![[MusicLM]谷歌开发的文本到音乐生成模型。](https://aisholar.s3.ap-northeast-1.amazonaws.com/media/October2023/musiclm.png)
[MusicLM]谷歌开发的文本到音乐生成模型。
三个要点
✔️ 根据文字提示生成高质量音乐
✔️ 一个汇集了谷歌积累的智慧的项目
✔️ MusicCaps,一个配对的文字和音乐数据集
MusicLM: Generating Music From Text
writtenby Andrea Agostinelli, Timo I. Denk, Zalán Borsos, Jesse Engel, Mauro Verzetti, Antoine Caillon, Qingqing Huang, Aren Jansen, Adam Roberts, Marco Tagliasacchi, Matt Sharifi, Neil Zeghidour, Christian Frank
(Submitted on 26 Jan 2023)
Comments: Supplementary material at this https URL and this https URL
Subjects: Sound (cs.SD); Machine Learning (cs.LG); Audio and Speech Processing (eess.AS)
code:
本文所使用的图片要么来自论文、介绍性幻灯片,要么是参考这些图片制作的。
介绍
在这项研究中,开发了由谷歌发布的文本到音乐生成人工智能 MusicLM。例如,在该模型中,给出以下文字提示。
音乐节奏明快、欢快,电吉他旋律朗朗上口。音乐重复性强,容易记忆,但也有意想不到的声音,如钹的碰撞声或鼓的滚动声。
MusicLM 将此类文本作为输入,并根据文本生成音乐。它甚至可以生成特定的文本,如上面的文本,这一点非常吸引人。MusicLM 生成的实际音乐可在下一页中听到。
质量非常高。
能够产生如此高质量音乐的秘诀在于谷歌过去的研究积累,作为世界上最大的公司之一,谷歌自然产生了大量的研究成果。
在本研究中,我们充分利用了这些研究的成果。下面我们就来看看我们使用了哪些研究成果。
技术
让我们通过回顾谷歌之前的研究来了解一下本研究的模型结构。
部件
MusicLM 模式的组成部分包括

从左至右:"SoundStream"、"w2v-BERT "和 "MuLan"。这三个原本是独立的预训练模型,用于表达学习。如下图所示,上述三者组合在一起生成音乐� 
上图右下角的文字 "有小提琴独奏的嘻哈歌曲 "就是提示,上方的波形 "生成音频 "就是生成的音乐。
有各种符号,如 A 和 S,将在下面的章节中详细说明。首先,让我们依次查看每个组件。
・声音流
SoundStream 是一种用于压缩音频数据的 "神经编解码器"。该技术由两部分组成:"编码器 "将语音和音乐转换成非常小的信息块,而 "解码器 "则将小信息转换回原始语音和音乐。

在 SoundStream 中,"输入波形 "和 "解码器输出的波形 "经过端对端训练后是相等的。推理器将经过编码器和 RVQ 压缩的数据发送到接收器,接收器将接收到的数据通过解码器输出为音频。
SoundStream 的主要优势在于,即使数据量很低,它也能提供高质量的语音。例如,如果在通话过程中网络连接不稳定,SoundStream 可以自动调整数据量以保持通话质量。
MusicLM 主要负责 "生成音频的输出",而 SoundStream 可以高效地输出高质量音频。
・w2v-BERT
w2v-BERT 是 "语音识别系统的基础模型",用于从语音中提取含义。w2v-BERT 由谷歌开发,结合了 "语音理解技术 "和 "句子理解技术"、此外,它还结合了对比学习和多层多义性。
模型结构如下

W2v-BERT:结合对比学习和掩码语言建模进行自我监督语音预训练
w2v-BERT 由三个模块组成
- 特征编码器:压缩输入语音并输出潜在表示。
- 对比模块:通过对比学习了解 "言语前后语境"。
- 掩码预测模块:掩码估计也用于 BERT
这样,语音就能更准确地转换成语言意义,而在 MusicLM 中,语言意义主要是 "提示文本 "和 "输出音乐 "之间的联系。
・穆兰
MuLan 是一种 "对比学习模型",可将相关文本数据与音乐数据联系起来。这是谷歌的另一项研究,它是一个多模态模型,能将 "音乐 "与相关 "文本 "联系起来。它采用对比学习法,即学习音乐数据的嵌入和文本数据的嵌入之间的距离。
学习方法包括
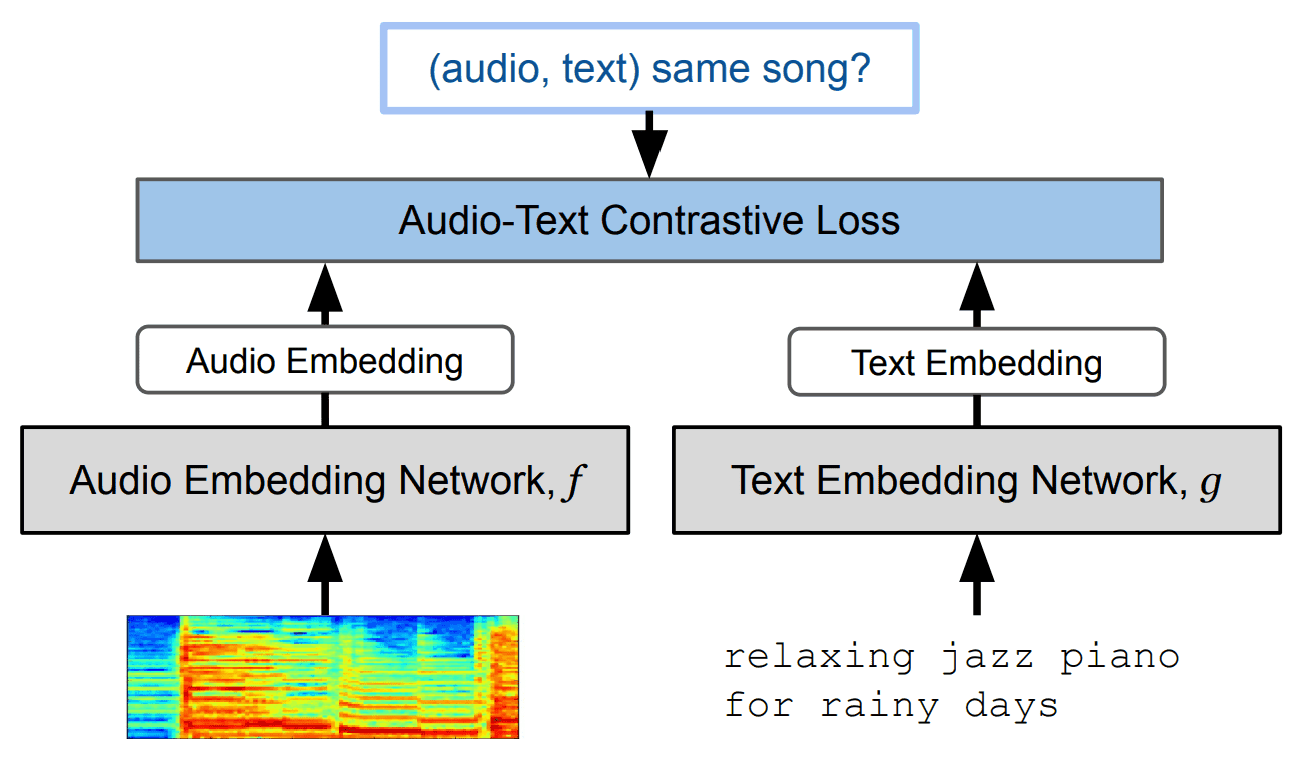
该模型可以量化音乐和文本之间的相关性和相似性。顺便提一下,我们使用了两种音乐和文本编码器
- 音乐编码器:预先训练好的 Resnet-50-AudioSpectrogramTransformer(输入:对数梅尔频谱图)。
- 文本编码器:预训练 BERT
在 MusicLM 中,它的主要角色是 "文本提示编码器"。
学习过程
我们研究了 MusicLM 的各个组成部分。学习方法如下

正如您所看到的,学习 MusicLM 时不需要文字提示。下面是 A 和 S 等符号的含义。
- MA:由沐兰音乐编码器获得的代币
- S:由 w2v-BERT 获得的代表 "音乐意义 "的标记
- A: 表示 SoundStream 获取的 "音频 "的标记
此外,研究程序如下。
- 将要再生的音乐(目标音频)分别输入到 MuLan、w2v-BERT 和 SoundStream 中。
- 由 MuLan 音乐编码器生成的 MA
- 使用仅解码器的变压器生成 S,受 MA限制
- 在 MA和 S 的限制下,用纯解码器变压器生成 A
此外,在上述过程中得到的 A 和 "将输入音乐输入 SoundStream 得到的 A "是相近的。
研究使用了 500 万首歌曲(28 万小时的音乐数据)。
推理过程
在 MusicLM 中实际生成音乐时,您需要输入文本提示并通过 MuLan 文本编码器运行。之后的操作步骤与之前的研究相同。
试验
除 MusicLM 外,本研究中的模型评估还涉及以下两种音乐生成模型的对比实验
- 穆伯特
- Riffusion
本实验的两个重点如下。
- 音乐质量
- 文字描述的准确性
本实验所使用的评价指标和含义如下表所示。
| 估值指数 | 内涵 |
|---|---|
| FADTRILL(数值越小越好)。 |
考虑到人类听力的音质评估指数(基于经过语音数据训练的 Trill2)。 |
| FADVGG(数值越小越好) |
人类听觉感知音质指标(基于在 YouTube 音频数据上训练的 VGGish3)。 |
| KLD (数值越小越好) |
评估输入文本提示和生成音乐之间的一致性。 |
| MCC(数值越大越好) |
用 MuLan 计算 "音乐 "和 "其文字 "的余弦相似度。 |
| WINS(数值越大越好)。 |
成对测试结果中 "胜出 "的次数(数值越大越好) |
上面的 "WINS "是通过 PAIRWISE 测试获得的评分。该测试的目的是评估 "生成的音乐 "与 "文字描述 "之间的一致性。向受试者展示的测试屏幕如下所示。

例如,"您喜欢哪首歌?就会被问到。
数据集
为了评估 MusicLM,作者创建并公开了一个名为 "MusicCaps "的文本字幕音乐数据集,这是本研究的成果之一。
该数据集包含 5.5k 个音乐数据。每段音乐数据都附有一段描述音乐的文字。文本由 10 位音乐家用英语撰写。文字说明示例包括

在 MusicLM 之后出现的文本到音乐研究中,这些 MusicCaps 经常被用作评估模型的基准。
结果
对比实验结果如下表所示。

结果表明,MusicLM 在所有指标中得分最高。因此,MusicLM 在音质和与文本提示的一致性方面均高于 Mubert 和 Riffusion。
摘要
本文介绍了由谷歌开发的文本到音乐生成模型 MusicLM。
这项研究不仅归功于高质量的音乐生成,还归功于 MusicCaps 数据集的创建。有了这个数据集,我们可以期待文本到音乐领域的进一步发展。
此外,我认为使用一种名为 "MuLan "的对比学习模型来保持音乐和文本之间的一致性也非常有趣。
顺便提一下,似乎没有出版 MusicLM 模型的计划,可能是因为版权和剽窃的问题。



与本文相关的类别





