![[MusicLM] Text-to-Music Generation Model Developed By Google.](https://aisholar.s3.ap-northeast-1.amazonaws.com/media/October2023/musiclm.png)
[MusicLM] Text-to-Music Generation Model Developed By Google.
3 main points
✔️ Generating high-quality music from text prompts
✔️ A project that brings together Google's accumulated wisdom
✔️ MusicCaps, a paired text and music data set
MusicLM: Generating Music From Text
writtenby Andrea Agostinelli, Timo I. Denk, Zalán Borsos, Jesse Engel, Mauro Verzetti, Antoine Caillon, Qingqing Huang, Aren Jansen, Adam Roberts, Marco Tagliasacchi, Matt Sharifi, Neil Zeghidour, Christian Frank
(Submitted on 26 Jan 2023)
Comments: Supplementary material at this https URL and this https URL
Subjects: Sound (cs.SD); Machine Learning (cs.LG); Audio and Speech Processing (eess.AS)
code:
The images used in this article are from the paper, the introductory slides, or were created based on them.
Introduction
In this study, MusicLM, a Text-to-Music generative AI published by Google, was developed. In this model, for example, given the following text prompt
It is fast-paced and upbeat, with a catchy electric guitar riff. The music is repetitive and easy to remember, but with unexpected sounds, like cymbal crashes or drum rolls.
MusicLM takes such text as input and generates music according to that text. The fact that it can generate even specific text, such as the above, is very attractive. The actual music generated by MusicLM can be heard on the following page.
The quality is very high.
The secret to generating such high-quality music is the accumulation of past research by Google, which, as one of the world's leading companies, has naturally produced a great deal of research results.
In this study, we are making full use of the results of those studies. Let's take a look at what kind of research is being utilized in the next section.
Technique
Let's look at the model structure of this study by reviewing prior Google research.
Elements
The components of the MusicLM model are as follows

From left to right are SoundStream, w2v-BERT, and MuLan. These three are originally independent pre-trained models for expression learning. The above three are combined to generate music as shown in the following image. 
The text "Hip hop song with violin solo" in the lower right corner of the above figure is the prompt, and the waveform "Generated audio" above it is the generated music.
There are various symbols, such as A and S, which will be explained in detail in the following sections. First, let's look at each of the components in turn.
・SoundStream
SoundStream is a "neural codec" for audio data compression. The technology consists of two parts: an "encoder" that converts voice and music into very small chunks of information, and a "decoder" that converts that small information back into the original voice and music.

SoundStream: An End-to-End Neural Audio Codec
In SoundStream, the "input waveform" and the "waveform output by the Decoder" are trained end-to-end to be equal. In inference, the data compressed by the Encoder and RVQ is sent to the Receiver, which passes the received data through the Decoder and outputs it as audio.
SoundStream's greatest advantage is its ability to deliver high-quality voice even with very low data volumes. For example, if your Internet connection becomes unstable during a call, SoundStream can automatically adjust the data volume to maintain call quality.
MusicLM is primarily responsible for "outputting the generated audio," and SoundStream allows us to output high-quality audio in an efficient manner.
・w2v-BERT
w2v-BERT is a "base model for speech recognition systems" to extract meaning from speech. w2v-BERT was developed by Google and combines "speech understanding technology" with "sentence understanding technology." w2v-BERT extends the wav2vec 2.0 technology from prior research, It also incorporates contrastive learning and MLM.
The model structure is as follows

w2v-BERT consists of the following three modules
- Feature Encoder: Compresses input audio and outputs latent representation
- Contrastive Module: Learns "context before and after speech" through contrastive learning
- Masked Prediction Module: Mask estimation also used in BERT
In this way, speech can be converted more accurately into linguistic meaning, and MusicLM is primarily responsible for connecting the "prompt text" and the "output music".
・MuLan
MuLan is a "contrastive learning model" that links relevant text data with music data. This is another Google study, a multimodal model that links "music" with relevant "text". It uses contrastive learning so that the distance between the Embedding of the music data and the Embedding of the text data is learned to be close.
The study method is as follows
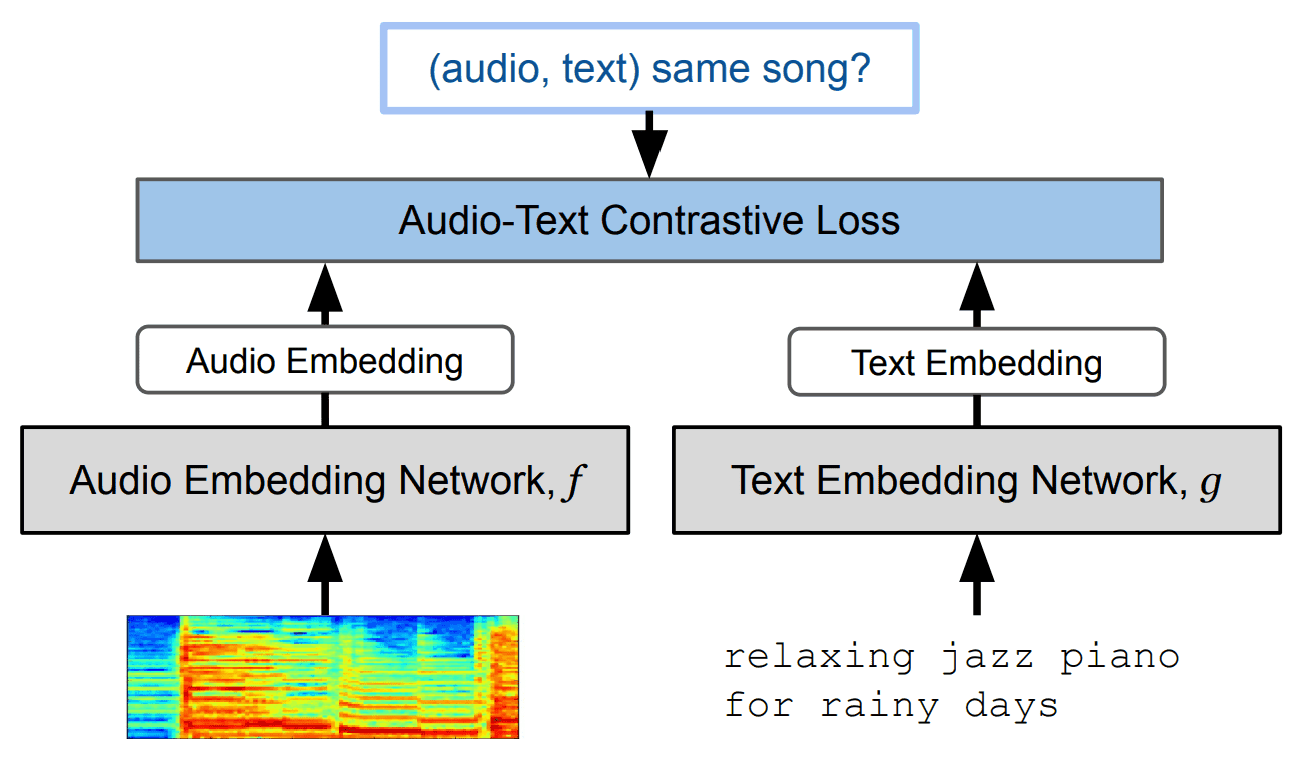
MuLan: A Joint Embedding of Music Audio and Natural Language
This model allows us to quantify the relevance and similarity between music and text. Incidentally, we use the following two encoders for music and text
- Music encoder: pre-trained Resnet-50 AudioSpectrogramTransformer (input: log-mel spectrogram)
- Text encoder: pre-trained BERT
In MusicLM, the main role is that of "encoder of text prompts".
Learning process
The components of the MusicLM are as we have seen. The learning process is as follows.

As you can see, no text prompts are needed for learning MusicLM. Here is what the A, S, and other symbols mean.
- MA: Token obtained by MuLan's music encoder
- S: token representing the "meaning of music" obtained by w2v-BERT
- A: Token representing the "voice" obtained by SoundStream
In addition, the study procedure is as follows
- Input music to be re-generated (Target Audio) into MuLan, w2v-BERT, and SoundStream respectively.
- Generate MA by MuLan music encoder
- Generate S with decoder-only Transformer subject to MA
- Generate A with decoder-only Transformer subject to MA and S
Furthermore, the A obtained in the above procedure and the "A obtained by inputting the input music into SoundStream" are learned to be close.
The study uses 5 million songs (280,000 hours of music data).
Reasoning process
When actually generating music in MusicLM, you enter a text prompt and run it through MuLan's text encoder. After that, the procedure is the same as in the previous study.
Experiment
In addition to MusicLM, the model evaluations in this study include comparative experiments with the following two music generation models
- Mubert.
- Riffusion
There are two points of focus in this experiment
- Music Quality
- Accuracy of text description
The following table shows the evaluation indicators and meanings used in this experiment.
| valuation index | meaning |
|---|---|
| FADTRILL (lower value is better) |
Index of sound quality evaluation considering human hearing (based on Trill2 trained on speech data) |
| FADVGG (the lower the value, the better) |
A measure of sound quality evaluation that takes into account human hearing (based on VGGish3 trained on YouTube audio data) |
| KLD (the lower the value, the better) |
Evaluate the consistency of the input text prompts with the generated music |
| MCC (the higher the value, the better) |
Calculate how similar "music" and "its text" are with Cosine Similarity by MuLan |
| WINS (the higher the value, the better) |
Number of "wins" in the pairwise test results (the higher the value, the better) |
The "WINS" above are the ratings obtained by the PAIRWISE TEST. This test was presented to the subject to evaluate the consistency between the "generated music" and the "textual description". The screenshot of the test presented to the subject is shown below.

For example, "Which song do you prefer?" You will be asked questions such as.
Data-set
To evaluate MusicLM, the authors have created and made publicly available a text-captioned music dataset called "MusicCaps," one of the achievements of this study. MusicCaps is available on the following Kaggle page and is freely available free of charge.
This data set contains 5.5k of music data. Each piece of music data is accompanied by a text describing the music. The text is written in English by 10 musicians. Examples of text captions are as follows

In the Text-to-Music studies that have emerged since MusicLM, these MusicCaps are often used as benchmarks to evaluate models.
Result
The results of the comparison experiment are shown in the table below.

The results show that MusicLM scored the highest in all indicators. Therefore, MusicLM was found to be higher than Mubert and Riffusion in both sound quality and consistency with text prompts.
Summary
This article introduced MusicLM, a Text-to-Music generation model developed by Google.
The credit for this research goes not only to the high quality music generation, but also to the creation of the MusicCaps dataset. Thanks to this dataset, we can expect further development in the field of Text-to-Music.
In addition, I think it was very interesting regarding the use of a contrastive learning model called MuLan to maintain consistency between the music and the text.
Incidentally, it seems that there are no plans to release MusicLM's model, probably due to copyright and plagiarism of works.



Categories related to this article





