
Teach Augment:通过使用教师模型来优化数据的扩充。
三个要点
✔️ 介绍对抗性数据增强的教师模型,并提出一种不需要仔细调整参数的数据增强策略Teach Augment
✔️ 提出一种使用神经网络进行数据增强的方法,将关于颜色的数据增强模型和关于几何变换的数据增强模型相结合。提出了一种使用神经网络进行数据增强的方法,该方法结合了关于颜色的数据增强模型和关于几何变换的数据增强模型
✔️ 证实了所提出的方法优于现有的数据增强搜索框架,包括用于图像分类和语义分割任务的最先进的方法,而无需为每个任务调整超级参数。
TeachAugment: Data Augmentation Optimization Using Teacher Knowledge
written by Teppei Suzuki
(Submitted on 25 Feb 2022 (v1), last revised 28 Mar 2022 (this version, v3))
Comments: CVPR2022
Subjects: Computer Vision and Pattern Recognition (cs.CV)
code:

本文所使用的图片要么来自论文、介绍性幻灯片,要么是参考这些图片制作的。
介绍
近年来,数据增强作为模型泛化的一个重要方法受到越来越多的关注。
作为这种数据增强的先导,AutoAugment已经被提出来,以自动搜索有效的增强方法来实现模型的泛化。
该方法基于一种对抗性策略,寻找能使目标模型的任务损失最大化的扩展方法,并且已知能提高模型的泛化。
然而,如图1左侧所示,在没有约束的情况下,对抗性数据增强会变得不稳定,因为损失最大化是通过折叠图像的内在意义实现的。
为了避免这种情况的发生,传统的方法是根据经验规则对增量进行规整,或者限制函数的大小参数在搜索空间的搜索范围,但问题是有很多参数需要调整。
为了解决这个问题,本文提出了一种使用教师知识的在线数据增强优化方法TeachAugment。
TeachAugment也是基于对抗性的数据增强,但如图1右侧所示,增强方法可以探索到转变后的图像对教师模型的可识别性。另外,与传统的对抗性数据增强不同,它不需要先验分布或超参数,从而避免了过度的增强方法,使图像的原始含义崩溃。
因此,Teach Augment不需要调整参数来确保转换后的图像是可识别的。
此外,本文提出了一种使用神经网络的数据增强方法,该方法有两个功能:对几何变换的数据增强和对颜色的数据增强。只需进行两次转换,这种方法就可以表示AutoAugment搜索空间中的大多数函数及其复合函数。
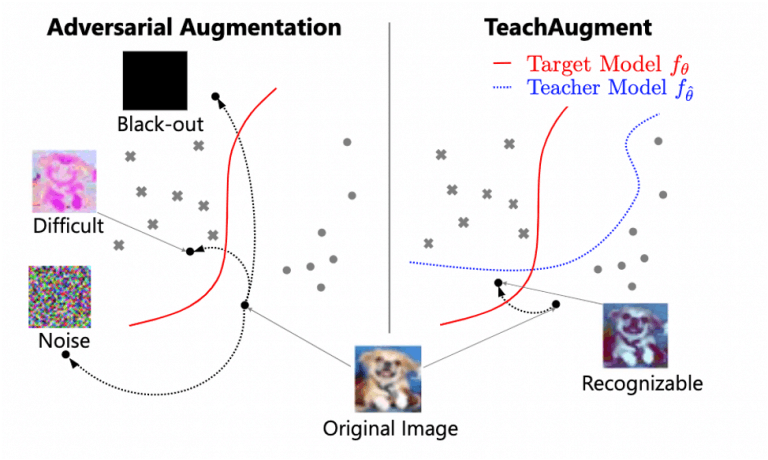
图1:传统方法和拟议方法之间的差异
对本文的贡献包括。
- 我们提出了一个基于使用教师知识的对抗性策略的在线数据增强优化框架,称为TeachAugment。
TeachAugment可以通过使用教师模型来确保图像的固有意义不被破坏,从而使对抗性数据增强策略在不仔细调整参数的情况下更加有利可图。 - 还提出了一种基于神经网络的数据增强方法。
该方法简化了搜索空间的设计,并允许通过TeachAugment梯度方法更新参数。 - TeachAugment显示,传统的方法,如在线数据增强和最先进的增强策略在分类、半整合和无监督表示学习任务中表现良好,而无需为每个任务调整超参数或搜索空间大小。
在接下来的章节中,在对数据增强和作为先验知识的对抗性进行简要描述后,将解释所提出的方法、实验细节和结果。
什么是数据扩展?
数据扩张是一种通过对图像进行某种变换来伪装增加数据数量的方法,如图2所示。
除了图2中显示的那些,还有无数其他类型的变换,比如擦除(Erasing),它可以填充图像的一部分,以及高斯模糊(GaussianBlur),它应用高斯滤波器。
众所周知,使用这些不同的扩展方法训练的模型比只在原始数据上训练的模型更具有普遍性,但有时它们会降低性能或引起意想不到的偏差。
因此,为了提高模型的泛化率,需要根据领域手动寻找有效的数据扩展方法。
图2:数据扩展概述。
建议的方法
本文提出了两种数据扩增策略:一种是名为Teach Augment的数据扩增策略,另一种是使用神经网络的数据扩增方法。
教导增援
在进入第一个提案--"教学扩增 "的描述之前,先对一般的学习和使用数据扩增的对抗性数据进行简要描述。
每个表达式中出现的字母定义如下。
- $X\sim `mathcal{X}$:从$mathcal{X}$采样的$图像。
- 以$a_\phi$:$\phi$为参数的数据扩展函数
- $phi$:神经网络参数
- $f_\theta$:目标模型
- $f_{hat{theta}}$:教师模型
具有数据增强功能的一般学习。
小批量样本$x$通过输入数据扩展函数$a_\phi$进行转换,然后输入到目标网络$f_{theta}$。($f_\theta\left(a_\phi(x)\right)$)
然后通过SGD更新目标模型的参数以使损失$L$最小化,使用以下公式
$min _\theta\mathbb{E}_{x\sim\mathcal{X}} L\left(f_\theta\left(a_\phi(x)\right)\right.$
敌意数据扩展
为了提高模型的通用性,对抗性数据扩展寻找使目标模型的损失最大化的参数$phi$,如下式所示。
L\left(f_\theta\left(a_phi(x)\right)\right.$ 最大 _\phi\min _\theta\mathbb{E}_{x\sim\mathcal{X}} L\left(f_\theta\left(a_phi(x)\right)
教导增援
正如介绍中提到的,在对抗性数据扩展中,与$phi$有关的最大化会导致图像本身的特征(意义)的损失,为了处理这样的问题,过去已经设置了正则化和限制搜索空间等约束。
然而,本文提出了一种数据扩展策略,通过使用监督模型来消除这种限制的需要。
根据以下公式的数据增强策略被称为TeachAugment。
$max _COPYphi min _theta (最大限度地提高了);$mathbb{E}_{x `sim\mathcal{X}}}\left[L\left(f_{theta}}\left(a_\phi(x))\right)-L\left(f_{hat{theta}}\left(a_\phi(x))\right)\right]$
如果转换后的图像与原始图像相差太远,则$L\left(f_{hat{\theta}}\left(a_\phi(x)\right)\right)$会变大,这对整个最大化问题有负面的影响,会阻止选择这种转换方法。
这个方程可以在SGD(随机梯度下降)中通过交替更新$a_\phi$和$f_\theta$进行求解,如图3所示。
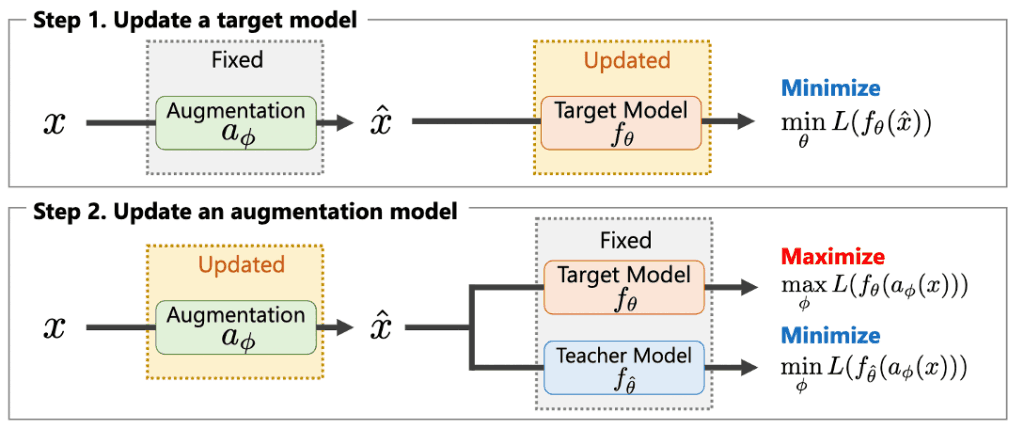
图3:参数更新算法。
另外,当目标模型的准确度非常高时,在最大化问题中,Teach Augment公式中第一项的梯度往往会相对于$phi$达到饱和。
为了防止这种情况,通常的损失函数是$sum_{k=1}^K-y_k\log f_\theta\left(a_\phi(x)\right)_k$与交叉熵,但这次$sum_{k=1}^K y_k\log \left(1-f_\theta\left(a_\phi(x)\right)_k\right)$ (非饱和损失)。
使用神经网路的数据增强。
第二项建议,即基于神经网络的数据扩展方法,被描述为。
在这里,数据扩展是通过一个神经网络$a_{phi_c}$进行的,它结合了用于颜色数据扩展的模型$c_{phi_c}$和用于几何变换数据扩展的模型$g_{phi_g}$。
每个表达式中出现的字母定义如下。
- $c_{phi_c}$:关于颜色的数据扩展的模型
- $g_{phi_g}$:几何变换的数据扩展模型。
- $a_\phi=g_{\phi_a}\circ c_{\phi_c}$:$c_{\phi_c}$ 和$g_{\phi_g}$ 组合神经网(c_{\phi_c}$ 和$g_{\phi_g}$ 的合成函数)。
- $phi={{phi_c,phi_g\}$:神经网络参数($phi_c$和$phi_g$的集合)。
- $x\in\mathbb{R}^{M\times 3}$:转换前的图像($M$对应于像素数,3对应于RGB。)
- $tilde{x}_i 处于[0,1]$:彩色扩展图像
- $alpha_i, \beta_i \in \mathbb{R}^3$: scale and shift parameters
- $z~\mathcal{N(0,I_N)}$:N维高斯分布,平均值为0,方差为I_N$。
- $c$:图像分类中的单次正确标签,其他任务中省略。
- $t(\dot)$:三角波($t(x)=\arccos (cos (x \pi)) / \pi$)。
- $A\in\mathbb{R}^{2\times 3}$:剩余参数
- $I\in \mathbb{R}^{2\times 3}$:单位矩阵
颜色的数据扩展由以下公式定义
$tilde{x}_i=t\left(\alpha_i \odot x_i+beta_i\right),\left(\alpha_i, \beta_i\right)=c_{phi_c}\left(x_i, z, c\right) $
模型$c_{phi_c}$,对颜色进行数据扩展,如果模型大小足够大,原则上可以将输入图像转化为任意图像,这是由于普遍近似定理的缘故。
然后,几何变换的数据扩展由以下公式定义
$hat{x}=operatorname{Affine}(tilde{x}, A+I), A=g_{phi_g}(z, c)$
其中$operatorname{Affine}(\tilde{x}, A+I)$表示$tilde{x}$以参数$A+I$进行仿生变换(翻译、缩放和旋转)。
实验装置
该方法在一个图像分类任务中进行了评估,以便与现有的数据增强方法探索进行比较。
WideResNet-40-2(WRN-40-2),WideResNet-28-10(WRN-28-10),Shake-Shake(26 2×96d),PyramidNet with ShakeDrop正则化和ResNet-50针对ImageNet进行了训练,其结果被用来评估该方法。
除了上述图像分类任务外,该方法还使用语义分割进行了评估。
对于语义分割,FCN-32s、PSPNet和Deeplabv3在Cityscapes上进行了训练。
结果和讨论
目标函数的评估
评估建议的目标函数的有效性(TeachAugment中介绍的公式)。
作为基线,我们将我们框架的目标函数替换为对抗性自动增强(Adv. AA)和点增强(PA)的损失进行比较。
为了确保公平的比较,除目标函数外,所有的实验都在相同的条件下进行。
每个条件下的错误率(%)结果显示在图4。
可以看出,Adv.AA的错误率比基线有所下降。
这大概是因为执行数据增强的模型产生了无法识别的图像,混淆了目标模型。
另外,在Adv.AA AA的情况下,搜索空间的大小需要仔细调整以保证收敛性,而建议的方法没有这样的限制。
经证实,所提出的方法能够取得比PointAugment更好的错误率,在三者中表现最好。
,而PointAugment使用动态参数来控制扩展数据的损失上限,所提出的方法没有这样的限制。
因此,我们认为所提出的方法比PointAugment实现了更多样化的转换,并改善了误差。

图4:目标函数评价结果
图像分类
为了证实该方法的有效性,我们将其与前面的方法AutoAugment(AA)、PBA、Fast AA、FasterAA、DADA、RandAugment(RandAug)、OnlineAug(OnlineAug)和Adv.
每个条件的错误率(%)结果显示在图5中。
我们观察到,除了Adv.AA,该方法取得了与其他方法相当的错误率,该方法在每个小批量中使用多个扩展样本。
特别是,ImageNet在不使用多种扩展方法的方法中取得了最低的错误率百分比。
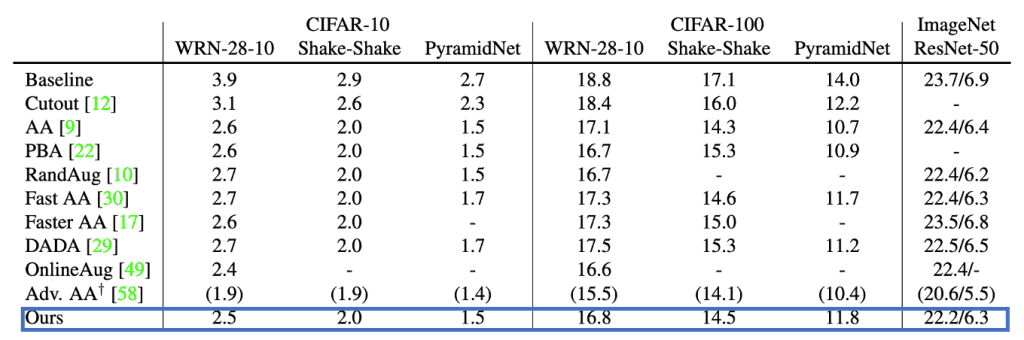 图5:图像分类任务的错误率
图5:图像分类任务的错误率
语义分割
该方法还使用Cityscapes进行了评估。
我们使用了广泛使用的模型:ResNet-101骨干网、FCN-32s、PSPNet和Deeplabv3。
RandAugment和TrivialAugment也被作为基线方法使用。
与提议的方法一样,这些方法也有一个特点,即它们的超参数很少,不需要仔细调整参数。
每个条件的mIoU结果显示在图5中。
可以看出,我们的方法对每个模型都实现了最佳的mIoU。
我们可以确认,RandAugment使FCN-32s的IoU恶化,TrivialAugment在任何模型中都不能改善mIoU。
事实上,以前的研究报告指出,TrivialAugment在图像分类以外的任务中表现不佳。
RandAugment和TrivialAugment的准确性差的原因是,这两个搜索空间不适合语义分割任务和模型容量人们认为,这是因为这两个搜索空间不适合于语义分割任务和模型容量。
然而,所提出的方法在所有条件下都改善了mIoU,而没有调整分类任务的任何参数,这证实了所提出的方法的有效性。
 图6:语义分割任务的mIoU结果。
图6:语义分割任务的mIoU结果。
摘要
本文提出了一种名为TeachAugment的在线数据增强优化方法,该方法在对抗性数据增强中引入了监督模型,并在不需要仔细调整参数的情况下进行更多信息的数据增强。
还提出了一种使用神经网络的数据增强方法,该方法将颜色上的数据增强模型与几何变换上的数据增强模型相结合。
实验证实,该框架的性能优于现有的数据增强和搜索框架,包括最先进的方法,用于图像分类和语义分割任务,而无需为每个任务调整超参数。



与本文相关的类别






