CNN和Transformer与人类视觉相比如何?
三个要点
✔️比较Transformer和CNN与人类视觉
✔️引入了一个新的衡量标准,用于比较神经网络和人类视觉。
✔️将ViT和CNN的形状/纹理偏向与人类视觉进行比较
Are Convolutional Neural Networks or Transformers more like human vision?
written by Shikhar Tuli, Ishita Dasgupta, Erin Grant, Thomas L. Griffiths
(Submitted on 15 May 2021)
Comments: Accepted at CogSci 2021
Subjects: Computer Vision and Pattern Recognition (cs.CV)
code:
首先
卷积神经网络(CNN)已经成为当前计算机视觉任务的主流,如图像分类、分割和物体检测。此外,最近的研究表明,基于自我注意的转化器也是有效的。因此,据说它可能在未来取代CNN。
CNN在某些方面与人类视觉皮层相似。它们是位置通用的,因为每个图像补丁都使用相同的权重。尽管如此,可以说这些模型依靠的是纹理,而不是形状,因为局部连接会导致全局背景的丧失。相反,人类使用形状,而不是纹理,来识别图像。这个领域在AI-SCHOLAR中已经有所涉及,"CNN真的喜欢纹理吗?.另一方面,像ViT这样的变压器也能有效地捕捉全局特征,因为诱导的偏压被消除了。它们也比CNN更灵活,在NLP和视觉方面都取得了巨大的成功。本文的目的是研究ViT和CNN与人类图像识别的接近程度,使用现有的指标如Cohen's Kappa、Shape bias和新的指标如每类和类间的JS距离。
衡量错误的一致性
模型的准确性可以帮助你比较哪些模型更好,但它不能帮助你了解模型犯了什么错误。
系统在对事物进行错误分类的方式上有所不同;为了衡量两个系统在错误分类方面的相似性,我们可以简单地考虑它们有多少条单独的轨迹是相同的。这就是衡量两个系统之间一致程度的观测误差重叠:。cobs(i,j)= e(i,j)/n
其中p正确的让我们考虑一个系统,其分类的准确度为这等同于从二项分布中随机抽样。两个这样的模型是p正确的变得更大,观察到的误差的重叠度也会增加。预期的重合度由以下公式给出cexp(i,j)= pipj+ (1-pi)(1-pj)由以下公式得出使用这个值进行归一化,误差的一致性可以计算为
Ki,j被称为Cohen's kappa,可用于比较人类和神经网络。然而,使用Cohen's kappa,很难解释分类的差异在哪里。
混淆矩阵包括关于哪些类别已经被分类以及有多少被错误分类的信息。然而,在像ImageNet这样的1000级数据集中,非对角线元素非常稀疏,很难收集足够的人类数据来填充这个1000x1000的矩阵。因此,我们决定将1000个类聚成16个类别,并评估所产生的混淆矩阵。每个类别的元素被错误分类的次数(ei),并通过错误的净数对其进行归一化处理,形成C类的错误概率分布。

然后我们测量Jensen-Shannon(JS)距离,这是KL发散的一个更对称、更平滑的版本。这是一个更对称、更平滑的KL分歧版本;两个JS距离较低的模型会出现类似的错误分类。JS的得分也与准确性无关(m是两个分布的每一点的平均值)。

如下图所示,通过计算哪些类被误分类以及误分类的程度,我们还计算了每个类的JS距离。在这种情况下ei是通过对混淆矩阵的每一列进行求和得到的。实验发现,每类JS距离与Cohen's k

此外,类间JS距离是用混淆矩阵(CM)的非对角线元素的错误计数来计算的。类间JS距离是一种更精细的相似性测量,它对任何类的计算都是如此'i' 类似于另一个类'j'. 和混淆的概率与(i,j∈C)在计算中考虑到了。实验结果表明,类间JS距离与cohen's k不相关。
![]()
比较结果
我们将人类预测的一致性与几个CNN(ResNet、AlexNet、VGG)和Transformer(ViT)的错误进行比较。这些模型在Stylized ImageNet数据集(SIN)上进行了评估。

如上所示,在这个数据集中,基于纹理的风格转换来产生纹理/形状冲突。利用这一特征,我们可以计算出模型对形状/纹理的偏重程度。结果显示如下。
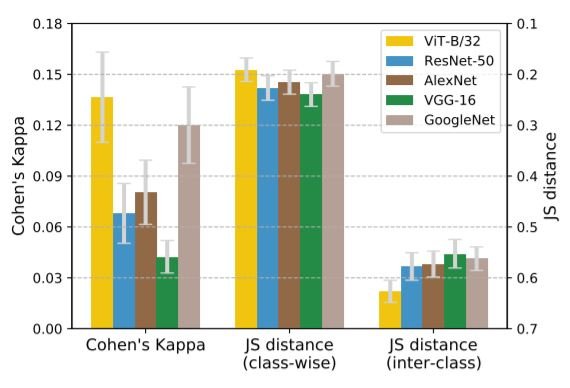
上图显示了SIN数据集的误差一致性结果,其中JS距离按大小顺序递减绘制,以突出与Cohen's K相似的模式。JS距离越小,Cohen's K越大,与人类的误差一致性越高。
考虑到Cohen's K和每类的JS距离,我们可以看到ViT犯了和人类类似的错误;ViT的类间JS距离比CNN的大。换句话说,当我们看每个类别被错误分类的程度(类间JS)时,ViT与人类相似。另一方面,如果我们看一下每个类被错误地分类到其他类的程度(类间JS),CNN和人类似乎比较接近。虽然本文强调ViT在类间JS距离的基础上更像人类,但类间JS距离是一个更精细的指标,不能忽视。在下一节中,我们比较了形状偏差(Shape Bias),这是人类视觉和神经网络之间相似性的另一个衡量标准。
形状偏向
人类有一种形状偏见。也就是说,我们通常使用物体的形状来识别它,而不是它的纹理。同样地,对于模型来说,形状偏差是模型正确预测形状的试验在正确预测形状或纹理的试验中所占比例。在SIN数据集上的结果被用来评估模型是否有纹理偏向或形状偏向。下图显示了每个模型在不同物体类别中基于形状和纹理的决策的百分比。
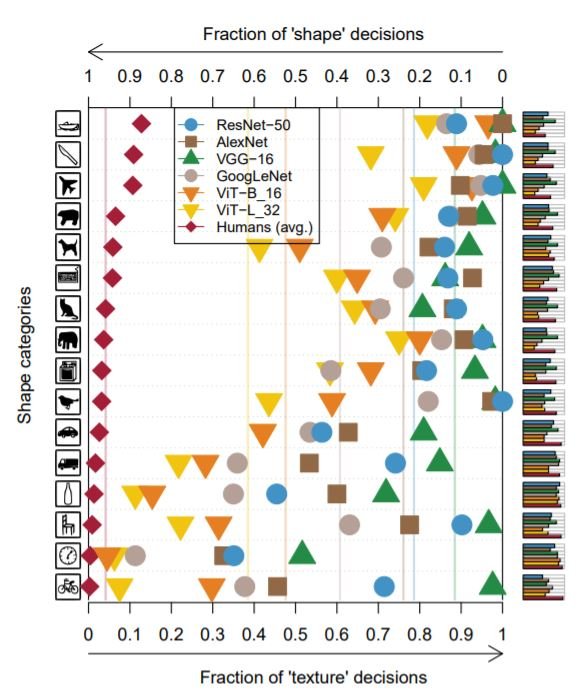
在所有类别中,我们发现ViT比CNN更接近人类的偏见。在计算形状偏差时,我们考虑的是正确预测形状和纹理的总体情况。因此,这些结果与早先观察到的ViT中每类的JS距离值较低是一致的,这也考虑到了每类的错误分类的整体性。换句话说,形状偏差不包括全部误差分布的信息(每个类别有多少被误判为其他类别)。这也解释了为什么这一结果与之前的JS类间距离所暗示的内容相矛盾,即CNN更像人类。
用数据增量进行微调
人们发现,简单的数据增强,如颜色失真、噪声和模糊,可以显著减少模型的纹理偏差,而随机裁剪等增强则会增加纹理偏差。在ImageNet数据集中,数据增强(旋转、随机裁剪和索贝尔滤波、高斯模糊、颜色失真、高斯噪声)微调了所有模型,并对它们进行了误差一致性分析和形状偏差分析。
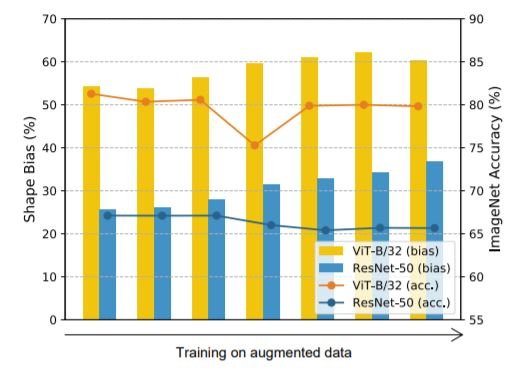 由于数据扩展导致形状偏差的变化
由于数据扩展导致形状偏差的变化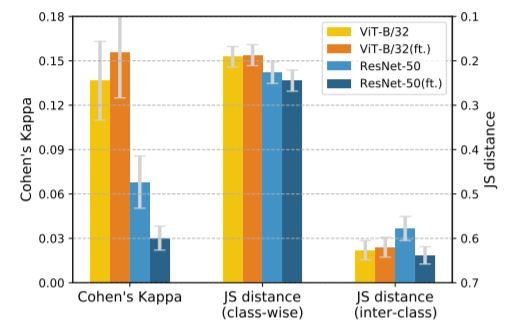 误差 调整前和调整后的一致性(英尺)。
误差 调整前和调整后的一致性(英尺)。
对于ResNets和ViT,我们发现使用数据增量会增加形状偏差;ViT的误差一致性通过微调而略有改善。 相反,CNN的形状偏差增加,但ResNets的错误一致性却通过微调而惊人地减少。我们还发现,类间JS距离和每类JS距离都略有增加。这表明,虽然误差一致性和形状/纹理偏差都是衡量与人类视觉相似性的标准,但它们不是固定的关系;在微调过程中,它们对ViT来说似乎是正相关的,对CNN来说是负相关的。
摘要
本文建立了人类视觉和各种神经网络架构之间的关联。本文提出的衡量标准可以帮助详细衡量这种关联性。JS距离指标也可以扩展到测量模型之间的概念级相似度。一个值得进一步关注的模糊的结果是CNN的低类间JS距离。另一方面,CNN的形状/纹理偏向并不像ViT那样与人类一致。相反,我们发现ViT有一个更像人类的形状偏向。我们希望通过开发一个更接近人类的模型,我们可以使其更加高效和准确。



与本文相关的类别



![[MusicLM]谷歌开发的文本到音乐生](https://aisholar.s3.ap-northeast-1.amazonaws.com/media/October2023/musiclm-520x300.png)


