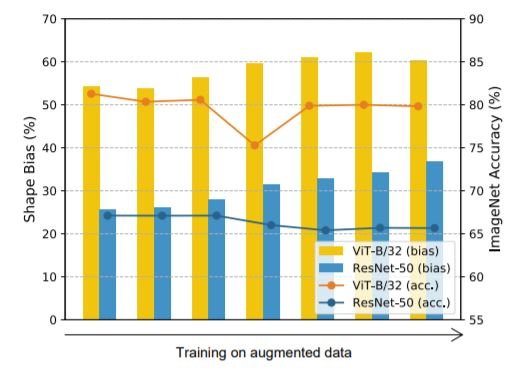 データ拡張による形状の偏りの変化
データ拡張による形状の偏りの変化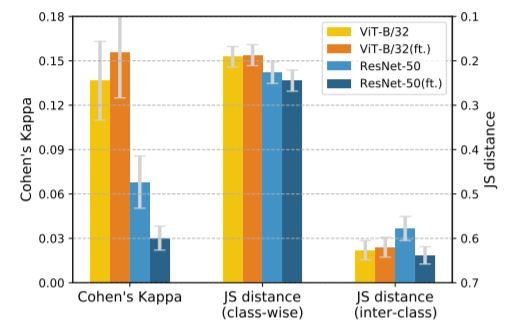 誤差 tuning前とtuning後の整合性(ft.)
誤差 tuning前とtuning後の整合性(ft.)
ResNetsとViTの両方で、データ増強を使用すると、形状の偏りが大きくなることが分かった。ViTのエラー一貫性は、fine-tuningによってわずかに改善されました。 逆に、CNNの形状バイアスは増加しますが、ResNetsのエラー一貫性はfine-tuningによって驚くほど低下します。また、クラス間JS距離とクラスごとのJS距離はともにわずかに増加することがわかった。これは、エラー一貫性と形状/テクスチャ・バイアスがともに人間の視覚への類似性を示す指標である一方で、それらは固定的な関係ではないことを示している。Fine-tuningの際には、ViTでは正の相関、CNNでは負の相関があるようです。
まとめ
本論文では、人間の視覚とさまざまなニューラルネットワークアーキテクチャとの相関関係を確立しています。この論文で紹介されているメトリクスは、この相関関係を細かく測定するのに役立ちます。モデル間のコンセプトレベルの類似性を測定するために、JS距離メトリックを拡張することもできます。さらなる注意が必要な曖昧な結果として、CNNのクラス間JS距離が低いことが挙げられます。一方で、CNNの形状/テクスチャのバイアスは、ViTほど人間と一致していない。むしろViTの方が人間のように形状に偏りがあることがわかりました。人間に近いモデルを開発することで、より効率的で正確なモデルができるのではないかと期待しています。





この記事に関するカテゴリー






